目录
Python基础(十)--文件相关
1 读写文件
1.1 获取文件对象
在操作系统中,一个text文档,一张图片,一首音乐,这些都是文件。文件会以其固有的格式保存在硬盘中。文件可以分为两种类型:①文本文件:文本文件由若干可识别的字符组成,并且不能包含非文本字符之外的内容(图片等),如,.txt,.bat都是文本文件,而.doc,.pdf则不是文本文件②二进制文件:由可识别的字符组成,如果我们用文本编辑器打开二进制文件,往往看到的都是一堆乱码。
底层的角度来说,一切都是二进制格式的,文本文件,也是二进制文件的一种,只是其内容,是我们能够识别的字符而已。
在Python中,可以通过open函数返回文件对象。文件对象是一个泛指,可以表示文件,也可以表示文件夹(路径)。格式为:open(file, mode='r') file指定文件的路径(相对路径或绝对路径),mode指定打开文件的模式,如下表。当读入文件或者写入文件时,会涉及到文件指针。文件指针指向的就是下一次要读取或写入的字符(或字节)位置,随着读取或写入的进行,文件指针也会随之而移动。
| 模式 |
说明 |
| r(1) |
读模式(默认模式),用来读取文件内容。文件指针在文件的开头。文件需要事先存在,否则会产生异常。 |
| w(1) |
写模式,用来向文件写入数据。文件指针在文件的开头。如果文件存在,则覆盖文件,否则会创建文件。 |
| a(1) |
追加模式,用来向文件追加数据。文件指针在文件的末尾。如果文件存在,不会覆盖文件(追加写入),否则会创建文件。 |
| x(1) |
写模式,用来向文件写入数据。文件指针在文件的开头。如果文件不存在,创建文件,否则产生错误。 |
| t(2) |
文本(字符串)模式(默认模式),以文本形式操作文件。 |
| b(2) |
二进制(字节)模式,以二进制形式操作文件。 |
| U(3) |
通用换行符模式(已不建议使用)。在该模式下,\n,\r\n或\r都会解析为换行符。不能与w、a、x或+模式同时使用(仅限于读取文件时使用)。 |
| +(3) |
读取或写入。 |
上表的(1)(2)(3)模式中,不同组的模式可同时使用(除了与U不兼容的模式),例如rt,wb+等。同一组的模式同时使用,如rw,tb等。
当文件不再使用时,我们需要对文件进行关闭,从而断开与外部文件的连接。断开连接可以调用文件对象的close方法。
# open函数,参数1:文件路径,参数2:操作文件的模式,返回文件对象
# 以r(读取)模式操作文件时,文件必须存在,否则会产生FileNotFoundError
fr = open("E:/test/test.txt","r")
# 以w(写入)或a(追加)模式操作文件时,文件不存在,不报错而是创建文件
fw = open("E:/test/test1.txt","w")
fa = open("E:/test/test2.txt","a")
# 以x(写入)模式操作文件时,文件必须存在,否则会产生FileNotFoundError
fx = open("E:/test/test3.txt","w")
# 访问文件结束后,需要断开与文件的连接,直接调用close并不好,可能在close方法前产生异常
# finally方式关闭文件
try:
f = open("E:/test/test.txt", "r")
finally:
f.close()
# with处打开文件,可以保证在with结束后一定能够有效的关闭,无序显示调用close方法
# with中可以使用as来保存文件对象(获得文件兑现高的引用)
with open("E:/test/test.txt") as f:
pass1.2 文件读取
读取文件的几种方式如下:
| 方法 | 描述 |
| read(size=-1) | 读取并返回文件内容。size指定读取的大小。如果是文本模式,以字符为单位,如果是二进制模式,以字节为单位。如果size省略,或者为负数,则返回文件的全部内容。如果文件已经没有内容可读取,返回空串(""或b"") |
| readlline() | 返回文件的一行,保留末尾的换行符。如果没有内容可以读取,返回空串(""或b"")。 |
| readllines() | 返回一个列表,列表中的每个元素为文件的一行内容,每行保留末尾的换行符。 |
文件对象也是迭代器:如果文件过大,这会占据大量的内容空间。此时readlines不是一个好的选择。对于文件对象,其本身也是一个迭代器类型,我们可以使用for循环的方式对文件对象进行迭代,从而节省内存。
# 文件读写操作
with open("E:/test/test.txt","rt") as f:
# t模式以字符(文本)形式操作文件,b模式以字节(二进制)形式操作文件
# read读取文件的数据,参数指定读取的单位,如果参数缺失,或者为负值表示读取所有
# print(f.read(1))
# print(f.read())
pass
# 如果使用了t模式,要求操作文件的编码方式与目标文件的编码方式一致
# 如果没有显示指定编码方式,则使用平台的编码方式,可以使用encoding指定操作文件的编码方式
with open("E:/test/test.txt","rt",encoding="UTF-8") as f:
print(f.read())
# 读取文件的一行
while True:
line = f.readline()
if line:
print(line,end=" ")
else:
break
# 返回一个列表,列表中的元素为每一行的内容,保留换行符
# lines = f.readlines()
# for line in lines:
# print(line,end=" ")
# 文件是迭代器类类型,每个元素就是文件的一行
from collections.abc import Iterator
with open("E:/test/test.txt","rt",encoding="UTF-8") as f:
print(isinstance(f,Iterator))
for line in f:
print(line,end="")
1.3 文件写入
向文件写入的几种方式如下:
| 方法 | 描述 |
| write(content) | 将参数写入到文件中,返回写入的长度。如果是文本模式,以字符为单位,如果是二进制模式,以字节为单位 |
| writelines(lines) | 参数lines为列表类型,将列表中所有元素写入文件中 |
# 文件写入
with open("E:/test/a.txt","wt") as f:
f.write("写入")
# 向文件写入列表
f.writelines(["这是\n","列表\n"])
# b模式写入
with open("E:/test/a.txt","wb") as f:
f.write(b"abc")
# 文件复制
with open("E:/test/b.txt","rb") as f1,open("E:/test/a.txt","rb") as f2:
for line in f1:
f2.write(line)1.4 文件定位
通过文件对象的tell()和seek()方法可以获取或设置文件指针的位置
tell():返回文件指针的位置,即下一个要读取或写入的字符(字节)位置。以字节为单位。
seek(offset, whence): 改变文件的指针。offset指定新的索引位置偏移量。whence指定偏移量的参照位置:0:从文件头计算;1:从当前位置计算;2:从文件末尾计算
在文本模式下,如果whence的值不为0,则仅当offset的值为0时才是有效的。
# 文件定位
with open("E:/test/a.txt","rt",encoding="UTF-8") as f:
# 返回当前文件指针的位置,以字节为单位
print(f.tell())
f.read(2)
print(f.tell())
# 改变文件指针的位置,参数1:偏移量,参数2:参照物
# 在t模式下,如果第二个参数不为0,则只有第一个参数为0才支持,b模式无此限制
f.seek(3,0)
print(f.tell())
2 文件与路径的操作
2.1 os模块
os模块提供了很多操作目录与文件的功能,常用方法如下:
| 方法名 | 描述 |
| mkdir(path) | 创建path指定的目录。如果path所在的父目录不存在,或者path目录已经存在,都会产生异常 |
| makedirs(path,exist_ok=False) | 创建path指定的目录。如果path所在的父目录不存在,则会连同父目录一同创建。如果path目录已经存在,当exist_ok值为False,会产生异常,如果exist_ok值为True,则不会产生异常(默认值为False) |
| rmdir(path) | 删除path指定的空目录,但不会删除父目录。如果path目录不存在,或者该目录不为空,将会产生异常 |
| removedirs(path) | 删除path指定的空目录。如果父目录也为空,则会连同父目录一同删除(一直到根目录为止)。如果path不存在,或者该目录不为空,将会产生异常 |
| remove(path) | 删除path指定的文件。如果path不是一个文件,或者文件不存在,将会产生异常 |
| getcwd() | 返回当前的工作目录,即以脚本运行文件所在的目录 |
| chdir(path) | 改变当前的工作目录,工作目录由path指定 |
| rename(src,dst) | 重命名一个文件或目录。src指定源文件的路径,dst指定重命名后的文件路径。src与dest要求为同一目录 |
| renames(old,new) | 与rename相似,但是old与new指定的目录可以不同(此时类似于移动文件)。在方法执行时,会删除old路径中左侧所有的非空目录,并根据需要,创建new路径中不存在的目录。在Windows系统,old与new必须在同一盘符中 |
| listdir(path) | 获取path指定目录下所有的文件与子目录名(包括隐藏文件),以列表形式返回。列表元素的顺序是没有任何保证的。如果path为空,则默认为当前目录 |
| system() | 在shell中执行command指定的命令 |
| sep | 返回特定操作系统使用的分隔符 |
| name | 返回操作系统的名称。在Windows上返回nt,在Linux上返回posix |
| environ | 返回操作系统的环境变量 |
| linesep | 返回操作系统使用的换行符 |
| pathsep | 返回操作系统环境变量的分隔符 |
| curdir | 返回当前目录(.) |
| pardir | 返回上级目录(..) |
2.2 os.path模块
os.path模块提供了关于路径操作的相关功能,常用方法如下:
| 方法名 | 描述 |
| abspath(path) | 返回path的绝对路径 |
| basename(path) | 返回path的最后一个部分。即path中操作系统分隔符(/或\等)最后一次出现位置后面的内容。如果path以操作系统分隔符结尾,则返回空字符串 |
| commonpath(paths) | 参数paths为路径的序列,返回最长的公共子路径 |
| dirname(path) | 返回path的目录部分 |
| exists(path) | 判断路径是否存在,存在返回True,否则返回False |
| getatime(path) | 返回文件或目录的最后访问时间 |
| getmtime(path) | 返回文件或目录的最后修改时间 |
| getsize(path) | 返回文件的大小,以字节为单位 |
| isabs(path) | 判断path是否为绝对路径,是返回True,否则返回False |
| isdir(path) | 判断path是否为存在的目录,是返回True,否则返回False |
| isfile(path) | 判断path是否为存在的文件,是返回True,否则返回False |
| join(path,*paths) | 连接所有的path,以当前操作系统的分隔符分隔,并返回。空path(除了最后一个)将会丢弃。如果最后一个path为空,则以分隔符作为结尾。如果其中的一个path为绝对路径,则绝对路径之前的路径都会丢弃,从绝对路径处开始连接 |
| split(path) | 将path分割成一个元组,元组含有两个元素,第2个元素为path的最后一个部分,第一个元素为剩余之前的部分。(dirname与basename) |
2.3 shutil模块
shutil模块提供了高级操作文件的方式。通过该模块提供的功能,可以快捷方便的对文件或目录执行复制,移动等操作。常用方法如下:
| 方法名 | 描述 |
| copy(src,dst) | 复制文件,返回复制后的文件路径。src指定要复制的文件,如果dst是一个存在的目录,则将文件复制到该目录中,文件名与src指定的文件名一致,否则,将src复制到dst指定的路径中,文件名为dst中指定的文件名 |
| copy2(src,dst) | 与copy函数类似,但是copy函数不会保留文件的元信息,例如创建时间,最后修改时间等。copy2函数会尽可能保留文件的元信息 |
| copytree(src,dst) | 复制一个目录,目录中的文件与子目录也会递归实现复制,返回复制后的目录路径。src指定要复制的目录,dst指定复制后的目标目录,如果dst已经存在,则会产生异常 |
| rmtree(path) | 删除path指定的目录,目录中的子目录与文件也会一并删除 |
| move(src,path) | 将文件或目录移动到另外一个位置,src指定文件或目录的路径,当src为目录时,会将该目录下所有的文件与子目录一同移动(递归)。dst指定移动的目标文件或目录 |
使用copytree(src,dst)复制目录时,可以结合ignore_patterns函数对目录下的文件与子目录进行排除。如:shutil.copytree("abc", "def", ignore=shutil.ignore_patterns("*.txt"))ignore参数指定忽略的文件或目录,这样,所有名称以txt结尾的文件或目录将不会复制到目标目录中。
2.4 glob模块
glob模块提供列举目录下文件的方法,支持通配符*,?与[ ]。常用方法如下:
glob(pathname, *, recursive=False)
返回所有匹配pathname的文件与目录名称构成的列表,列表中元素的顺序是没有规律的。如果recursive值为True,则可以使用**匹配所有文件与目录,包括所有子目录中的文件与目录(递归)。
pathname中可以指定通配符:①*:匹配任意0个或多个字符②?:匹配任意1个字符③[]:匹配[]内的任意一个字符,支持使用“-”区间的表示。例如[0-9]则匹配0到9任何一个字符,[a-f]则匹配a-f之间的任何一个字符
iglob(pathname, *, recursive=False)与glob功能相同,只是返回一个迭代器而不是列表。
3 序列化
3.1 csv
CSV(Comma Separated Values),是一种存文本格式的文件,文件中各个元素值通常使用逗号(,)进行分隔,但这不是必须的,扩展名为.csv。可以使用csv模块来操作csv类型的文件。
# scv模块
import csv
# 写入csv文件,在写入的时候最好将newline设置为"",不然会产生空行
with open("E:/test/a.csv","wt",newline="") as f:
# writer函数返回一个写入器对象,能向参数指定的文件中写入数据
writer = csv.writer(f)
writer.writerow(["张三","18","男"])
writer.writerow(["李四","20","男"])
# 一次写入多行记录的话提供一个二维列表,每个一维列表就是一条记录
writer.writerows([["王五","25","男"],["赵六","30","男"]])
# 读取csv文件
with open("E:/test/a.csv","rt") as f:
# reader函数返回一个读取器对象(是可迭代对象),能够读取csv文件中的数据内容
reader = csv.reader(f)
for lines in reader:
print(lines)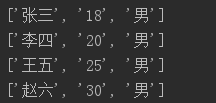
3.2 json
(1)什么是json
JSON(JavaScript Object Notation),是一种轻量级的数据交换格式。json采用的是一组键与值的映射,键与值之间使用“:”进行分隔,而键值对之间使用“,”进行分隔。json文件中的类型可以是:
| 类型 | 描述 |
| 对象类型 | 使用{}表示 |
| 数组类型 | 使用[]表示 |
| 字符串类型 | 使用双引号表示 |
| 布尔类型 | true或false |
| 数值类型 | 整数与浮点数 |
格式如下:
{
"desc": "json",
"data": {
"content": ["content1", "content2", "content3"],
"annotation": "注释"
}
}(2)dump与load处理程序,dumps与loads序列化与反序列化
可以通过json类型的数据进行对象的序列化与反序列化。
序列化:将对象类型转换成字符串的形式。
反序列化:将序列化的字符串恢复为对象类型。
通过序列化与反序列化,我们就可以方便的对复杂的对象进行存储与恢复(因为文件读写只支持字符串类型),或者通过网络进行传输,将对象共享给远程的其他程序使用。
# json文件提供不同项目之间的数据交换
import json
data = {
"desc": "json",
"data": {
"content": ["content1", "content2", "content3"],
"annotation": "注释"
}
}
with open("E:/test/a.json","wt") as f:
# 向文件中写入json格式数据,参数1:要写入的数据,参数2:文件对象
# json写入数据时,默认只显示ascii字符集的字符,非ascii字符集的字符需要转义
# 指定ensure_ascii=False可以显示,非ascii字符集的字符
json.dump(data,f,ensure_ascii=False)
with open("E:/test/a.json","rt") as f:
# 读取json数据,恢复成一个字典
data = json.load(f)
print(type(data))
print(data)
# 通过序列化与反序列化,可以实现不同项目之间的数据交换
# 序列化
d = json.dumps(data,ensure_ascii=False)
print(type(d))
print(d)
# 反序列化
d2 = json.loads(d)
print(type(d2))
print(d2)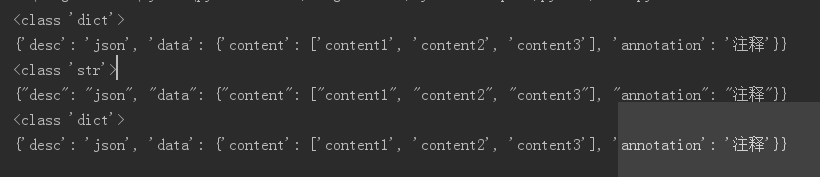
Python中的数据类型与json格式的数据类型并非完全相符,因此,在进行转换的时候,可能会进行一些映射处理,如下(json -> Python):
布尔类型(true与false)映射Python中布尔类型(True与False)。
空值类型(null)映射为None。
整数与浮点类型映射为整数(int)与(float)类型。
字符串类型映射为字符串(str)类型。
数组类型([])映射为列表(list)类型。
对象类型(object)映射为字典(dict)类型
# json文件提供不同项目之间的数据交换
import json
data = {
"布尔类型":False,
"空值类型":None,
"整数与浮":2,
"浮点类型":2.2,
"字符串类型":"a",
"数组类型":[1,2,3],
"对象类型":{"a":1,"b":2}
}
d = json.dumps(data,ensure_ascii=False)
print(d)
d2 = json.loads(d)
print(d2)

(3)自定义类型序列化
json在序列化时,不能序列化我们自定义的类型。如果我们需要自定义的类型也能够序列化,可以定义一个编码类,该类继承json.JSONEncoder,实现类中的default方法,指定序列化的方式,同时,在调用序列化方法时(dump或dumps),使用cls参数指定我们定义的编码类。
# 自定义类型序列化
import json
# 自定义的编码类继承json.JSONEncoder类型
class StudentEncoder(json.JSONEncoder):
# 实现default方法,给出序列化形式,参数o为序列化对象
def default(self, o):
if isinstance(o,Student):
# 将Student转换成可序列化对象
# return {"name":o.name,"age":o.age}
# 返回所有属性构成字典
return o.__dict__
else:
# 不是Student类型,调用父类的default翻翻产生错误信息
return super().default(0)
class Student:
def __init__(self,name,age):
self.name = name
self.age =age
s = Student("refuel",18)
print(s.__dict__)
# cls参数指定序列化需要用到的编码类
jsonstr = json.dumps(s,cls=StudentEncoder)
print(jsonstr)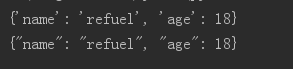
3.3 pickle
pickle模块也能序列化类型。在序列化自定义类型上,pickle可以比json模块更加方便(不需要定义类似的编码器类)。pickle与json在序列化上的区别如下:
| 序列化 |
json |
pickle |
| 序列化格式 |
文本格式,可进行正常查看。 |
二进制格式,不方便查看。 |
| 序列化类型的支持 |
支持一部分内建的类型,如果需要序列化自定义类型,需要编写编码类。 |
支持非常广泛的类型,包括自定义类型,不需要编写编码类。 |
| 适用广泛性 |
适用广泛,对于序列化的内容可以用于Python语言之外的程序中进行反序列化。 |
适用受限,只能用于Python程序中,其他语言的程序无法反序列化。 |
# pickle模块
import pickle
class Student:
def __init__(self,name,age):
self.name = name
self.age =age
s = Student("refuel",18)
# pickle序列化
with open("E:/test/a.pickle","wb") as f:
pickle.dump(s,f)
# pickle反序列化
with open("E:/test/a.pickle","rb") as f:
s2 = pickle.load(f)
print(s2.name)
print(s2.age)![]()
4 上下文管理器
4.1 自定义上下文管理器
with语句跟随的表达式会返回一个上下文管理器,该上下文管理器中定义相关方法,在with开始执行与退出时会调用,也就是说,上下文管理器为with提供一个执行环境。
__enter__(self):with语句体开始执行时,会调用该方法。可以在该方法中执行初始化操作,返回值会赋值给with语句中as后面的变量
__exit__(self, exc_type, exc_val, exc_tb):with语句体执行结束后,会调用该方法。我们在__enter__方法中执行的初始化,就可以在该方法中执行相关的清理,如,文件的关闭,线程锁的释等。实现finally语句同样的功能。exc_type:产生异常的类型;exc_val:产生异常类型的对象;exc_tb:traceback类型的对象,包含了异常产生位置的堆栈调用信息。如果在with语句体中没有产生异常,相关参数为None。
对于with,也可以关联两个上下文管理器,如:
with Manager1() as m1, Manager2 as m2:
语句
这相当于:
with Manager1() as m1:
with Manager2() as m2:
语句class MyManager:
def __enter__(self):
print("进入with语句体")
# return self
return "__enter__返回值赋值给as后变量"
def __exit__(self, exc_type, exc_val, exc_tb):
print("离线with语句体")
print(exc_type)
print(exc_val)
print(exc_tb)
with MyManager() as f:
# print(f)
raise Exception("with中存在异常")
4.2 @contextmanager装饰器
contextlib模块中,定义了@contextmanager装饰器,该装饰器可以用来修饰一个生成器,从而将生成器变成一个上下文管理器,从而可以省略编写完整的上下文管理器类。
在@contextmanager修饰的生成器中,yield之前的语句会在进入with语句体时执行(相当于__enter__方法),而yield之后的语句会在离开with语句体时执行(相当于__eixt__方法)。
with后的表达式会返回生成器对象(假设为gen_obj),进入with语句体时,内部会调用next函数,用来激活生成器对象,进而执行生成器的函数体next(gen_obj)
从而令生成器对象执行。yield产生的值则会赋值给with语句as后的变量(相当于__enter__方法的返回值)。
当with语句体结束时,如果with语句体没有产生异常,则继续调用next,令生成器从之前yield暂停的位置处继续执行(这相当于实现__exit__方法)。如果with语句体产生异常,该异常会在生成器函数体yield的位置抛出。而如果生成器函数体没有处理该异常,将会导致yield之后的语句不会得到执行,这相当于是没有成功的执行__exit__方法。
# @contextManager修饰一个生成器,装饰成上下文管理器
from contextlib import contextmanager
# yield之前的语句会在进入with环境时执行(相当于__enter__方法)
# yield产生的值赋值给as后面的变量(相当与__enter__方法的返回值)
# 离开with环境,执行yield之后的语句(相当于是__exit__方法)
@contextmanager
def f():
print("进入with环境")
# 如果with语句体中产生异常,该异常会传播到yield位置处,后面的语句不得到执行,
# 所以要使用try-finally操作.根据情况捕获,相当于实现了__exit__方法的返回值
try:
yield "产生的值赋值给as后面的变量"
except:
pass
finally:
print("离开with环境")
with f() as f:
# print(f)
raise Exception("异常")![]()
