下一章:cs224n学习笔记L2:word vectors and word senses
一、课堂内容
- 课程介绍
- 人类语言及词义
- word2vec介绍
- word2vec目标函数梯度
- 优化方法基础
- 词向量概览
二、课程介绍
主要介绍cs224n的教学团队时间安排、课堂资源等。
2.1 课堂资源
- 课程网页(课件资源):http://cs224n.stanford.edu、http://www.staford.edu/class/cs224n
2.2 教学目标
- 理解现代深度学习方法,深入介绍nlp常用的RNN、Atention等
- 了解自然语言理解及生成的难点
- 理解并能使用pytorch构建NLP处理的系统:词义理解(word meaning)、依赖解析、机器翻译、问答系统。
2.3 新加入内容
- 字模型、transformer、safety/fairness、多任务学习
- 五次单周课后作业,作业内容包括新知识点:使用attention实现NMT、CovNets、subword modeling。
2.4 作业说明
- HW1,一个IPython Notebook 文件
- HW2,纯Python代码,使用numpy库完成
- HW3,pytorch简介
- HW4 and HW5,pytorch-gpu
- 期末作业:默认为SQuAD 问答.
三、课堂内容
3.1 语言学及词汇
- 自然语言存在歧义、一词多义、语境等不确定因素的影响
- 词的离散向量表示:将词作为离散符号:onehot,词表示的向量正交,无法获得词之间的相似度。
- 词嵌入:使用词向量来表达。
3.2 词向量
- 优化问题:对于包含T个词的文本,使用大小为m的窗口,给定窗口中心词 ,有似然函数
- 目标函数是似然函数的平均负对数:
-
的计算方式:
- 对文本1-T中的每个词,设置两个向量,当 为中心词时使用 , 为context词时使用 。
- 若c为中心词,o为被预测的context, 有
,(V=vocabulary, 即语料中的所有词汇)这是一个特殊的softmax函数(softmax:将任意一组数值映射为概率)
这页PPT真是满满的精华呀。

课后作业
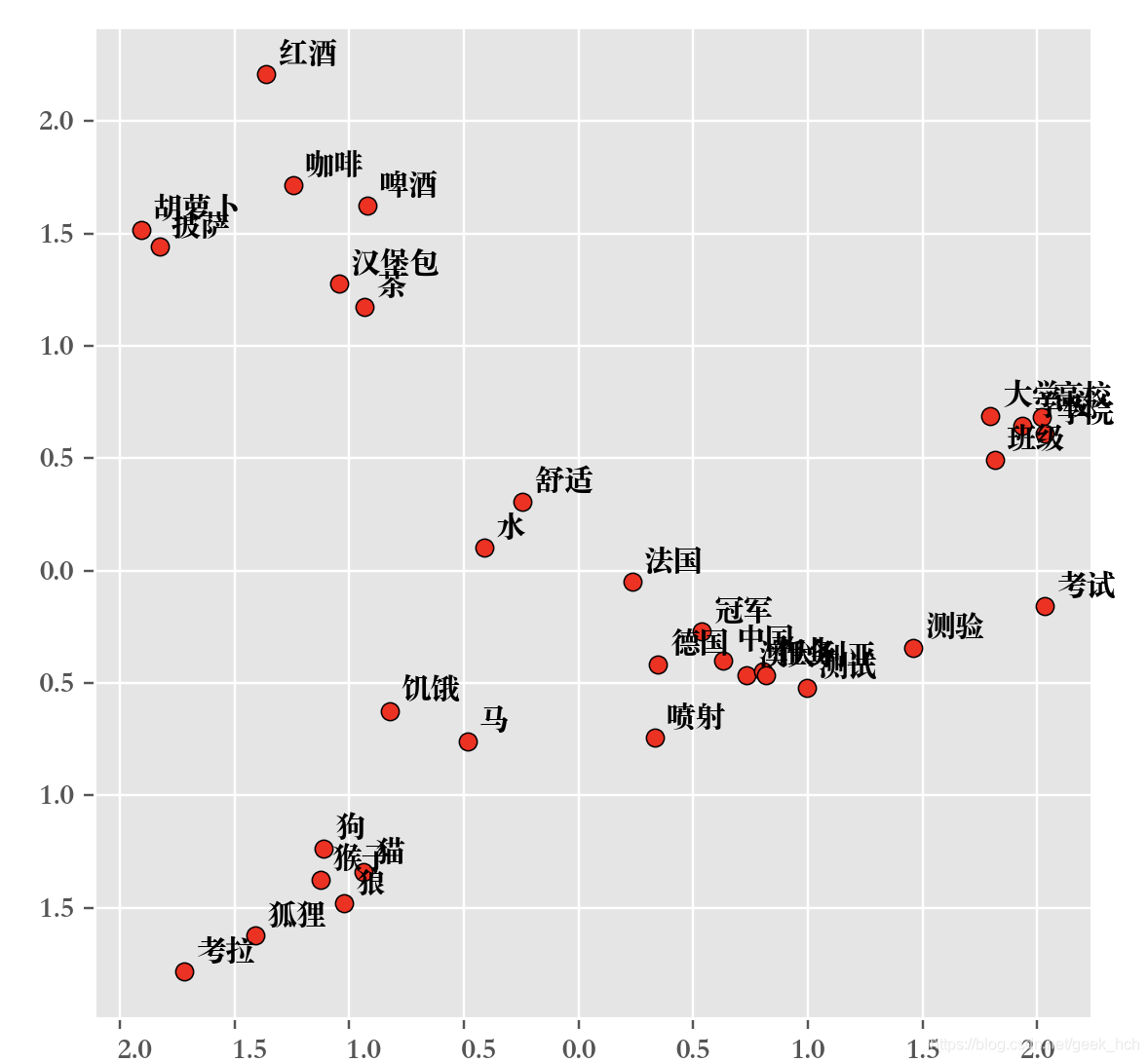
课后作业我使用网上公开的中文词向量,替换了课程的英文西向量。中文使用matplotlib画图时会无法正常显示,原因是matplotlib默认字体不支持中文,需要设置使用的字体,方法如下:
# 打印plt字体库,找到支持中文的字体
# from matplotlib import font_manager
# font_manager.fontManager.ttflist
plt.rcParams['font.sans-serif'] = ['Songti SC'] # 用来正常显示中文标签
display_pca_scatterplot(model, ['咖啡', '茶', '啤酒', '红酒', '喷射', '冠军', '水',
'汉堡包', '披萨', '舒适', '狗', '马', '猫', '胡萝卜',
'考拉', '狐狸', '猴子', '测验', '狼', '法国', '德国',
'饥饿', '澳大利亚', '中国', '作业', '任务', '考试', '测试',
'班级', '学校', '大学', '高校', '学院'])