一、背景介绍
1.Unicode是一个编码方案
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
2.Unicode三种实现方式
- utf8 占用一到四个字节,英文一个字节,中文三个字节
- utf-16占用二或四个字节
- utf-32占用四个字节
二、Qt 字符显示异常
在Qt creator中,我们书写的代码文件被强制转换为 utf8,在简体中文版的 Windows 操作系统中,默认编码却是 GBK
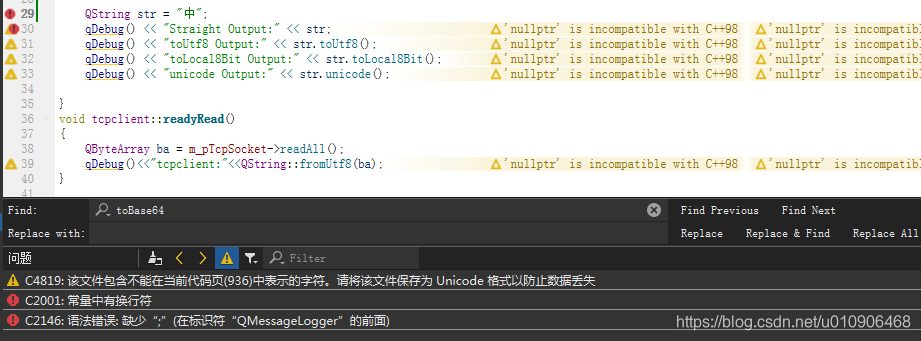
当使用Visual C++编译程序的时候,它会分析源文件采用何种编码,有BOM标识符则可以正确识别其编码是UTF-8,若没有BOM标识符则认为其使用本地字符集编码(Local字符集)。综述,源文件是utf8编码,vc编译器认为源文件是利用本地字符集进行编码的,当检测到特殊字符的时候,自然会报“常量中具有换行符”。
三、解决方案
1.通常情况下设置源文件代码为utf8-bom格式,这样vs编译器才会用utf8编码集来解释
2.最常见的是利用QString::fromLocal8Bit完成对字符串本地字符集到Unicode字符集的转换。

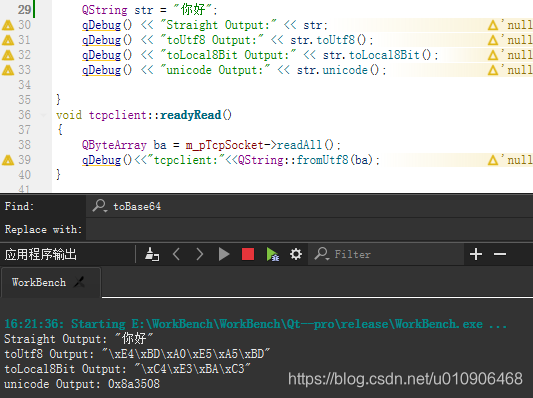
第一个“你好”为啥输出异常,因为源代码是以utf8-bom形式保存的,vs编译器是利用gbk字符集去编译的文件。此时的第一个“你好”是gbk字符集中的编码,qt只认unicode编码,自然输出异常。
第二个“你好”已经完成了gbk字符编码到unicode编码的转换,输出自然正常。
如果已经设置了# pragma execution_character_set(“utf-8”),即修改vs编译器的执行字符集。
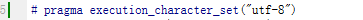

此时的第一个“你好”已经是utf8字符集中的编码,而第二个“你好”通过QString::fromLocal8Bit将已经是utf8字符集中的编码作为gbk字符集中的编码再去进行转换, 结果必定是在unicode中指向其他的字符。
