1.损失函数
上一篇文章简单介绍了集成学习和弱学习器的理论概率,最后给出了AdaBoost的伪代码与实现步骤,思路比较清晰,这篇文章主要针对分类器的重要性α与分布权重Dt的更新规则进行推导.推导之前先看一下常见的损失函数(损失函数在SVM(3)里介绍过,这里只给出损失函数形式):



损失函数(loss function)用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型就更鲁棒。
2.AdabBoost的损失函数
AdaBoost算法有多种推导方式,最常见的是基于‘加性模型’,即基学习器的线性加权:
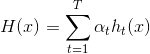
最小化损失函数(指数损失):
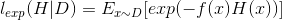
其中f(x)为真实值,H(x)为真实值,二者均为二值型(-1,1),若H(x)能令损失函数最小化,则考虑上式对H(x)的偏导:
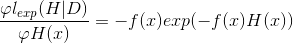

令导数为0,求解:
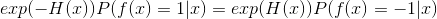
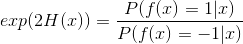
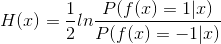
因此有:
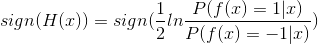
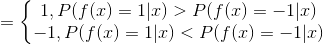
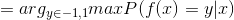
这意味着sign(H(x))达到了贝叶斯最优错误率,也就是说指数损失函数最小化时,分类错误率也将最小.
3.分类器重要性α更新规则
推导前先回顾一下算法的伪代码:

开始论证~在AdaBoost中,第一个分类器h1是通过基学习算法用于初始数据分不而得,此后迭代生成ht和αt,当基分类器ht基于Dt产生后,该基分类器权重αt应使得αtht最小化损失函数.
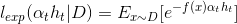
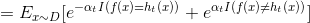
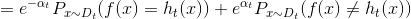
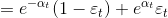
当前基学习器分类错误的概率:
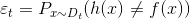
对损失函数求导:
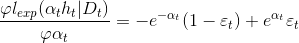
令导数为0得:
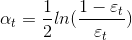
恰好对应伪代码的第六步.
4.样本权重Dt更新规则
AdaBoost在获得Ht-1之后样本分布将进行调整,增加分类错误样本的权数,减少分类正确样本的权数,使下一轮基学习器ht能够纠正Ht-1的一些错误,理想的ht能够纠正Ht-1的全部错误,即最小化:
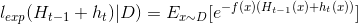
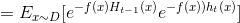
e^x在x=0处的泰勒展开:
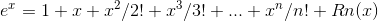
将损失函数中ht(x)部分泰勒展开得(此处忽略了余项):
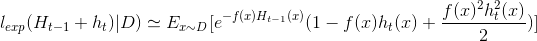
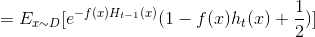
因为f(x),h(x) ∈ {-1,1}
此时理想的基学习器h(t)应满足:
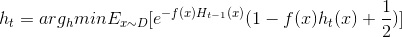

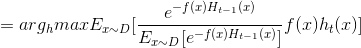
这里运用对偶将min转化为max,有点类似支持向量机求最优间隔的方法,而且在优化问题中加入常数不影响最终的结果.
这里Dt表示一个分布:
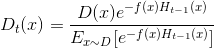
这里其实就大概了解了为什么要在更新Dt时下面引入zt去规范化分布.
根据数学期望定义,这里等价于:
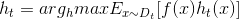
这里注意求期望的x范围不是D,而是Dt.
由于f(x),h(x) ∈ {-1,1}:
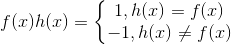
将上式整理为1个式子,这里I(x)为示性函数:
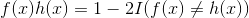
则理想的ht:
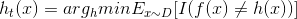
由此可见理想的ht是在分布Dt下最小化分类误差,因此,弱分类器基于Dt来训练,且错误率应1小于50%(伪代码第五步),考虑Dt与Dt+1的关系:
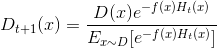
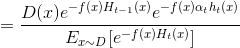
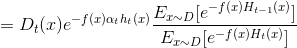
这里对应伪代码第七步的权值更新.
总结:
通过这两篇文章的理论推导,AdaBoost的大致过程已经比较清晰了,证明步骤基本都是参考西瓜书,只是对其中一小部分加了一些小的注解,有问题欢迎大家交流~下一节将就实例python编码看一下针对具体的数据,集成学习是如何一步一步更新权值缩小泛化误差的.