文章目录
Selenium WebDriver 简介
-
Selenium WebDriver是一个本地和远程的实时浏览器自动化工具,是最接近的模拟用户行为。
-
WebDriver的目标是提供一个良好设计的面向对象的API,提供了对于现代先进web应用程序测试问题的改进支持。
-
Selenium-Webdriver更好的支持页面本身不重新加载而页面的元素改变的动态网页。
Selenium WebDriver 原理
-
WebDriver是按照C/S(Client/Server) 的模式设计的。
-
WebDriver 启动目标浏览器,并绑定到指定端口。该启动的浏览器实例,做为web driver的remote server。
-
Client 端根据我们的需求以http请求形式发送给Server,并在执行各种操作后将返回值等信息返回。
-
Server端,也就是Remote server 需要依赖原生的浏览器组件(如:chromedriver.exe)来等待 Client 发送请求并做出响应。
Selenium WebDriver 安装
安装selenium库,在命令行中输入
pip install selenium
出现如下字样,则安装成功
Successfully installed selenium
下载与浏览器版本相匹配的webdriver
http://chromedriver.storage.googleapis.com/index.html
下载后将chromedriver.exe放到python安装目录下的Scripts目录

Selenium WebDriver 使用
浏览器常用操作
启动浏览器
不同的浏览器,方式略微不同
from selenium import webdriver
#谷歌浏览器
dr = webdriver.Chrome()
#火狐浏览器
dr = webdriver.Firefox()
打开网页
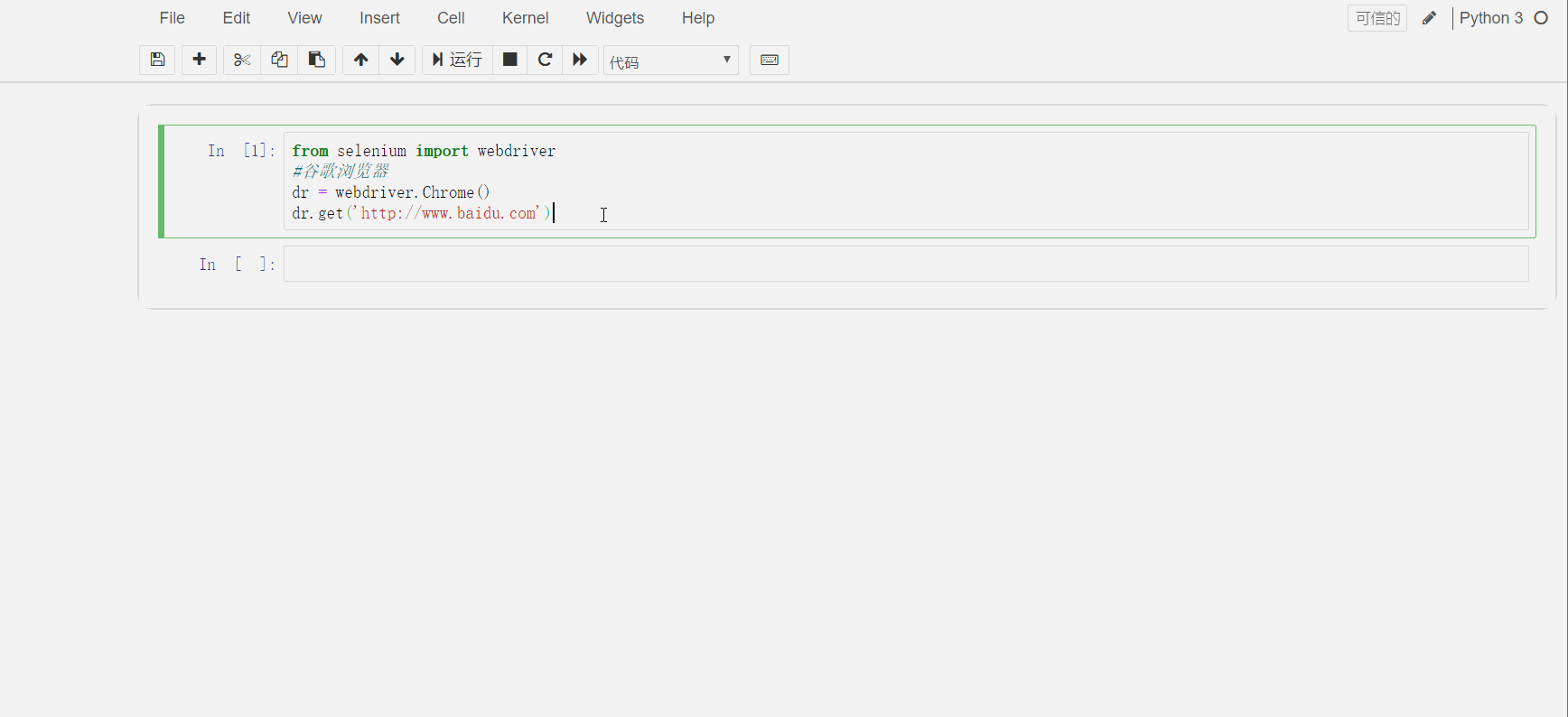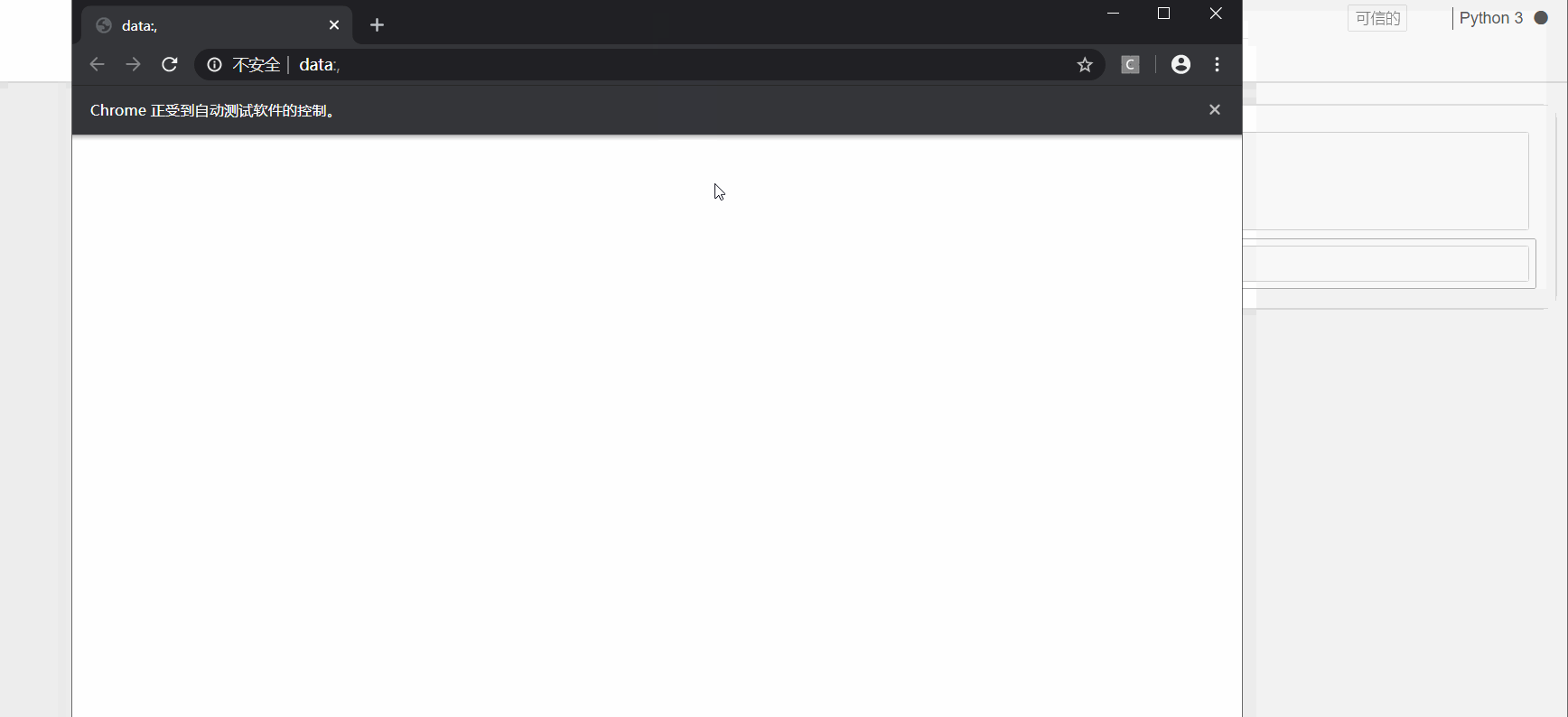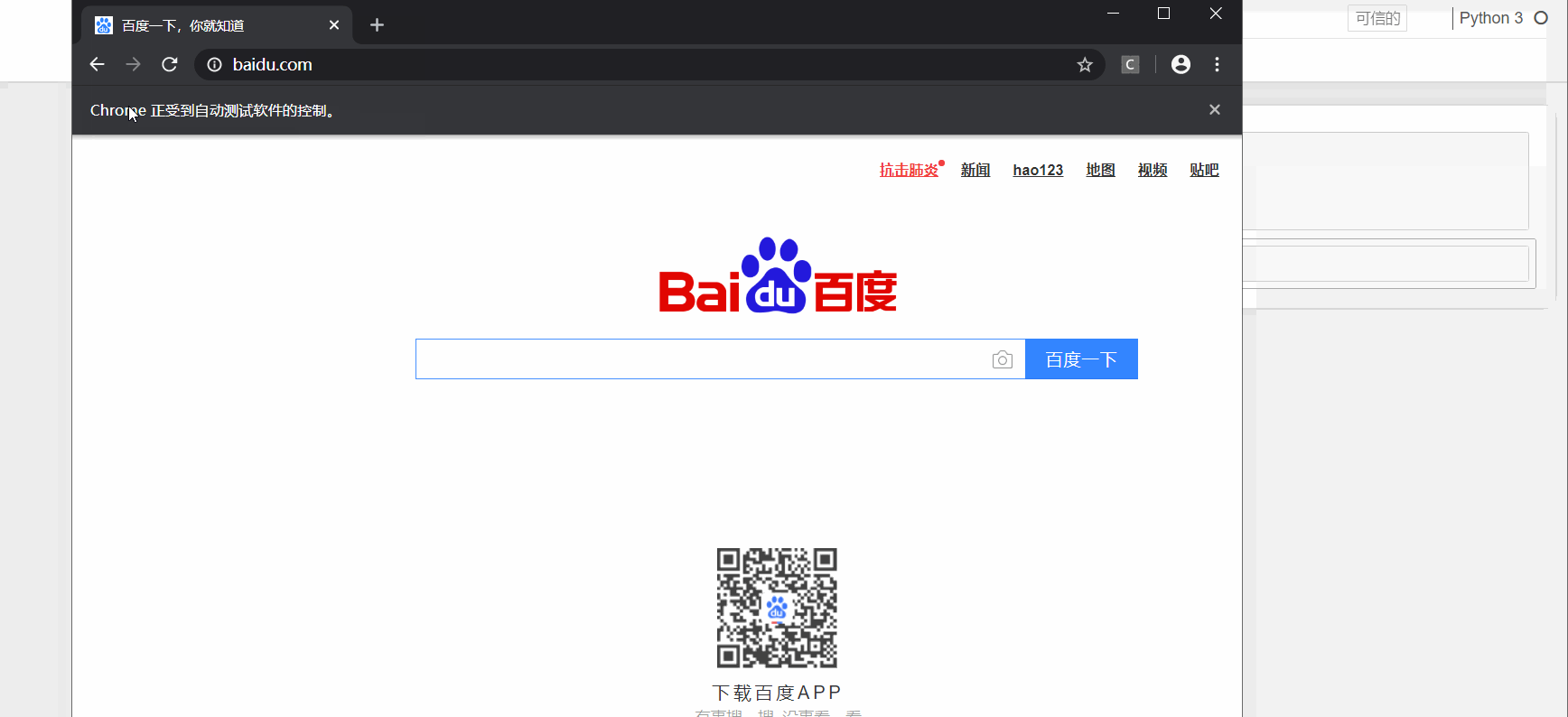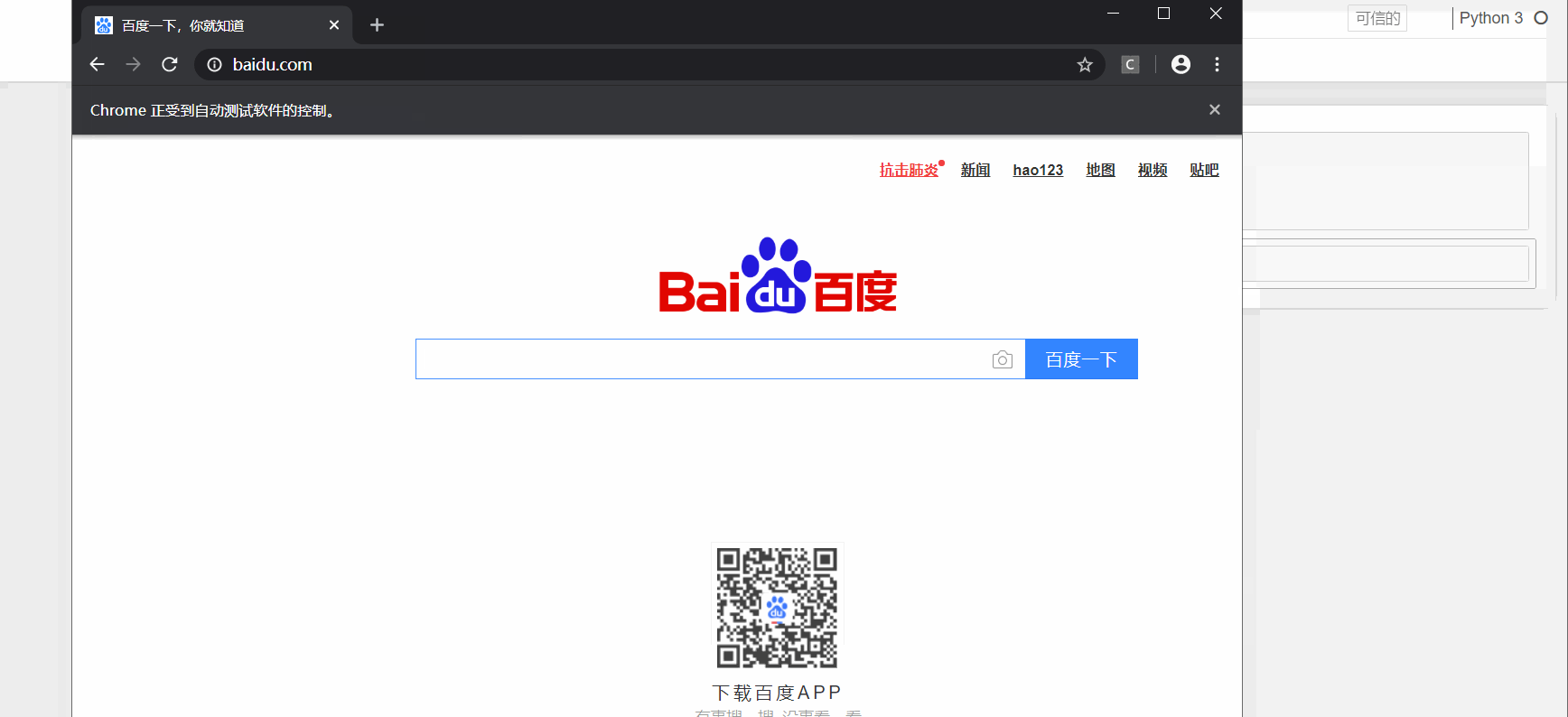
执行该代码之后,自动打开你输入的网址
dr.get('http://www.baidu.com')
关闭浏览器
在工作结束后常常需要关闭浏览器,关闭浏览器的方式有两种:
- close():关闭当前的浏览器窗口
- quit():不仅会关闭浏览器窗口,还会彻底的退出webdriver,释放与driver server之间的连接,释放所有的资源
from selenium import webdriver
#谷歌浏览器
dr = webdriver.Chrome()
#打开网页
dr.get('http://www.baidu.com')
#退出浏览器
dr.quit()
#dr.close()
最大化浏览器
from selenium import webdriver
import time
#谷歌浏览器
dr = webdriver.Chrome()
#打开网页
dr.get('http://www.baidu.com')
#最大化浏览器
dr.maximize_window()
#便于观察
time.sleep(3)
#退出浏览器
dr.quit()
#dr.close()

自定义浏览器大小
from selenium import webdriver
import time
#谷歌浏览器
dr = webdriver.Chrome()
#打开网页
dr.get('http://www.baidu.com')
dr.set_window_size(240, 320)
#便于观察
time.sleep(3)
#退出浏览器
dr.quit()
#dr.close()

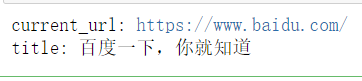
打印当前页面的信息
打印当前页面的title、url以及页面源码(源码过多就不进行展示了)
from selenium import webdriver
import time
#谷歌浏览器
dr = webdriver.Chrome()
#打开网页
dr.get('http://www.baidu.com')
print('current_url:',dr.current_url)
print('source:',dr.page_source)
print('title:',dr.title)
#便于观察
time.sleep(3)
#退出浏览器
dr.quit()
#dr.close()
实现浏览器前进和后退
后退会返回到当前网页的上一个网页,前进也会返回到当前网页的上一个网页
from selenium import webdriver
import time
import os
dr = webdriver.Chrome()
first_url = 'http://www.baidu.com'
dr.get(first_url)
print('current_url',dr.current_url)
time.sleep(1)
second_url = 'http://www.news.baidu.com'
dr.get(second_url)
print('current_url',dr.current_url)
time.sleep(1)
dr.back()
print("backing to %s"%(first_url))
time.sleep(1)
dr.forward()
print("forward to %s"%(second_url))
time.sleep(1)
dr.quit()

单对象定位
- find_element(),用于单对象定位。
- 对象的定位和操作是webdriver的核心内容,其中操作是建立在定位的基础之上,因此对象定位的地位就越发显得重要了
演示文档
打开百度首页→鼠标右键点击→查看网页源码

webdriver提供了一系列的对象定位方法,常用的有:
by_id
通过id定位需要用id的值定位
#通过id定位
print(dr.find_element_by_id('head').text)

by_name
通过name定位需要用name的值定位
#通过name定位
dr.find_element_by_name('mp')
by_class_name
通过class name定位需要用class name的值定位
#通过name定位
dr.find_element_by_name('mp')
by_tag_name
通过tag name定位需要用标签的值(如,<a>的值为a)定位
#通过tag name定位
print(dr.find_element_by_tag_name('div').text)

by_link_text
通过链接的文字描述来定位
如匹配下面图片中的新闻链接
dr.find_element_by_link_text("新闻")

by_css_selector
不懂css selector的可以点击了解或只用上面的方式CSS介绍
#获取标签名为div的标签
dr.find_element_by_css_selector('div')
by_xpath
不懂xpath的可以点击了解或用其他的方式xpath lxml库
dr.find_element_by_xpath('/html/body/form/div/label')
获取属性
获取div标签的id属性
dr.find_element_by_tag_name('div').get_attribute('id')
获取div标签的文本内容
print(dr.find_element_by_tag_name('div').text)
一组对象定位
find_elements(),常用于定位一组对象或批量操作对象,用法与前面的单对象定位(find_element())一致(不清楚的往前面翻就行)。
模拟用户操作
element.click()
模拟用户点击对象element
#
dr.find_element_by_link_text("新闻").click()
element.send_keys
模拟用户向名为p的文本框输入python
dr.find_element_by_name('q').send_keys('python')
element.clear()
模拟用户清除输入的内容
dr.find_element_by_name('q').clear()
模拟键盘输入
模拟用户在键盘上输入
from selenium.webdriver.common.keys import Keys
#模拟control+a
dr.find_element_by_id('p').send_keys((Keys.CONTROL, 'a'))
#模拟control+c
dr.find_element_by_id('p').send_keys((Keys.CONTROL, 'c'))
#模拟control+x
dr.find_element_by_id('p').send_keys((Keys.CONTROL, 'v'))
