密码分析学——深度分析WEP密钥恢复攻击(PTW攻击)
https://zhuanlan.zhihu.com/p/57677761 我是数学白痴..
几年前研究无线安全的时候曾经分析过WEP破解的原理,当时在网上搜索相关的中文资料时只能找到一些教你使用Aircrack-ng的脚本小子文章,要么纯粹就是胡扯一通,完全找不到靠谱的深入分析,最后只能去看当时的论文。
最近是因为要写书的缘故,需要重新总结一下无线安全相关的知识,到网上搜了一下发现结果多年过去了还是没有什么靠谱的中文资料,于是决定写一写总结一下破解的真正原理,来填补这个空白,希望可以帮到以后有兴趣研究WEP破解的人。
注意,WEP已经被淘汰了,现在新的路由器都不会支持WEP的加密方式,只会支持WPA/WPA2,WPA3也都已经出来了,所以花时间深入研究WEP性价比并不高,如果你只是为了破解邻居WIFI密码,或者学用Aircrack-ng的话可以ctrl + w了。
如果你是抱有学术情怀,想刨根问底那这篇文章会很适合你。WEP作为一个近年中被使用密码分析学完全破解掉的加密系统之一,实际上破解WEP的数学思路还是很值得学习的。
本文难度比较高,需要一定的无线协议基础、密码学基础、数学基础。
1 密码分析学
密码分析学与密码编码学共同组成了密码学这一学科,两者从几千年前诞生以来就开始了永无止境的较量,加密与破解是人类智力的精彩对决,对决的胜败甚至可以影响历史走向。
在第二次世界大战中,盟军破解了德国的密码从而得到了决定性的情报,让欧洲的战争提前了两年结束,这里也推荐大家一部纪录片“密码破译者:布莱切利庄园的幕后英雄”。
也许作为一个普通人,这辈子无法在密码学的历史上留下一点痕迹,但是了解密码的设计思路与破解的思路,也是一件极其具有乐趣的事情,正如Linus Torvalds所说的,Just For Fun。
2 WEP简介
由于无线网络的物理的特性,管理员是很难有效控制网络的覆盖范围的,攻击者可以在信号覆盖范围内窃听数据,或者进行未授权的访问,所以在使用无线网络时必须将数据加密和建立起身份认证机制,WEP就是用于保护无线网络的安全协议。
WEP(Wired Equivalent Privacy,有线等效加密)是1997年发布的第一版IEEE 802.11无线协议标准中的安全协议,目的是让无线网络提供像有线网络一样的数据机密性,所以叫做“有线等效”。
WEP中使用RC4流密码对数据加密,使用CRC-32校验数据的完整性,所有需要使用网络的人通过共享密钥来认证访问网络,不过WEP并没有提供前向安全性,一旦密钥泄露攻击者就可以访问网络,并解密所有之前捕获的流量。
WEP的密钥由24位初始化向量(IV)和根密钥(Rk)构成,格式为 。IV会在数据帧中明文传送,每个数据帧使用的IV都是不同的,IV可以是随机生成也可以是计数器式的递增,这是为了防止流密码的“重用密钥攻击”。实际上这种IV放在根密钥前面密钥格式,让我们的后续密钥恢复攻击变得更简单了。
WEP的第一版中由于受到美国政府对出口加密技术的限制,只允许使用64位的密钥,除去IV,剩下只有40位的根密钥可以由用户设置,称为(WEP-40),并不是非常安全。直到后来限制解除后,密钥长度增加到128位,可以用104位根密钥,被称为(WEP-104),后来也有供应商实现了256位的密钥,根密钥达到232位,不过最常见的还是128位的实现。理论上来讲更长的密钥可以提供更强的安全性,让攻击者更难穷举密钥,更难破解,但后面我们会发现更长的密钥对WEP安全性提高并没有帮助。
这里插一点题外话,由于密码学在第二次世界大战中巨大影响,二战后许多国家政府都对加密技术出口进行了监管。由于美国加密技术领先,到了1992年加密技术被列入美国军需物品清单,出口受到法律严格限制,强度超过一定程度的加密技术将禁止出口。如果让其他国家掌握了先进的加密技术将会影响美国对其他国家的监控,以及打击犯罪和恐怖主义的能力。例如Netscape推广SSL技术时受到政策影响需要开发两个版本的浏览器,美国版使用1024位的RSA公钥,以及128位的RC4或3DES,而国际版只能使用512位RSA和40位的RC4,但是由于监管两个版本非常麻烦,所有最终大部分美国人使用的也是削弱了的国际版,40位的密钥几天就可以被破解。在90年代末期,由于受到自由主义者和隐私权倡导者的挑战以及互联网发展监管难度提高,电子商务发展对加密技术的需求,美国政府最终对加密技术的出口管制放松,在1998年如果出口商品增加密钥恢复后门就允许出口56位密钥产品,在1999年去除了需要后门的限制,而在2000年将密钥长度限制的规定删除。
3 WEP密码破解历史过程
在WEP发布的4年后的2001年,Scott Fluhrer,Itsik Mantin和Adi Shamir首次提出了对RC4的密钥恢复攻击(FMS攻击),这种攻击利用特定易受攻击的IV(弱IV)来恢复密钥,弱IV会导致高概率泄露密钥信息。不过这种攻击并不高效,如果捕获不到使用弱IV的数据帧就需要等待,实际操作中需要捕获大约400万到600万个不同的帧才能恢复出密钥,破解一般需要几个小时。厂商为了应对这种攻击,修改了固件,过滤了特定的弱IV不使用。实际上这种攻击由于成本太高,并没有对WEP造成致命打击,WEP依旧被大范围使用,但是意识到WEP脆弱后已经有了重新设计安全协议的必要。
在2003年发布了WPA,也被称为IEEE 802.11i标准草案,用于作为淘汰WEP的过渡,WPA使用TKIP(临时密钥完整性协议),但是加密算法同样为RC4,这样兼容性会比较好,现有硬件通常只需要安装驱动程序或者更新固件就可以使用了。在2004年发布了全新的WPA2,这是完整版的IEEE 802.11i的标准,使用CCMP,这是基于AES的加密协议,提供了非常高的安全性。由于新设备的更换需要成本,新技术推广的时间永远比预想中要更长,所以即使WPA/WPA2出现多年之后,WEP依旧被广泛使用着。
在2004年,一个名为KoreK的人在2004年的netstumbler论坛上发布了一个WEP破解的实现,其中包含了对WEP的17种攻击,一部分攻击是已知的,一部分是KoreK自己发明的。使用KoreK攻击恢复WEP密钥所需要的帧数量大大减少,大概只需要50万到100万个数据帧,但是这对于普通的攻击者来说成本依然比较高,人们对于WEP安全性依然抱着一种掉以轻心的态度。
在2006年,Klein提出了两种针对RC4的攻击方法,证明了RC4密钥序列与内部状态的相关性,这种相关性足以恢复密钥,且不需要任何特定的弱IV,可以利用接收到的每一个数据帧,只需要4万到8万个会话就可以恢复出正确的密钥,但是Klein攻击有一个不足的地方就是需要大量的计算资源。
在2007年,Erik Tews,Ralf-Philipp Weinmann和Andrei Pyshkin(PTW攻击)将Klein攻击应用于WEP破解,并改进了Klein攻击需要大量计算资源的问题。如此有效又轻量的PTW攻击直接成了WEP协议生涯的分水岭,如果说以前攻击者破解WEP网络需要付出一定的时间成本,那PTW攻击几乎是没有成本,PTW攻击通常只需要不到60秒的时间就可以恢复出正确的密钥,而且由于不需要多少计算资源,攻击完全可以自动化,甚至可以实现在一些嵌入式设备上,完全可以走到哪破解到哪。值得注意的是,据作者调查,在PTW攻击发布前的2007年3月的德国城市中使用WEP无线网络依然占了46.3%。
PTW攻击是破解WEP密码最流行的攻击,在Aircrack-ng中破解WEP用的就是PTW攻击,Klein攻击和PTW攻击也是本章中我要分析的攻击方法。
你们以为PTW攻击就是现今破解WEP最强的攻击了吗?当然不是了,实际上在2010年Teramura等人提出了TeAM-OK攻击,只需要2万到5万个数据帧就可以恢复密钥,而在2011年Sepehrdad,Vaudenay和Vuagnoux提出了Tornado攻击,只需要4000到9000个数据帧就可以恢复密钥,不过这些攻击我就以后再给大家分析了。
国内有些中文资料说WEP密码破解是因为使用了重复的IV导致的,重复的IV确实可以导致一些攻击,例如前面所说的“重用密钥攻击”,但离恢复密钥还差了十万八千里呢。
4 流密码与伪随机数
流密码也叫序列密码,原理就是密码算法根据密钥产生密钥序列(也叫密钥流),然后以字节流的方式进行加密解密操作。
如图1,alice加密就是使用密钥序列与明文逐位XOR,得到密文,然后把密文发送到Bob,Bob解密只要使用同样的密钥序列对密文逐位XOR就可以变回明文了,非常简单。
如果信道上有窃听者Eve,由于只能获取到密文,无法获取加密序列,是不能解密出明文的。
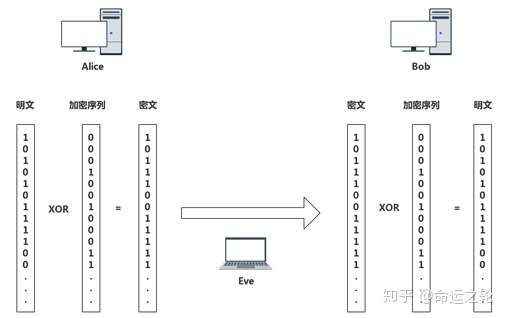 图1
图1
那流密码与伪随机数有什么关系呢?如果写过生成伪随机数的程序的人都会知道,生成伪随机数需要以“种子”作为初始条件,然后用算法不停迭代产生随机数。
实际上流密码就类似这个过程,用户使用的密钥就相当于随机数种子,密钥序列生成器就相当于一个伪随机数生成器,而密钥序列就是根据种子产生的源源不断的随机数,如图2。
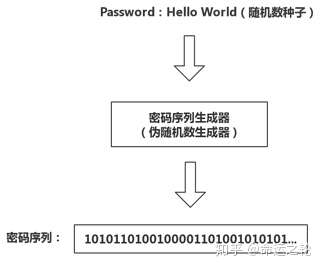 图2
图2
由此可见,流密码算法的安全性完全就是由伪随机数生成器去决定了,如果生成出来的密钥序列随机性不够,可以被预测,或者伪随机密钥序列与密钥本身的关系能够被统计分析出来,那么这个流密码算法就被破解了。
应用范围最广泛的流密码算法就是我们即将介绍的RC4算法,只可惜RC4算法已经被使用上述方法破解了。
5 RC4算法
RC4是Ron Rivest在1987年设计的一种流密码,最初是商业机密,后来被匿名发布到Cypherounks邮件列表上,由于实现简单和高效,而且在当时被没有发现什么安全缺陷,于是被广泛使用,曾经WEP、SSL、TLS中都使用了RC4加密算法。
介绍具体的RC4算法之前先看算法中的变量的作用
- S:S-Box,是长度256的字节数组,密钥的作用就是将这个数组搅乱,密钥序列就是根据这个数组生成的。
- K:保存密钥的字节数组。
- i与j:用于搅乱S的临时变量。
- k:用于生成密钥序列的临时变量。
- n:值为256。
- l:密钥的长度
RC4算法分为三个阶段:初始化、密钥调度(KSA)、伪随机数生成(PRGA),所有RC4算法的操作都是在 的加法群内完成的,但在实际分析中会将其扩展到
,
以下为RC4算法的伪代码。
初始化:
1: for i from 0 to n − 1 do 2: S[i] := i 3: end for初始化就是将S-Box按顺序赋值为1-255。
密钥调度(KSA):
1: for i from 0 to n − 1 do 2: j := (j + S[i] + K[i mod l]) mod n 3: Swap S[i] and S[j] 4: end for密钥调度就是根据密钥将S-Box搅乱到接近随机的状态,Swap就是交换 和
的值。
伪随机数生成(PRGA):
1: i := 0 2: j := 0 3: loop 4: i := (i + 1) mod n 5: j := (j + S[i]) mod n 6: Swap S[i] and S[j] 7: k := (S[i] + S[j]) mod n 8: print S[k] 9: end loop此处的伪随机数生成可以是一个无限循环,可以不断输出密钥序列,一次循环返回一个密钥序列字节 ,在这个过程中S-Box也会继续被搅乱,将
与对应明文字节XOR就可以产生密文字节了。
注意,RC4已经被证明不安全了,TLS中已经禁止使用RC4,如果你还在使用RC4,请马上投入AES的怀抱。
6 符号约定
数组用 表示,类似C语言,Java语言。
集合用 表示。
我们用X表示生成的密钥序列,K用于表示会话密钥,Rk用于表示根密钥,IV用于表示初始化向量。
我们用 ,
表示在密钥调度(KSA)阶段中第k次循环后的S-Box和
。
与
则是表示在密钥调度(KSA)还没开始之前的S-Box和
,此时的S-Box中
,
。
7 Klein攻击
我们从PTW攻击的基础Klein攻击开始说起。
Klein将攻击按轮数分类,将伪随机数生成的 个字节划分为一轮,例如
到
个字节称为第一轮,
到
个字节称为第二轮,以此类推,如果攻击利用了第
轮的字节,就成为第
轮攻击。
Klein发明了两种攻击方式,第一种是第1轮攻击,第二种是第2轮攻击,在Klein之前的攻击都是第1轮攻击,Klein发明了首个第2轮攻击,不过最高效的还是他的发明的第1轮攻击,本文也只介绍他发明的第1轮攻击。
7.1 RC4密钥调度弱点
在理想情况下,密钥由n个独立同分布的 元素组成,密钥调度(KSA)阶段可以产生所有相等概率的
个结果,但是S-Box只有
种可能,因此密钥调度(KSA)后的S-Box分布肯定与均匀分布不同。
7.2 RC4伪随机生成中的相关性
Klein证明了外部可以观察到的变量 、
与加密算法的内部状态
、
和
有着强相关性,这些相关性将成为攻击的基础。
现在我们来证明这些相关性,接下来我们来分析伪随机数生成(PRGA)代码中的第7行和第8行,就是 的计算和
的输出。
7.3 相关性定理证明
假设RC4的内部状态是均匀分布的,那么对于给定的变量 我们可以证明:
(1)
(2)
如果是另一种情况, ,那么我们可以证明:
(3)
(4)
这里解释一下,(3)和(4)指的是 ,但是
,
是除
以外的另一个单独的值。所以(3)和(4)指的是等于除
以外的另一个单独的值的情况的概率,而不是指等于除了
以外的所有其他值的其他所有情况的概率,实际上
非常接近
。
上述公式证明如下,注意(1)源于(2),(3)源于(4)。
证明(2),我们用和 和
计算所有内部状态,首先根据RC4的伪随机数生成算法的第7行,
,重写
为
。
具体过程是将 两边同时加上
,变成
而
,所以可以写成
然后分两种情况, 和
1.
这种情况下 ,然后可以得到
。
具体过程是基于 ,由于
所以就可以写成
那
就可以约掉了,变成
而
所以上述等式可以写成
把
移到右边就可以得出
在这种情况下S-box中剩下的 个成员存在
种可能性。
2.
这种情况下我们可以得出 和
。
具体过程 由
得出,
由
得出。
这里的 存在
种可能性(
占了一种),S-box中剩下的
个成员存在
种可能性。
根据上述两种情况,总结起来就是当 且
的情况下存在
种可能性,但是
的情况下存在
种可能性,所以
,(2) 证明完毕。
证明(4)也是类似的过程,首先要分成三种情况, 、
、
且
。
1.
在这种情况下 ,所以
。那
约掉后,变成
而由于
,所以
。
但是由于前面设定 ,所以这种情况不成立。
2.
在这种情况下由 可以得出
。
但是由于 ,所以这种情况也是不成立的。
3. 且
只有这种情况下是成立的,我们可以得出 和
。这里的
存在
种可能性(
、
各占了一种),S-box中剩下的
个成员的排列存在
种可能性。
根据第三种情况,可以得出当 且
且
的情况下存在
种可能性,但是
的情况下存在
种可能性,所以
,(4) 证明完毕。
以上是假设RC4内部状态是均匀分布的,但是实际上内部状态离均匀分布会有一定差异,但是不会差异很大,所以上述概率是近似的。
7.4 第一轮攻击
现在我们把刚刚证明的定理应用到接下来的第一轮攻击中,此处的会话密钥格式与WEP的不同,根密钥在初始化向量之前,格式为 ,接下来我们的攻击目标是恢复出根密钥的前两个字节,之后我们再来探讨恢复后续密钥字节的方法和初始化向量在根密钥之前的情况。
7.5 攻击的基础版本
现在我们来研究密钥调度(KSA)阶段的前两步,就是 与
的情况。
在第一步中( ),此时的S-Box刚刚初始化,
,由于
,此时的
,所以
,然后在下一步
中与
交换。
在第二步中( ),
增加
,然后
与
交换,由于在开始状态下
,所以此时的
。
除了以下的情况:
1. ,
。这种情况下
。
第一次循环中 ,
,
和
互换,最终
。然后第二次循环,
,
,结果是
和
互换,最终还是
。
2. ,
。这种情况下
。
第一次循环中 ,
,
和
互换,最终
。第二次循环
,
,结果就是
,最终
与
互换,
。
3. ,
,这种情况下
。
第一次循环中 ,
,然后
和
互换。第二次循环
,
,
,
,求余
后
,也就说与上一次循环不变,
和
互换,结果
为 0,因为第一次循环已经把0换到
的位置上了。
4. 并且
。这种情况下第二次循环后
因此
得到值
,这是第一步之后
的值。(论文中是
但我觉得是
,因为第一次循环后
)
第一次循环中 ,
,
和
互换。第二次循环
,
,
,
,
求余后
,最终
和
互换。
以上的许多种特殊情况可能看起来让人困惑,但是我们唯一需要知道的是:对于固定的 ,第二次循环之后
的值
是很容易就可以通过计算得到
的。
在密钥调度(KSA)阶段的其余循环中,除非 取值1之外,否则永远不会改变
。
这种情况在一个步骤中发生的概率是 ,(只有取值1这一种情况会改变
,剩下
种情况都不会改变
)。
如果会话密钥的长度为n,并且所有密钥字节都是独立同分布的,我们可以得出结论,在第二次循环之后 不会被改变的概率为
。
当然,对于较短的密钥,独立同分布的假设是错误的,这会导致一些问题,我们在后面再讨论这些问题。 不过,我们可以将 作为在密钥调度阶段的第二次循环之后
未被改变的概率的良好近似值。
这个时候我们已经实现了以下目标:我们知道RC4伪随机数生成(PRGA)刚开始时有高概率( )
的值将是
,而
的值只取决于
和
。
现在我们要使用之前证明的相关性定理,根据RC4生成伪随机密钥序列来获得 。为了实现这一目标,我们将研究第一个伪随机字节的生成。
首先 设置为1,然后
和
(
)交换。现在
包含我们想要的值
。此外,我们是可以观察到RC4伪随机生成(PRGA)的输出
的。但是根据之前证明的定理(1),我们知道
的概率为
。(再次注意,在真正的RC4实例中,S-Box和
都不是真正随机的。因此,定理(1)仅给出近似值,但小误差对攻击没有影响。)
总结起来就是:
(5)
很好理解,就是
和
同时发生的概率。
这里详细解释一下 。
表示在密钥调度阶段结束时
的概率,也就说原来的
被交换了,那么
肯定就在S-Box剩余的其他位置
,我们可以假设
(
)。
表示伪随机生成时
而是
(
)的概率,由于
非常接近
,所以我们可以把y当成是一个均匀分布的随机值,有一定概率
。
所以 表示
(
)但是恰好
的概率。
我们对RC4可以采取以下的攻击形式:
对于许多不同的初始化向量,我们观察RC4伪随机生成(PRGA)的第一个字节 并计算
。得到
正确值t的值的概率约为
。所有其他值的相对概率小于
。如果会话数量足够多,我们就可以确定正确的值是出现次数最多的值。
7.6 攻击其他密钥字节
到目前为止,我们只能恢复前两个密钥字节,而且得到正确的t后,我们需要暴力猜测 的
种可能性才能找到正确的
。
现在我们要恢复 。我们可以发现,在密钥调度(KSA)阶段的第三次循环中,
被设置为值
。 函数
是可以很容易计算的,对于固定的
,
和
存在唯一的
,其中
。
不考虑特殊情况的话,具体过程如下:第一次循环 ,
,
和
互换。第二次循环,
,
,
和
互换,结果
。第三次循环,
,
,
,
,
和
互换,结果
。
在概率 的情况下,
的值在密钥调度(KSA)阶段的剩余
循环和伪随机生成(PRGA)的第一循环中不改变(实际上应该比
不改变的概率更高,因为只有
了)。在伪随机生成器的第二次循环中,
与
交换,即
设置为
。 现在我们应用之前证明的定理来根据RC4伪随机生成(PRGA)的第二个输出字节计算
,而从
我们可以计算
。
密钥字节 ,
等可以通过观察RC4伪随机生成(PRGA)输出的第三个,第四个字节用相同方式计算得到。
最终我们可以得出:
(6)
注意,此处的 是在伪随机生成(PRGA)阶段中的,而
是在密钥调度(KSA)阶段中的。
举个例子,现在我要恢复 :
套入等式(6)得到 ,而从前面的分析中我们知道
,我们现在就假设运气很好,碰到了概率
的情况,最终可以得到
。
很明显,计算 就可以恢复出
。
7.7 导致攻击失败的特殊密钥字节
在前面我们估计 在密钥调度(KSA)的第一次循环之后不改变的概率为
,如果会话密钥由
个独立字节组成,那么这是正确的,但是在真实的攻击中,会话密钥通常短于
个字节,那概率
就不太正确了,我们现在来讨论这一事实引起的问题。
其实问题不在于会话密钥短于 ,而是这样会导致密钥调度期间不同的
的值不是独立的。只要会话密钥的长度对于
来说不是太小的(长度为8的会话密钥对于
就足够了),则不同的
的值之间的相关性就能足够小,那么
仍然是
不改变(
不取值1)的概率的良好近似值。
现在问题来了,由于会话密钥的格式为 ,密钥调度阶段的前
个步骤在所有会话中都是相同的(
是根密钥的长度),如果我们运气不好,在前
个步骤中
取值为1,那么我们假设的
就会失效,导致我们的攻击的基本版本将无法恢复密钥。
这里举个例子, 时,
,所以
会与
交换,然后
,循环继续进行,在
时,
,那么会导致
与
交换,结果
,
就被改变了。由于
,密钥调度阶段的前
个步骤在所有会话中都是相同的,每个会话的
都会改变,现在
不变的概率不是
了,而是0了,导致后面进行的密钥恢复攻击必定会失败。
这种情况在其他 中也会出现,例如
前
步骤中取值2就会改变
,取值3就会改变
,导致对应密钥字节无法正确恢复,现在我们必须找到一种方法来恢复上述情况的密钥字节,让我们来仔细看看这次攻击。
在前面我们知道可以恢复S-Box在密钥调度阶段的前 个步骤之后的
,
到
(在密钥调度阶段的
步骤中,已经开始处理IV了)。这是可行的,因为虽然在前
步骤中
,导致
被改变,但是在后面的密钥调度中我们依然可以假设
不再改变的概率是
。我们现在的任务是从这些信息中恢复根密钥。
因为 只有
个可能值(
),但是只有
个可能的密钥,我们可以预计
个密钥产生相同的
。这意味着对于
和
,我们只需要搜索
个密钥,这种工作量完全可以忽略不计,恢复这种特殊密钥是完全可行的。
我们现在分析怎么找到这些密钥的集合。
我们首先猜测 。 现在我们可以模拟密钥调度阶段的第一次循环。 我们称在第一次循环之后,
的值,为旧值,每一个其他的值我们称之为新值。
我们称在 ,
的
和
之间的交换为有问题的交换,如果
,那么这个有问题的交换后果会很严重。
如果我们能确切的知道哪些有问题的交换发生,我们可以调整我们的恢复密钥的策略,现在我们就来想办法做到这一点。
由于有问题的交换不会改变集合 ,不会用新值替换旧值。我们根据恢复出来的密钥调度阶段的第
步之后的
中搜索旧值。预期的旧值数量是
(对于
,
,这是3.75),每个存在的旧值表示可能存在有问题的交换。
举个例子,假如 ,我们猜测
,旧值为1 ,2, 3, 4。在密钥调度阶段的前5个步骤之后,我们有
,
,
且
,只有一个旧值,因此最多只有一个可能有问题的交换。 由于刚开始
,有问题的交换必须是交换
和
,必然在步骤
或
时发生。
我们针对有问题的交换的每个组合计算相应的密钥并测试该密钥是否正确这样计算工作量肯定大于普通密钥的情况,但是依然是可以做到的。
还是刚刚那个例子,如果是 时交换
和
,那是没有问题的,不会影响攻击,但是
时交换
和
问题就大了。
此时我们应该假设原来的 在
中,而
应该等于2,然后再计算密钥值测试是否正确。
7.8 初始化向量在根密钥之前(WEP的情况)
现在假设初始化向量在主密钥之前,格式为 。如果
是初始化向量的长度,我们已经知道会话密钥中的字节
,所以攻击者能够计算密钥调度(KSA)阶段的前
次循环。因此他可以将第
步之后的
的值
用于计算第一个未知密钥字节
(这个取决于初始化向量,每个会话
都是不一样的)。在概率为
的情况下,该值在密钥调度(KSA)的剩余步骤,和伪随机生成(PRGA)的前
步骤中不会改变。
我们可以使用前面证明的定理猜测 ,进而计算
。这种情况比根密钥在初始化向量之前的情况更简单,因为在这里我们不需要暴力猜测第一个密钥字节。
在这里,初始化向量是随机数或者是计数器,都是没有区别的,对于攻击来说,计数器是也是良好近似的随机数。
另外,由于前面的IV增加了足够的随机性,避免了前面讨论的“7.7 导致攻击失败的特殊密钥字节”的问题,由于 也由IV决定,那么前
步骤中就不可能每个会话都出现
了。
实际上Klein攻击在其他情况下也有可能无法恢复密钥,这种情况我们在介绍完PTW攻击后一起讨论。
7.9 具体应用Klein攻击恢复RC4密钥
Klein成功证明了密钥序列与密钥本身的关系,通过前面所证明的定理(6)计算,得到正确密钥字节的值概率约为 ,得到其他值的相对概率小于
,那为了让正确值能够与其他值区分开来,我们必须收集大量使用了不同IV的密钥序列,对每个密钥序列用定理(6)计算所有
(如果是
需要暴力猜解第一个密钥字节),并建立一个表格,统计每个密钥字节计算结果的值出现的次数,这个过程通常被称为“密钥投票”。
当计算了数量足够多的密钥序列之后,正确密钥值出现的次数会明显比其他值多,我们就可以得知正确的密钥值了。
注意,在计算一个密钥序列的 (
) 时,我们不能根据同一个密钥序列计算得出的
去计算
,因为同一个密钥序列计算得出
很有可能是错的,需要使用当前统计结果中出现次数最高的
的值去计算,这就导致了一个很严重的问题,而PTW攻击的出现就是为了解决这个问题。
8 PTW攻击
相信大家看到这里已经明白了Klein攻击的原理,Klein攻击中只要收集足够多的会话,就可以迭代计算所有密钥字节。现在我们来思考一下Klein攻击的缺陷,Klein攻击最大的问题在于恢复 (
)之前我们必须先把
到
全部都恢复了。
实际上这是非常困难的,我们必须要先收集到足够多使用不同IV的密钥序列才能确定 到
的正确值,这就导致了一旦前面的密钥推测错误,后面的就全错了,一旦前面的密钥有一个正确率更高的选择,后面的密钥就全部需要重新计算重新投票,而且为了实现这一点我们还需要把前面捕获的会话的相关数据全部保存起来。这就是为什么我在前面说Klein攻击需要大量计算资源。
PTW攻击扩展了Klein攻击,使得可以独立地计算每个密钥字节。在PTW攻击中我们计算的不是密钥字节本身,而是密钥字节的“和”。与Klein攻击不同的是,PTW攻击完全为WEP设计。
8.1 将Klein攻击扩展到多个密钥字节
我们回顾一下Klein攻击的定理(6):
从这条等式我们可以推导出 的等式:
(7)
实际上根据密钥调度(KSA)的原理 可以写成
,然后替换到上面等式中,可以得到
左右交换一下就可以得到
(8)
现在我们可以通过计算得到 的和。
通过不断的替换 ,我们就可以得到
的值,而在WEP中我们想知道的是
,我们使用符号
作为密钥字节的总和,我们可以得出:
(9)
注意,等式右边的 是需要根据
到
才能计算得到,但是这样就跟Klein攻击没有区别了,所以我们要用
替换
,
只取决于
到
,最终得到
的近似值
,如下:
(10)
在理想条件下 的概率为:
(11)
证明与前面的Klein攻击相同。
不过由于用 替换
,所以
是正确值的概率会稍微下降。
现在我们来计算用 替换
中出现的所有
的情况下,完全不影响接下来对密钥的推算的概率。
只有 到
中的其中一个值为
时,
才会与
不同。例如
,那么
就会与
交换,那么
,这样
,到时候计算出来的密钥肯定是错误的。如果所有
具有
,那么
所有值与
相同,假设
是随机的,那么这会发生的概率为
。
另外,如果j在前面循环中没有取值 而且
也没有取值
,那么在循环
到
中
就不会改变。
在前面循环中没有取值
发生的概率为
,
没有取值
发生的概率为
。
这里举个反例,
在前面循环中取值
,例如
,那么
就会与
交换,在
时,
已经不是原来的值
了,而是
了,然后再交换到
,那我们在计算
时肯定是错误的。
这里也举个反例,
取值
,例如
,那么
就会与
交换,那么之前的
就被改变了,导致后面进行的恢复
的攻击必定会失败,其实这个类似之前分析Klein攻击时的“7.7 导致攻击失败的特殊密钥字节”。
总结起来,用 替换
中出现的所有
的情况下,完全不影响接下来对密钥的推算的概率为:
(12)
最终我们可以计算 取正确的
值的概率下限为
:
(13)
PTW攻击的作者使用104位WEP密钥进行超过50,000,000,000次模拟的实验结果表明, 这个近似值与正确值的相差不到0.2%。
8.2 应用PTW攻击恢复WEP密钥
假设使用了104位的WEP根密钥,对于从 到
的每个
,以及每个会话的密钥序列,我们用公式计算
,并对每个
建立一个表,进行密钥投票,统计各个
出现的次数,当处理完足够多的会话的密钥序列后,我们就可以假设每个
的正确值,是出现次数最多的
。
第一个根密钥字节 ,而其他的根密钥字节可以通过
计算得到。
如果是40位根密钥的情况,只需要通过计算 到
就可以得出。
9 强密钥字节
在前面的等式中我们假设 代替
不影响密钥计算,但是对于部分情况来说,这是错误的,在前面我们列举了三种情况,但不是每一种我们都需要担心。
到
中的其中一个值为
时,
会与
不同。这种情况不需要担心,因为
到
是取决于IV的,而IV每一个会话都会变化,也就是说不可能每一次都那么凑巧是
。
取值
也是同理,
由IV决定,不可能每次都凑巧是
。
以上两种情况只要出现概率不高就不会对攻击产生影响。
真正需要担心的是 的值在
之后到
之前的循环中被
取值,一旦出现这种情况就会导致
提前与一个未知的值交换(取决于IV和前面的密钥字节),而到了
的循环中这个未知的值代替了
与
交换,显然在计算密钥时根据这个未知的值是无法得出正确的密钥字节的值的。
如果密钥中有一部分特殊的密钥字节,那么上述情况出现的概率是非常高的,这种特殊的密钥字节我们称为“强密钥字节”,其他密钥字节称为“普通密钥字节”。只要密钥中至少有一个强密钥字节我们就称这个密钥为“强密钥”,如果密钥没有任何强密钥字节则称为“普通密钥”。
更正式的来说,Rk是强密钥, 是Rk的其中一个字节,且
是强密钥字节,那么
满足以下情况:
(14)
如果上面这条等式看不懂,我给大家详细举个例子
由于 ,而由于是刚开始搅乱大部分情况下
,所以
可以写成
可以写成
,然后为了方便举例我们把
,
,以此类推,一直到
(40位根密钥),然后我们假设
是强密钥字节。
那么
如果 ,那么
如果 ,那么
如果 ,那么
如果 ,那么
显然符合等式的话 会被之前循环中的
取值,导致
提前被交换。
除非有IV让 到
取值为
到
,让
提前改变,破坏掉
,让强密钥字节存在的情况公式也不成立,但是这种情况概率很低,
,所以大部分情况下只要有强密钥字节,等式就成立。
这最终导致的结果就是 在前面循环中没有取值
发生的概率接近于0,进而导致
接近于0,最终导致
,这非常接近
。
,这是一个多小的数字呢?我们代入
的话
在 的情况下
与
具体的数值为
的情况下
甚至比
还高那么一点,虽然差别非常非常小,几乎可以忽略。
以至于PTW攻击作者测试了在35000到300000个会话的强密钥字节的投票分布,强密钥字节的正确值的投票数依然不能和其他值区分开来,其他值的票数很可能比正确值更高。
在论文中PTW攻击的作者一直表示Klein攻击不受强密钥的影响,但是我个人觉得Klein攻击在强密钥下一样会失效。
Klein攻击下虽然没有了 与
不同的问题,但是
的值在
到
之间的循环中被
取值后,同样会导致
提前与一个未知的值交换,然后到了
的循环中这个未知的值代替了
与
交换,导致
并不是我们想要的
正确值,Klein攻击就无法进行下去。
注意,这里与前面的“7.7 导致攻击失败的特殊密钥字节”是有区别的,前面那个是导致 在交换后的剩余
次的循环中不变的概率为
不成立,而强密钥是
成立,但是
在交换后就是已经是一个错误的值。
9.1 找出哪些字节是强密钥字节
如果 是普通密钥字节,那么
的正确值应该以概率
出现,我们可以假设除了正确值以外的所有其他值出现的概率为
。
如果 是强密钥字节,我们可以假设所有值出现概率都是
。
现在让 得到
的投票比例,我们计算一个密钥字节不是强密钥的概率和不是普通密钥的概率。
(15)
如果是强密钥字节,由于各个值出现概率接近 ,所以
接近为0。如果是普通密钥字节,正确值会特别突出,其他值出现概率比
小,全部平方后相加
会明显增大。
(16)
如果是强密钥字节,即使是投票数最多的值依旧接近 ,与
差别比较大,而
与
也有微小的差距,全部平方后相加,
会增大。如果是普通密钥字节,投票数最多值基本符合
,而其他值基本符合
,所以
接近为0。
总结起来就是
强密钥字节的情况 接近为0,小于
。
普通密钥字节情况, 接近为0,小于
。
如果能收集足够的会话样本,如果 小于
,
很可能是强密钥字节,就可以对其进行强密钥字节推测。如果只有少量会话样本可用,则可以使用
计算密钥字节
是强密钥字节的可能性。
9.2 找到强密钥字节的正确值
假设 是强密钥字节,并且密钥
到
的正确值都已经得出,那我们可以使用定理(14)推导得到计算强密钥字节
的等式。
(17)
因为 最多可能有
种值,我们可以尝试
的每种可能值,也就是
最多可能有
个可能的值,例如
是104位的根密钥的最后一个密钥字节,则有12种可能值。
还是前面那个 是强密钥字节的例子,
,现在我们要恢复
,由于
到
的正确值都是已知,所以A、B、C都是可以计算得到的。
如果 ,那么
如果 ,那么
如果 ,那么
如果 ,那么
我们只需要通过计算得到这4种不同的 的值,然后逐个代入已知的其他密钥字节中进行密钥测试,就可以得出正确的密钥值了。
如果是强密钥字节,我们就不能使用密钥投票了,最高票的 不再是正确值,需要假设用公式得出的
计算
是
的正确值。
当然,其他普通字节还是使用密钥投票来确定 的正确值。
以上的方法只有在密钥中的强密钥字节数量很少才可行。
实际上一个密钥中所有字节都可以是强密钥字节,在40位根密钥中可以有4个字节都是强密钥字节,这种情况下我们需要测试的密钥数量只有 ,但是在104位根密钥中12个字节都是强密钥字节的情况下,我们需要测试高达
个不同的密钥,这虽然可以做到的,但是会严重拖慢我们的攻击速度。
我现在用的电脑的CPU是i5 2500K(比较旧),一秒钟大概可以测试43万个RC4密钥,测试479001600个密钥大概需要18.5分钟。
当然,所有密钥字节都是强密钥字节的情况非常少见,但是要找出强密钥字节正确的值除了按上述方法穷举以外似乎没有其他更好的办法。
如果你现在有支持开放WEP热点的设备,你把密钥设置为16进制的FDFCFBFAF9F8F7F6F5F4F3F2F1,你会发现Aircrack-ng就无法破解了,因为每个字节都是强密钥字节,计算量太大了,如图3。
0xFD = 253,
0xFC = 252,
0xFB = 251,
0xFA = 250,
以此类推。
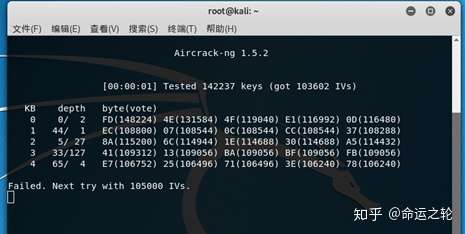 图3
图3
10 PTW攻击的密钥排名
在能获取到大量会话时,投票数最多的就是 的正确值,但是在获取到的会话数量不够的情况下,
未必是投票数最多的那个,但通常是投票数排名(从多到少)靠前的那几个中的一个。
在无法获取到足够的会话的时候就需要根据已知信息想办法了,我们可以通过多条计算路径来恢复密钥,例如假设 是在投票值的前三名中,就根据这个三个不同的密钥字节创建三条密钥计算路径,这个过程被称为“密钥排名”,以下是一些密钥排名策略:
静态路径数
对每个密钥字节的排名靠前的前 个值创建路径,这是一种最简单的实现,但是缺点就是太死板了,每个密钥字节都搜索排名靠前的
个值的情况下,我们需要计算
个不同的密钥(
为密钥长度)。对于104位的密钥有13个密钥字节,那么假如
,我们就需要计算
个不同的密钥,如果
,那么就需要计算
个不同的密钥,这计算量就很大了。
智能选择路径
如果我们在测试所有最高票的密钥字节组成的密钥时发现密钥不正确,那么肯定有至少一个密钥字节不是最高票的密钥字节,那么我们查看每个密钥字节的排名列表,寻找第二名与最高票差别最小的密钥字节,这是错误可能性最高的字节,然后用第二名的值取代此密钥字节最高票的值再进行测试,记录此字节的搜索次数加一,如果还是错误则重复这个过程。
设 为密钥排名列表中密钥字节
的搜索次数,那么我们需要计算的密钥数量为
,这种策略可以让搜索密钥的数量更少。
密钥排名的一般改进
这里有一些策略可以辅助密钥排名工作,或者独立于密钥排名使用,提高攻击的有效性:
密钥空间限制:假如你对密钥内容有一定的了解,例如在饭店的WIFI密码可能是电话号码,这就意味着密钥只包含表示十进制数字的ASCII字符,每个 的值将介于48和57之间,那么在密钥排名时就可以筛选掉不符合范围的密钥字节。
暴力猜解密钥字节:如果只有少量密钥字节(例如只有一两个)的投票值还没拉出差距(例如强密钥字节,各个值出现次数非常接近),无法判断哪个才是正确值,那么我们可以暴力猜解这个密钥字节,尝试所有256种可能性,只要计算时间能接受范围内。
11 IEEE 802.11数据帧格式
理论部分现在已经介绍完了,但是如果想要编写一个应用PTW攻击恢复WEP密钥的程序,把理论变成现实,我们还需要先了解一些关于IEEE 802.11协议的相关知识。
实际上IEEE 802.11协议非常复杂,详细的说可以再写一本书,这里我只分析我们要用到的部分,有兴趣详细了解的话推荐去看 “802.11无线网络权威指南”这本书,虽然这本书已经比较旧了,但是非常系统。
IEEE 802.11帧主要有三种类型:管理帧,控制帧,数据帧。
- 管理帧:主要用于监管网络,身份验证、解除身份验证、关联网络、探测网络、宣告网络的存在等功能。
- 控制帧:主要用于提高物理层数据传输的可靠性,协助数据帧传输,包括数据确认,取得信道使用权、清除发送、省电模式控制等功能。
- 数据帧:主要用于传输上层数据,上层数据存放在数据帧的帧主体中,是恢复WEP密钥最需要关注的一种帧类型,图4为数据帧的帧格式。
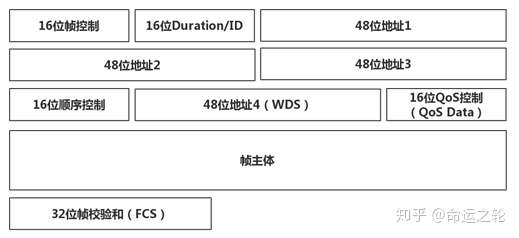 图4
图4
我们需要关注的字段是:帧控制、地址字段、帧主体、QoS控制。
帧控制
 图5
图5
帧控制字段实际上由图5中的四个子字段构成。
版本字段是固定的,值为0,因为暂时来说802.11只有一个版本,未来可以会有新的版本。
类型字段用于区分帧类型,现有的类型为:管理帧(00)、控制帧(01)、数据帧(10),我们只需要关注数据帧(10)。
子类型字段用于进一步区分不同功能的帧,我们只需要关注数据帧类型下的两种子类型:Data(0000)、QoS Data(1000),其他子类型要么是不携带数据的要么是很少出现的不需要关注。
我们可以根据上述的类型和子类型字段筛选捕获到的802.11帧。
 图6
图6
图6为帧控制中标志字段的每个位的功能,我们只需要关注To DS位和From DS位。
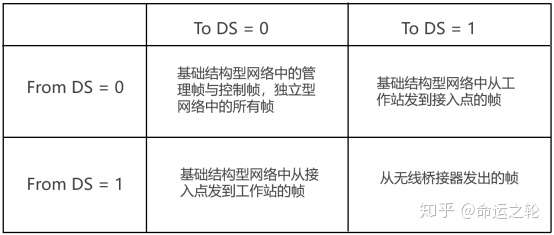
这两位用于表示来源或目的地是否为分布式系统(distribution system,DS),地址字段也会受到这两个位的影响。
地址字段
一个802.11帧最多可以包含4个地址字段,不同的帧类型地址字段的功能也不同,大部分情况下只会用到前三个地址,第四个地址只有在无线桥接器(WDS)的情况下才会使用,地址字段主要用于以下用途:
- 目的地址(Destination address,DA):代表最后的接收端,即负责将帧交付上层协议处理的工作站。
- 源地址(Source address,SA):代表传送的来源,每个帧只能来自单一工作站。
- 接收端地址(Receiver address,RA):代表负责处理该帧的无线工作站。如果是无线工作站,接收端地址为目的地址。如果帧的目的地址是与接入点相连的以太网结点,接收端地址为接入点地址,而目的地址可能是连接到以太网的一部路由器。
- 发送端地址(Transmitter address,TA):代表将帧传送至无线媒介的无线接口。
- 基本服务集标识符(Basic Service Set ID ,BSSID):要在同一个区域划分不同的无线局域网络,可以为工作站指定所要使用的BSS(基本服务集)。在基础结构型网络里,BSSID即是接入点无线接口所使用的MAC地址。而独立型网络则会产生一个随机的BSSID,以防止与其他官方指定的MAC地址产生冲突。
802.11对来源地址(SA)与发送端地址(TA)以及目的地址(DA)与接受端地址(RA)是有明确的区别的,帧的发送端不见得就是帧的来源,接受端也不见得就是帧的最终目的地,可能只是中转,只有帧到达最终目的地才会由上层协议处理。
地址字段与To DS、From DS位的关系。

QoS控制
这个字段只有在QoS数据子类型中才会出现,用于标识数据帧的服务质量(QoS)参数,由于格式与普通的数据子类型不同,处理时记得留意。
帧主体
IEEE 802委员会将OSI七层模型的数据链路层分为两个子层,分别是逻辑链路控制层(Logical Link Control, LLC)和介质访问控制层(Medium Access Control, MAC),如图7。
这样划分的原因是为了将物理部分与逻辑部分完全分开,介质访问控制层主要负责控制物理层的物理介质,而逻辑链路控制层主要负责与上层协议协调。
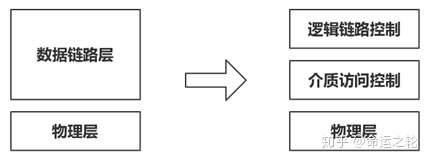 图7
图7
802.11就使用了这种结构,以802.2的逻辑链路控制层来封装携带上层数据,数据帧中除了帧主体以外的其他字段都是属于介质访问控制层的,帧主体属于逻辑链路控制层,帧主体格式如下:
 图8
图8
逻辑链路控制层作为一个单独的层它有着自己的特定协议,在IEEE 802.2中定义了802.2 LLC头部。
 图9
图9
- 8位DSAP:Source SAP,用于表示接收方的上层协议的类型
- 8位SSAP:Destination SAP,用于表示发送方的上层协议的类型
SAP为Service Access Points的缩写,中文为服务访问点。网络模型中,一个层可以请求另一个层提供服务,而SAP就是用来区分这些服务。在数据链路层中的SAP也被称为LSAP(Link Service Access Point)链路服务接入点。虽然LSAP字段的长度是8位,但是第8位是保留用于特殊用途的,也就是说只有128个值可以用于区分类型,此字段值由IEEE全球统一分配,以下为常见值:
0x06 IPv4协议
0x98 ARP协议
0xAA SNAP协议
- 8位或16位Control:控制字段,分为三种类型:I帧(用于传输面向连接的数据,16位)、监控帧(监督链路,例如数据确认、请求重传,16位)、未编号帧(设置命令和响应以及传输信息,8位)
当最初的IEEE 802.3/802.2 LLC帧格式推出之后,IEEE很快就意识到在IEEE 802.2标准里的LLC头部中给LSAP字段只分配一个字节是行不通的,一个字节无法满足未来出现更多新协议的需求,于是推出了802.2 SNAP协议(子网访问协议)作为802.2 LLC头部的扩展。802.2 SNAP头部如图10。
 图10
图10
- 24位OUI:Organizationally unique identifier的缩写,组织唯一标识符,允许特定组织给自己定义协议,如果OUI为0,就使用Ethernet II帧格式中的类型,如果OUI为特定组织的OUI则是使用特定组织定义的类型。
- 16位类型:与Ethernet II帧格式中的类型字段完全相同,这避免分配新的SNAP类型值,同时也解决了原有的LSAP只有一字节不够用的问题。
如果802.2 LLC帧需要使用802.2 SNAP协议,那802.2 LLC头部中的SSAP与DSAP都会设置为0xAA,控制字段设置为0x03,表示未编号信息。
如果使用WEP帧主体需要使用8个字节存储WEP相关的信息,3字节的IV、1字节的密钥编号、4字节的ICV,格式如下:
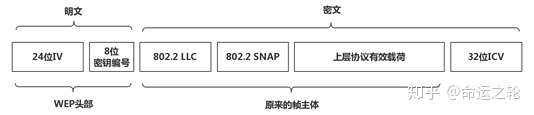 图11
图11
24位的初始化向量(IV)与8位的密钥编号会以明文形式传输,而原来帧主体与ICV以密文形式传输。WEP只保护帧主体,802.11帧头部(介质访问控制层)以及更底层的协议头部都不会得到保护。
WEP支持同时定义4个密钥,使用的密钥通过密钥编号区分,发送方必须指定使用的密钥编号,但是大多数情况下只会使用其中一个密钥。
ICV(integrity check value)指完整性校验值,用于校验未加密数据的完整性,ICV与帧主体一同被加密,保证不会被攻击者篡改,与802.11帧头部的FCS不同,ICV只校验帧主体,而FCS校验整个帧。
Radiotap
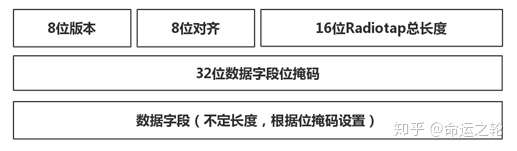 图12
图12
Radiotap 是网卡驱动添加在802.11 MAC头部前的数据,记录了信号强度、噪声强度和传输速率等物理层信息,想Radiotap更多信息可以参考http://www.radiotap.org/,要注意的是如果抓包的数据带有Radiotap,那我们在发包的时候也需要构造Radiotap。
12 获取密钥序列
上述介绍的WEP密钥恢复攻击实际上都是“已知明文攻击”,我们需要在知道部分明文和部分密文的情况下恢复出密钥序列,然后才可以进行进一步的攻击(仅密文攻击也是可以实现的,只不过难度更大,这里暂不分析)。如果我们要恢复40位的WEP根密钥我需要密钥序列的第3到第7个字节,如果我们要恢复104位的根密钥,则需要密钥序列的第3到第15个字节,如果是一些更长的密钥的特殊实现(如232位根密钥)则需要更多。
根据流密码的特性,我们只需要用密文 xor 明文就可以得到密钥序列了,如图13。
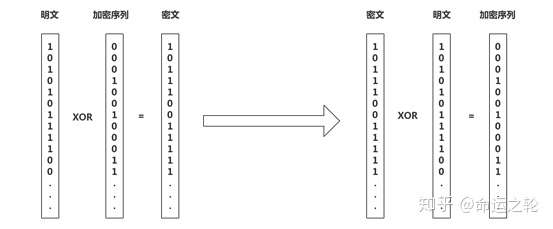 图13
图13
密文非常容易得到,只需要捕获无线协议帧就可以了,明文这里就需要我们来思考一下,数据链路层上面的通常是什么呢?
答案就是IPv4协议,即使现在都9102年了,IPv4协议依然是部署最广泛的协议,根据谷歌的数据IPv6在全球范围内的使用比例也就26.77%,而在WEP流行的年代就更少了,只有0.04%左右,完全是IPv4的天下。
12.1 通过IPv4头部恢复密钥序列
那我们来观察一下,上层为IPv4协议的帧有什么特征,图4中为帧格式,图中固定的或者可以猜测的字节用绿色去表示,很难猜测的字节用橙色去表示,无法猜测的字节用红色去表示。
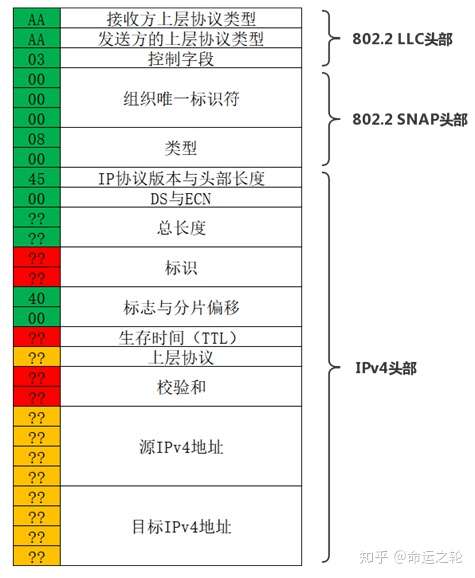 图14
图14
在前面我们知道802.11是通过802.2 LLC来封装上层的数据的,而由于使用了802.2 SNAP所以802.2 LLC头部中的SSAP与DSAP都是0xAA,控制字段为0x03,而802.2 SNAP头部中的OUI由于是使用Ethernet II帧格式中的类型,所以为0,这上述这部分字节无论上层协议是什么都是固定的,而Ethernet II帧格式中的IPv4类型的值为0x0800。
IPv4版本是固定的,为4,而头部长度绝大部分情况下也是固定的20字节,没有选项字段,DS(DiffServ,区分服务优先级)和ECN(拥塞标识符)在绝大部分情况下都是不会使用的,为0。
数据包总长度虽然不是固定的,但是WEP不会掩盖帧主体的长度,所以我们可以观察帧长度计算出这个值。
标识字段用于跟踪组装分片数据包,无法猜测,只能假设为随机。
标志与片段偏移:据PTW攻击作者分析了来自各种来源的流量后,发现大约85%的数据包是在设置了不分段标志的情况下发送的,大约15%的数据包清除了所有标志,在密钥排名中这两个字节可以加权投票。
往后的TTL、上层协议、校验和、源IPv4地址、目标IPv4地址字段都是非常难以猜测甚至无法猜测的了。
综上所述IPv4报文中能有把握恢复密钥序列也就前12个字节和第15、16字节,这对于恢复40位的密钥来说已经绰绰有余了,但是对于104位的密钥来说显然还是不够的。
那我们再来想想,在使用IPv4协议的情况下还有什么其他的协议可以让我们恢复密钥序列呢?相信大家很快就能想到,那就是ARP协议。
12.2 通过ARP报文恢复密钥序列
ARP协议全称为Address Resolution Protocol,即“地址解析协议”。顾名思义,它的作用就是将网络层地址解析为链路层地址,让数据可以在物理网络中进行传输。在IPv4下,ARP协议将IPv4地址解析为以太网的MAC地址。那我们现在来看看ARP报文可以让我们恢复多少字节的密钥序列。
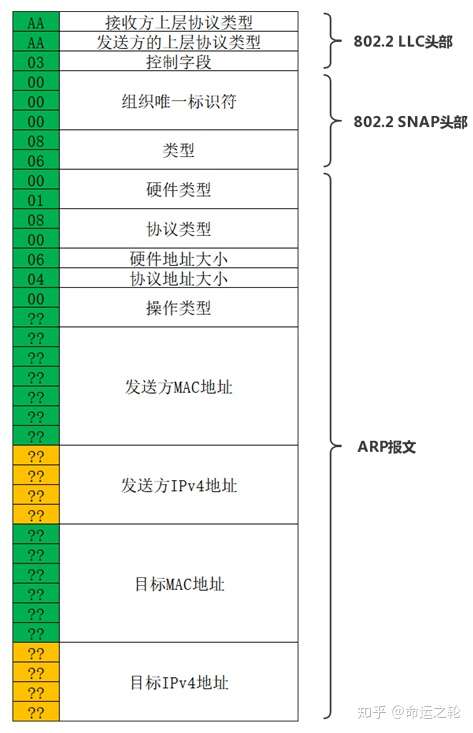 图15
图15
802.2 LLC与802.2 SNAP头部在刚刚的IPv4中已经说过了,唯一不同的是类型字段,ARP的值为0x0806。
ARP报文的头部中的字段都是固定值的,硬件类型为1表示以太网,协议类型为0x0800表示IPv4协议,硬件大小为6,是MAC地址的长度,协议大小为4,是IPv4地址的长度。
操作类型为1或2,1是请求,2是响应。ARP请求始终发送到广播地址,而ARP响应发送到单播地址,因此很容易区分ARP请求和响应。
在ARP请求中发送方MAC为发送主机的MAC,目标MAC通常为全0,而在ARP响应中发送方MAC为响应主机的MAC,目标MAC为发送请求的主机的MAC,这些都是可以通过802.11帧头部中的未加密的源地址(SA)和目标地址(DA)字段获取。
源IPv4地址和目标IPv4地址字段就非常难猜到了。
综上所述ARP报文中能有把握恢复密钥序列是前22个字节和第27到第32字节,这对于恢复104位的密钥来说也足够了。
由于ARP请求和ARP回复的报文大小都是固定的,我们很容易通过帧主体的长度判断哪个帧是携带了ARP报文。这里有可能会把少量TCP、UDP短的数据包识别为ARP导致失败,不过只要识别正确的情况占大多数就影响不大。
不过由于ARP报文在流量中占比极少,很难收集足够数量的报文恢复密钥,这里需要使用“ARP注入攻击”。
由于WEP并不会阻止重复的IV,也没有任何检测重放攻击的机制,所以我们可以将捕获到的ARP请求重放,重放后我们可以得到三个新的加密分组:
1.请求由接入点中转到广播地址(即使是广播报文也需要接入点中转)。
2.目标主机返回对该请求的ARP响应,并将响应发送到接入点。
3.接入点将该响应转发给原始请求站。
通过重复ARP注入过程就能够快速得到大量用不同IV加密的ARP报文。
如果捕获不到ARP请求,那我们可以使用“强制解除验证攻击”让网络中的客户端掉线,客户端重新连接无线网络时会刷新ARP缓存表,等客户端需要发送IP报文时,自然就会发送ARP请求,这样就可以获取到ARP请求报文了。
13 编写PTW攻击程序
现在相关的知识都了解完了,我们可以动手编写一个PTW攻击程序了,以下程序使用C++编写,以下为main.cpp的源码:
#include <stdio.h>
#include <string.h> #include <array> #include <set> #include <unistd.h> #include <sys/socket.h> #include <netinet/ether.h> #include <arpa/inet.h> #include <net/if.h> #include <netpacket/packet.h> #define TYPE_DATA 2 #define SUBTYPE_DATA 0 #define SUBTYPE_QOS_DATA 8 #pragma pack(1) struct MACsublayer { //unsigned short FrameControl; unsigned char Version:2; unsigned char Type:2; unsigned char SubType:4; //unsigned char Flags; unsigned char ToDS:1; unsigned char FromDS:1; unsigned char Flags:6; unsigned short DurationID; unsigned char Address1[ETH_ALEN]; unsigned char Address2[ETH_ALEN]; unsigned char Address3[ETH_ALEN]; unsigned short Seqctl; }; struct RadioTaphdr { unsigned char Version; unsigned char Pad; unsigned short Length; unsigned int PresentFlages; }; struct WEPInfo { unsigned char IV[3]; unsigned char KeyIndex; }; struct AttackInfo { unsigned char IV[3]; unsigned char X[7]; //密钥序列 }; #pragma pack() static unsigned int RKeyRanking[5][256]; //密钥排名表,5个密钥字节,每个字节256个值 static unsigned char HighestVote[5] = {0}; //当前最高票的密钥字节总和 static unsigned char RealKey[5] = {0}; //当前最高票的密钥字节 static std::set<std::array<unsigned char,3>> ReceivedIV; //保存接收过的IV,用于避免对相同IV重复投票,增加准确率(这是可选的) void Swap(unsigned char *a, unsigned char *b) { unsigned char tmp = *a; *a = *b