1.redis持久化的方式有两种:RDB 和 AOF
RDB:类似于linux的快照,在某个时间点备份 临时文件 。
是把当前内存中的数据集快照写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里。
优点:1.每隔一段时间备份,全量备份
2.灾备简单,可以远程传输
3.子进程进行备份时,主线程不会有任何io操作(不会有写入修改或删除),保证备份数据的完整性
4.相对于AOF来说,当有更大文件的时候,就可以快速重启恢复
缺点:1.发生故障时,有可能会丢失最后一次的备份数据
2.子进程所占用的内存会和父进程一样,造成CPU负担
3.由于定时全量备份是重量级的操作,所以对于实时备份,就无法处理
触发机制:
1.手动触发:
手动触发也分别对应 save 和bgsave 命令:
1.1 save命令:
阻塞当前redis服务器,直到 RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
1.2 bgsave命令:
Redis进程执行fork操作 创建子进程,RDB持久化过程由子进程负责,完成后,自动结束。阻塞只发生在fork阶段,一般时间会很短。【bgsave命令是针对save阻塞问题做的优化,因此 Redis内部所有涉及 RDB 的操作都采用 bgsave的方式】
2.自动触发
自动触发模式:
找到: SNAPSHOTTING(快照)

接着往下找;
dir:就是定义的RDB所保存的位置,
保存在磁盘的名称 就是 dump.rdb

这就是 dump.rdb

回到 redis.conf:
保存 更改时间 发生的更改次数
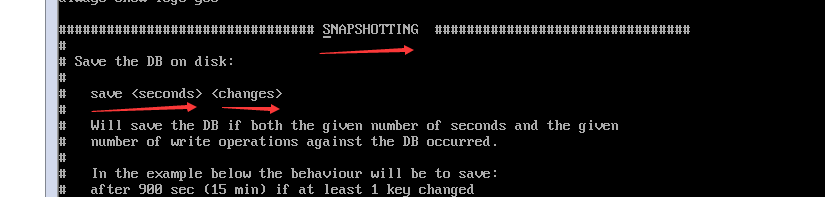
如果发生了 一次更改,则在15分钟后进行备份(保存快照),
如果至少发生了10次更改,则在5分钟后进行备份(保存快照)

如果在保存的过程中发生错误,yes就是停止写的操作。
no继续保存(会造成数据不一致)

stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩,会消耗CPU性能,但是现在企业的云盘性能一般都有剩余,所以不是大问题。
流程说明:
bgsave是主流的触发 RDB持久化方式,下面是他的运作流程:

1.执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如 RDB/AOF子进程,如果存在 ,bgsave命令直接返回。
2.父进程执行fork操作创建子进程,fork操作过程中,父进程会阻塞,【fork操作的耗时,单位为微秒】
3.父进程完成fork操作后,bgsave 命令返回 “Background saving started” 信息并且 不在阻塞父进程,可以继续响应其他命令。
4.子进程创建 RDB文件,根据父进程内存生产临时快照文件,完成对原有文件进行原子替换。
5.进程发送信号给父进程表示完成,父进程更新统计信息
