1.前言
由于数据的偏差与跨度会影响机器学习的成效,因此正规化(标准化)数据可以提升机器学习的成效
2.数据标准化
from sklearn import preprocessing #导入用于数据标准化的模块
import numpy as np
data = np.array([[13,54,7,-5],
[67,98,11,34],
[-56,49,22,39]],dtype = np.float64)
print(data)
print(preprocessing.scale(data)) #preprocessing.scale实现数据标准化
#
[[ 13. 54. 7. -5.]
[ 67. 98. 11. 34.]
[-56. 49. 22. 39.]]
[[ 0.09932686 -0.59050255 -0.99861783 -1.40657764]
[ 1.17205693 1.40812146 -0.36791183 0.57618843]
[-1.27138379 -0.81761891 1.36652966 0.83038921]]
数据标准化后服从均值为0,方差为1的正太分布
data_ = preprocessing.scale(data)
print(data_.mean(axis = 0))
print(data_.std(axis = 0))
3.对比标准化前后
from sklearn import preprocessing #导入用于数据标准化的模块
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets.samples_generator import make_classification #用于生成数据的模块
from sklearn.svm import SVC
import matplotlib.pyplot as plt
X, y = make_classification(n_samples=400,n_features=2,n_redundant=0,n_informative=2,random_state=42,n_clusters_per_class=1,scale=100) #特征个数= n_informative() + n_redundant + n_repeated
plt.scatter(X[:,0],X[:,1],c=y)
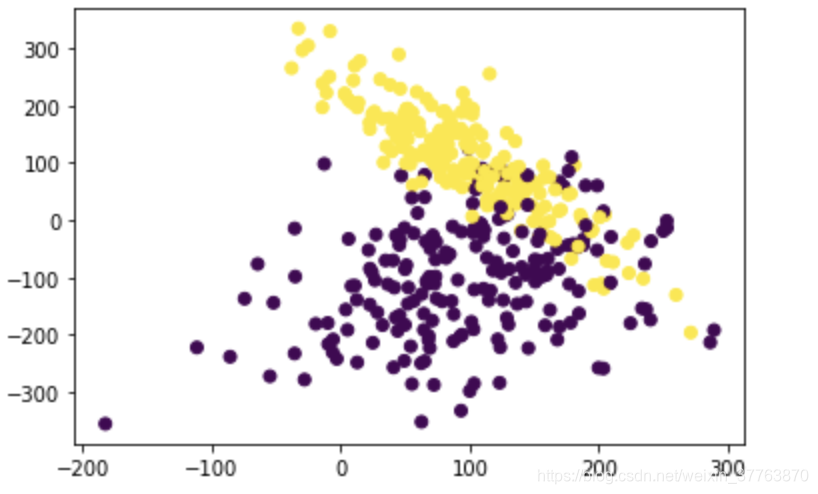
3.1.数据标准化前
x_train, x_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
model = SVC()
model.fit(x_train, y_train)
print("分类准确度:",model.score(x_test, y_test))
#输出
分类准确度: 0.48333333333333334
标准化前的预测准确率只有0.48
3.2.数据标准化后
数据的单位发生了变化, X 数据也被压缩到差不多大小范围.
X = preprocessing.scale(X)
x_train, x_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
model = SVC()
model.fit(x_train, y_train)
print("分类准确度:",model.score(x_test, y_test))
#输出
分类准确度: 0.9166666666666666
标准化后的预测准确率提升至0.92
