Collection接口
续 Java集合(二),对
Set接口的实现类分析
Set底层使用HashMap实现的,HashMap相关的内容可以看我的另一个博客Java集合(四)
Set接口
是Collection接口的子接口public interface Set<E> extends Collection<E>,除了Collection接口中的方法之外,Set没有额外的方法。用到的实现类有:
HashSetLinkedHashSetTreeSet
继承关系
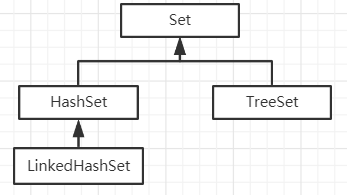
和List接口的实现类的区别:
- 首先
Set接口的实现类添加元素是无序不可重复的,和List实现类是相反的 - 二者的存储结构不完全相同,
List实现类用动态数组或者是链表,HashSet使用map结构
1.HashSet
最常使用的Set实现类
类继承关系
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
重要成员变量
private transient HashMap<E,Object> map;//可以看出HashSet底层是HashMap实现的
private static final Object PRESENT = new Object();//因为使用HashMap实现,使用这个PRESENT作为虚拟变量相当于<k,v>中的v,只是在set不会用到的
初始化
空参构造器
public HashSet() {
map = new HashMap<>();//默认的HashMap的容量是16,装载因子是0.75
}
根据现有的Collection集合初始化
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));//选取c的容量和默认16中大的作为新的HashMap的容量,保证能装下c中所有的元素
addAll(c);
}
专门实例化LinkedHashSet的构造方法
HashSet(int initialCapacity, float loadFactor, boolean dummy) {//初始容量,装载因子还有一个布尔参数用来区分
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
元素插入
按 Hash 算法来存储集合中的元素,有很好的存取、查找、删除性能
元素插入的过程:
- 首先调用待插入元素的
hashCode()函数,根据计算得到的哈希值经过一定的算术运算,得到存放的index值 - 如果
index处没有元素,那么插入成功- 如果
index处有元素,那么遍历index为头结点的链表,如果和他们这些节点的哈希值都不同那么插入到链表末端 - 如果这个过程中遇到一个节点和待插入元素的哈希值相同,使用
equals()方法比较这个节点的元素和待插入元素,如果也是相等的,那么待插入元素就是在Set中存在了,不能重复,插入失败了 - 如果两者
equals()判别不相同,那么不是同一个元素,插入成功(两个元素的哈希值相等是两个元素相等的必要非充分条件,也就是说两个元素相等哈希值一定相等,但是两者的哈希值相等并不代表两者相等——所以元素对应的自定义类一定要重写hashCode()和equals()方法)
- 如果
public boolean add(E e) {
return map.put(e, PRESENT)==null;//使用的就是hashmap的插入方法,涉及hashmap看我的另一篇博客,见顶部
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);//见hashmap使用
}
看着看着哈希值有点晕,看看源码怎么计算哈希的,那么来了!
首先我定义了一个非常简单的类,只有两个成员变量:String name和int age,使用IDE重写了hashCode()函数如下:
@Override
public int hashCode() {
return Objects.hash(age, name);
}
//然后看调用的hash()方法
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
//用来计算哈希值的每个数组元素都会使用调用hashCode()计算出来的值加上 31 * result ,这样不断地循环遍历,因子的系数越大,这样计算出来的哈希值就“离的”越远,减少了冲突
//还有31 只需要5为二进制表示,空间占用比较小
//31 = 2 << 5 - 1,计算还效率高,你看看
//31还是一个素数,a * 31 的结构只能被 a,1,31整除,减少了冲突
return result;
}
public native int hashCode();//哟吼,这里还调用了native方法,以后再说,理解为调用了别的语言写的方法
遍历
- 没什么好说的,
Collection的子类,遍历参考List; - 但是注意,插入顺序可不一定是输出顺序,因为插入是通过哈希值计算
index插入到动态数组中的,位置和插入顺序没有必然联系
2.LinkedSet
继承关系:是HashSet的子类
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable
LinkedHashSet底层根据元素的 hashCode 值来决定元素的存储位置,不同的是,但它同时使用双向链表维护元素的次序,这使得元素看起来是以插入顺序保存的;所以由于HashSet是无序的,有时为了使哈希表在某种需求需要有序时,就会用HashSet的子类LinkedHashSet。- 也是不允许重复元素的
- 插入性能略低于
HashSet,但在遍历Set里的全部元素时有很好的性能。
2.TreeSet
在Set实现类中有序的
下面的内容结合我的另一篇博客比较器的内容(Java基础——比较器应用)来看,效果更佳
继承结构:
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
在TreeSet使用过程中用到的实现类就是TreeMap;底层实现不是哈希机制了,hashCode()方法不需要重写了
重要成员变量
private transient NavigableMap<E,Object> m;//实际上是由NavigableMap实现类TreeMap实现的
初始化
默认初始化:
public TreeSet() {
this(new TreeMap<E,Object>());
}
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeMap() {//默认初始化,comparator为null,遵循自然排序
comparator = null;
}
这里看出:不定义
comparator参数的默认TreeSet使用的是自然排序,所以想要添加到TreeSet中的对象必须实现comparable接口
带参初始化
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));//根据传入的参数comparator进行自定义排序
}
添加元素
public boolean add(E e) {
return m.put(e, PRESENT)==null;//实际调用的是TreeMap的put方法,底层使用红黑树完成存储
}
两种排序:
默认自然排序下的TreeSet
TreeSet会调用待插入元素的compareTo(Object obj)方法来比较对象之间的大小关系,然后将集合元素按升序排列 ——只能插入同种类型的对象 ,这样才能比较- 添加对象时,只有第一个元素不用调用
compareTo()方法,后面添加的所有元素都会调用compareTo()方法进行比较——注意,这里和HashSet中插入过程不太一样,不是用equals()方法判断相等,唯一标准就是compareTo()方法,但是通常也要保证compareTo()和equals()方法返回结果一样,这样不会有误解。
自定义排序
- 需要将实现了
Comparato接口的实例传参到构造器 - 也是只能插入同种类型的变量
- 调用
compare(T t1,T t2)比较大小
举例
定义了一个实现了Comparable接口的类
class Student implements Comparable{
String name;
int number;
int score;
public Student() {
}
public Student(String name, int number,int score) {
this.name = name;
this.number = number;
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", number=" + number +
", score=" + score +
'}';
}
@Override
public int compareTo(Object o) {
if(o instanceof Student){
Student stmp = (Student)o;
if(this.number > ((Student) o).number)
return 1;
else if(this.number < ((Student) o).number)
return -1;
else
return 0;
}
throw new RuntimeException("类型不匹配");
}
}
测试:
1.默认的自然排序
public static void main(String[] args) {
//可以看到定义了四个对象,其中s1和s2中number变量是相同的,正是comparaTo()方法重写时用于比较的字段
TreeSet<Student> treeSet = new TreeSet<>();
Student s1 = new Student("Student1",1 ,69);
Student s2 = new Student("Student2",1 ,69);
Student s3 = new Student("Student3",2 ,85);
Student s4 = new Student("Student4",3 ,60);
//添加顺序是3,2,1,4,观察最后的输出
treeSet.addAll(Arrays.asList(s3,s2,s1,s4));
for(Student s : treeSet)
System.out.println(s);
}
输出结果
可以看到是s1和s2有相同的number值,经过compareTo()方法比较之后相同,就s1就插入失败了,同时也按照number的升序排好了
Student{name='Student2', number=1, score=69}
Student{name='Student3', number=2, score=85}
Student{name='Student4', number=3, score=60}
Process finished with exit code 0
2.自定义排序
public static void main(String[] args) {
//匿名类传入Comparator类的实例,自定义了排序规则
TreeSet<Student> treeSet = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
if(o1.score > o2.score)
return 1;
if(o1.score < o2.score)
return -1;
else
return 0;
}
});
Student s1 = new Student("Student1",1 ,69);
Student s2 = new Student("Student2",1 ,70);
Student s3 = new Student("Student3",2 ,85);
Student s4 = new Student("Student4",3 ,60);
treeSet.addAll(Arrays.asList(s3,s2,s1,s4));
for(Student s : treeSet)
System.out.println(s);
}
结果:
可以看到虽然s1和s2的number值相同,但是这时候比较的规则已经不是重写的compareTo()方法了,而是在初始化TreeSet的时候传入的参数Comparator了,所以只要score不同就能正常插入,并且按照score顺序排列
Student{name='Student4', number=3, score=60}
Student{name='Student1', number=1, score=69}
Student{name='Student2', number=1, score=70}
Student{name='Student3', number=2, score=85}
Process finished with exit code 0
