一、概述
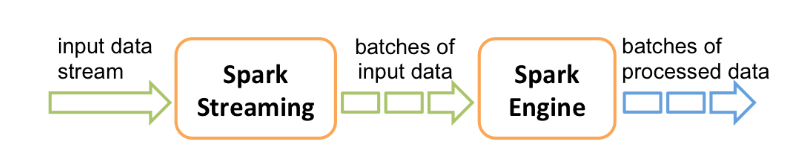
Spark Streaming是Spark Core功能拓展,可以实现数据流的可扩展、高吞吐、容错处理。SparkStreaming处理的数据可以来源于多种数据源(如:Kafka、Flume、TCP套接字),这些数据流经过流式计算的复杂处理和加工,最终会将计算的结果存储到文件系统、数据库或者在仪表盘进行数据的实时展示。

在内部,SparkStreaming会将接受的流数据拆分为一个个批次数据(micro batch),通过Spark引擎处理微批RDD,产生最终的结果流。
在Spark Streaming中有一个高等级的抽象称为离散流或者DStream。DStream可以通过外部的数据源构建或者转换获得新的DStream(类似于Spark RDD的使用);
结论:DStream底层是由Seq[RDD]序列构成
二、DStream离散流原理
DStream是Spark Streaming中最为核心的抽象,表现为一段连续的数据流(本质上是一组连续的RDD的序列集合),一个DStream中的一个RDD含有一个固定间隔的数据集。

应用在DStream上的任何操作底层都会转换为RDD的操作。

核心思想:微批 思想,底层使用spark rdd处理离散数据流
三、Input Source和Receivers
Input DStream表示从数据源接受的数据构建的DStream对象
构建Input DStream两种方式:
- basic source: 通常不依赖第三方的依赖可以通过ssc直接创建,如:filesystem和socket
- advanced source: 通常需要集成第三方依赖,如:kafka、flume其它流数据存储系统
basic source(基本数据源):
- 文件系统创建(使用HDFS API从任意的文件系统读取文件目录数据,作为DStream数据源)
// 通过文件系统构建DStream 注意:路径指向一个目录而不是一个具体的文件
val lines = ssc.textFileStream("hdfs://xxx:9000/data")
注意:
- 路径是一个目录,不是具体的文件
- 数据目录支持通配符,如:
hdfs://xxx:9000/data*;- 数据文件格式必须保证统一,建议文本类型
- TCP Socket套接字
val lines = ssc.socketTextStream("localhost",8888)
- RDD Queue(RDD队列,可以将多个RDD存放到一个Queue队列中构建DStream)
// 注意:ssc中封装了sparkContext可以直接获取 无需手动创建
val rdd1 = ssc.sparkContext.makeRDD(List("Hello Spark","Hello Kafka"))
val rdd2 = ssc.sparkContext.makeRDD(List("Hello Scala","Hello Hadoop"))
// 通过Queue封装RDD,创建一个DStream
val queue = scala.collection.mutable.Queue(rdd1,rdd2)
val lines = ssc.queueStream(queue)
advanced source(高级数据源):
- 基于kafka
(1).导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.4</version>
</dependency>
(2).开发应用
package source
import org.apache.kafka.clients.consumer.{ConsumerConfig}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010._
object KafkaSource {
def main(args: Array[String]): Unit = {
//1. 初始化ssc
val conf = new SparkConf().setAppName("kafka wordcount").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
//2. 初始化kafka的配置对象
val kafkaParams = Map[String,Object](
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,classOf[StringDeserializer]),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,classOf[StringDeserializer]),
(ConsumerConfig.GROUP_ID_CONFIG,"g1")
)
//3. 准备Array 填写需要订阅的主题Topic
val arr = Array("spark")
//4. 通过工具类初始化DStream
val lines = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent, // 位置策略 优化方案
ConsumerStrategies.Subscribe[String,String](arr,kafkaParams)
)
//5. 对数据的处理
lines
// kafka record(数据) ---> value
.map(record => record.value())
.flatMap(_.split("\\s"))
.map((_,1))
.groupByKey()
.map(t2 => (t2._1,t2._2.size))
.print()
//6. 启动streaming应用
ssc.start()
//7. 优雅的停止应用
ssc.awaitTermination()
}
}
(3).启动kafka服务,并且启动消息的生产者
# 启动zk
bin/zkServer.sh start conf/zoo.cfg
# 启动kafka
bin/kafka-server-start.sh -daemon config/server.properties
# 创建spark topic
bin/kafka-topics.sh --create --topic spark --bootstrap xxx:9092 --partitions 1 --replication-factor 1
Created topic "spark".
# 启动spark topic的生产者
bin/kafka-console-producer.sh --topic spark --broker-list xxx:9092
- 基于Flume
(1).flume配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 9999
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(2).导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.11</artifactId>
<version>2.4.4</version>
</dependency>
(3).开发应用
package source
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumeSource {
def main(args: Array[String]): Unit = {
//1. 初始化ssc
val conf = new SparkConf().setAppName("kafka wordcount").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
//2. 通过Flume的工具类初始化DStream
val dstream = FlumeUtils
.createStream(ssc, "localhost", 9999)
// event body内容封装到 String
dstream
.map(event => new String(event.event.getBody.array()))
.print()
//6. 启动streaming应用
ssc.start()
//7. 优雅的停止应用
ssc.awaitTermination()
}
}
(4).启动Flume Agent采集数据
bin/flume-ng agent --conf conf --conf-file conf/simple.conf --name a1 -Dflume.root.logger=INFO,console
(5).启动telnet服务,发送启动数据
telnet localhost 44444
Hello Spark
OK
Hello Spark
OK
四、DStreams输出操作
输出操作指将DStream处理结果写出到外部的存储系统,如:数据库或者Redis、HDFS、HBase等等;
saveAsTextFiles(prefix, [suffix]):(将DStream的内容以文本文件的形式保存到应用的所在目录)
saveAsObjectFiles(prefix, [suffix]):**(将DStream的内容以序列化文件的形式保存到应用的所在目录)
lines
.flatMap(_.split("\\s")) // DStream ----> DStream
.map((_, 1L))
.groupByKey()
.map(t2 => (t2._1, t2._2.size))
// DStream的计算结果保存到应用的运行目录中
//.saveAsTextFiles("result", "xyz")
.saveAsObjectFiles("result", "xyz")
saveAsNewAPIHadoopFiles(prefix, [suffix]):(注意:结果保存在HDFS:`/user/用户名/)
lines
.flatMap(_.split("\\s")) // DStream ----> DStream
.map((_, 1L))
.groupByKey()
.map(t2 => (t2._1, t2._2.size))
.saveAsNewAPIHadoopFiles(
"result",
"xyz",
classOf[Text],
classOf[LongWritable],
classOf[TextOutputFormat[Text, LongWritable]],
conf = hadoopConf)
foreachRDD(func):(遍历处理DStream中的批次对应的RDD,可以将每一个微批的RDD的数据写出到任意的外部存储系统,如数据库或者Redis)
lines
.flatMap(_.split("\\s")) // DStream ----> DStream
.map((_, 1L))
.groupByKey()
.map(t2 => (t2._1, t2._2.size))
.foreachRDD(rdd => {
// 将计算的结果保存到redis中
//方法一: rdd输出的操作 一个分区对应一个jedis连接(建议使用)
rdd.foreachPartition(itar => {
val jedis = new Jedis("localhost", 6379)
while (itar.hasNext) {
val tuple = itar.next()
val word = tuple._1
val count = tuple._2
jedis.set(word, count.toString)
}
jedis.close()
})
//方法二: 一个值对象一个Redis连接
/*rdd.foreach(t2 => {
val jedis = new Jedis("localhost", 6379)
jedis.set(t2._1, t2._2.toString)
jedis.close()
*/
})
})
备注:
在Spark Streaming应用中不要使用local[1]作为Master URL地址,如果这样做的话,意味着只有一个线程用来接受流数据,而没有可供进行数据处理的线程。所以,线程的数量需要大于等于2,如:local[2]或者local[*]
