1、基础排序算子sortBy和sortByKey
在Spark中存在两种对RDD进行排序的函数,分别是 sortBy和sortByKey函数。sortBy是对标准的RDD进行排序,它是从Spark0.9.0之后才引入的。而sortByKey函数是对PairRDD进行排序,也就是有Key和Value的RDD。下面将分别对这两个函数的实现以及使用进行说明。
1.1 sortBy
sortBy是在RDD下的
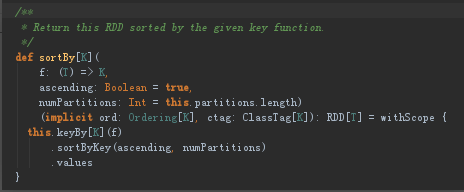
该函数最多可以传三个参数: 第一个参数是一个函数,该函数的也有一个带T泛型的参数,返回类型和RDD中元素的类型是一致的; 第二个参数是ascending,这参数决定排序后RDD中的元素是升序还是降序,默认是true,也就是升序; 第三个参数是numPartitions,该参数决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的个数相等,即为this.partitions.size。

从sortBy函数的实现可以看出,第一个参数是必须传入的,而后面的两个参数可以不传入。而且sortBy函数函数的实现依赖于sortByKey函数,关于sortByKey函数后面会进行说明。keyBy函数也是RDD类中进行实现的,它的主要作用就是将传进来的每个元素作用于f(x)中,并返回tuples类型的元素,也就变成了Key-Value类型的RDD了
1.2 sortByKey
sortByKey是在OrderedRDDFunctions类下的。sortByKey函数作用于Key-Value形式的RDD,并对Key进行排序

该函数返回的RDD一定是ShuffledRDD类型的,因为对源RDD进行排序,必须进行Shuffle操作,而Shuffle操作的结果RDD就是ShuffledRDD。其实这个函数的实现很优雅,里面用到了RangePartitioner,它可以使得相应的范围Key数据分到同一个partition中,然后内部用到了mapPartitions对每个partition中的数据进行排序,而每个partition中数据的排序用到了标准的sort机制,避免了大量数据的shuffle。
在转换调用sortByKey方法时,会从上下文中提取Ordering[K],private val ordering = implicitly[Ordering[K]]其中implicit def rddToOrderedRDDFunctions[K : Ordering : ClassTag, V: ClassTag](rdd: RDD[(K, V)])这里的k:Ordering意思是指k必须是可以转换成ordering的子类。下面有2种方式
//1、定义K的排序时使用隐式值
implicit val ord: Ordering[Person] = new Ordering[Person] {
override def compare(x: Person, y: Person): Int = {
x.name.compareTo(y.name)
}}
sc.textFile("").foreachRDD(rdd => rdd.map(msg => (Person(msg), msg)).sortByKey())
//2、key类实现Ordered[k]接口中的compare方法
case class Person(name:String) extends Ordered[Person]{
override def compare(that: Person): Int = {
this.name.compare(that.name)
}
def run(): Unit ={
println("Person...")
}
}
sc.textFile("").foreachRDD(rdd => rdd.map(msg => (Person(msg), msg)).sortByKey())
2、二次排序
二次排序就是指排序的时候考虑2个维度。如我们排序的时候按照第一个列降序排序,有一种情况,第一列的Key相同怎么排,这个时候可能就需要借助二次排序考虑第二列。
比较明智的方法是自定义排序的key,不采用其他的方式是因为现在二次排序,后面可能3次,5次等,采用自定义key的方式只要重新复写自定义的key,就能用sortByKey。
spark要实现比较,就要实现Orderd这个排序的接口,另外一般也会序列化Serializable。sortByKey会根据Key进行排序,但是如果二次排序的话sortByKey不知道key是什么构建的想法就是,基于已有的数据自定义二次排序的key,sortByKey基于这个自定义的key进行比较。我们用mapToPair重新构造内容,加了自定义的key,value的内容就是已有的内容,根据排序然后把自定义的key去掉。
package com.quinto.sort
/**
* 自定义二次排序的key
*/
class SecondarySortKey(val first:Int,val second:Int) extends Ordered[SecondarySortKey] with Serializable {
override def compare(that: SecondarySortKey): Int = {
if(this.first - that.first!=0){
this.first - that.first
}else{
this.second - that.second
}
}
}package com.quinto.sort
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SecondarySortApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SecondarySort").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\test\\a.txt")
val sorted = lines.map(lines=> ( new SecondarySortKey(lines.split(" ")(0).toInt,lines.split(" ")(1).toInt),lines))
sorted.sortByKey(false).map(line => line._2).collect().foreach(println)
}
}3、TopN
3.1 基础TopN
排序后直接使用take算子取出前几个,take算子后返回的是数组,不是rdd,不能用collect。
package com.quinto.sort
import org.apache.spark.{SparkConf, SparkContext}
object BasicYopNApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("BasicYopNApp").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\test\\a.txt")
//①生成k-v键值对方便sortByKey进行排序(Int已经实现了排序比较的接口)②降序排序③过滤出排序内容本身⑤获取排名前5放入元素内容,元素内容构成一个Array
lines.map(line=>(line.toInt,line)).sortByKey(false).map(line=>line._2).take(5).foreach(println)
}
}3.2 分组TopN
分组排序就是有不同类型的数据,不同数据中每一种类型数据里面的TopN。
object GroupSortTopN {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${GroupSortTopN.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:/E:/data/test.txt")
//按照科目进行排序
val course2Info:RDD[(String, String)] = lines.map(line => {
val spaceIndex = line.indexOf(" ")
val course = line.substring(0, spaceIndex)
val info = line.substring(spaceIndex + 1)
(course, info)
})
//按照科目排序,指的是科目内排序,不是科目间的排序,所以需要把每个科目的信息汇总
val course2Infos:RDD[(String, Iterable[String])] = course2Info.groupByKey()//按照key进行分组
//分组内的排序
val sorted:RDD[(String, mutable.TreeSet[String])] = course2Infos.map{case (course, infos) => {
val topN = mutable.TreeSet[String]()(new Ordering[String](){
override def compare(x: String, y: String) = {
val xScore = x.split("\\s+")(1)
val yScore = y.split("\\s+")(1)
yScore.compareTo(xScore)
}
})
for(info <- infos) {
topN.add(info)
}
(course, topN.take(5))
}}
sorted.foreach(println)
sc.stop()
}
}3.3 优化分组TopN
上述在编码过程当中使用groupByKey,我们说着这个算子的性能很差,因为没有本地预聚合,所以应该在开发过程当中尽量避免使用,能用其它代替就代替。使用combineByKey模拟
object GroupSortByCombineByKeyTopN {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${GroupSortByCombineByKeyTopN.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:/E:/data/test.txt")
//按照科目进行排序
val course2Info:RDD[(String, String)] = lines.map(line => {
val spaceIndex = line.indexOf(" ")
val course = line.substring(0, spaceIndex)
val info = line.substring(spaceIndex + 1)
(course, info)
})
//按照科目排序,指的是科目内排序,不是科目间的排序,所以需要把每个科目的信息汇总
val sorted= course2Info.combineByKey(createCombiner, mergeValue, mergeCombiners)
sorted.foreach(println)
sc.stop()
}
def createCombiner(info:String): mutable.TreeSet[String] = {
val ts = new mutable.TreeSet[String]()(new Ordering[String](){
override def compare(x: String, y: String) = {
val xScore = x.split("\\s+")(1)
val yScore = y.split("\\s+")(1)
yScore.compareTo(xScore)
}
})
ts.add(info)
ts
}
def mergeValue(ab:mutable.TreeSet[String], info:String): mutable.TreeSet[String] = {
ab.add(info)
if(ab.size > 5) {
ab.take(5)
} else {
ab
}
}
def mergeCombiners(ab:mutable.TreeSet[String], ab1: mutable.TreeSet[String]): mutable.TreeSet[String] = {
for (info <- ab1) {
ab.add(info)
}
if(ab.size > 5) {
ab.take(5)
} else {
ab
}
}
}