来源:
《微服务架构实战160讲》
https://blog.csdn.net/qq_25484147/article/details/83375225
https://blog.csdn.net/qq_23181091/article/details/80785453
https://cloud.tencent.com/developer/article/1477400
容错限流:Hystrix
1 解决的问题
微服务下,假设每个服务的可用性为四个9,总体可用性肯定会有所下降,导致时不时地会有一段时间不可用,比如每个请求都依赖很多服务,如果某个服务延迟很慢,那么用户请求都会阻塞在这里,用户体验很差,即“高峰期雪崩效应”
2 容错限流原理
-
基本的容错模式:五种方法
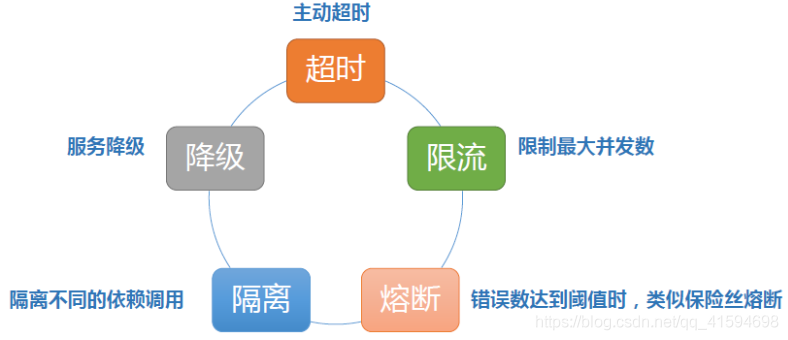
-
断路器模式
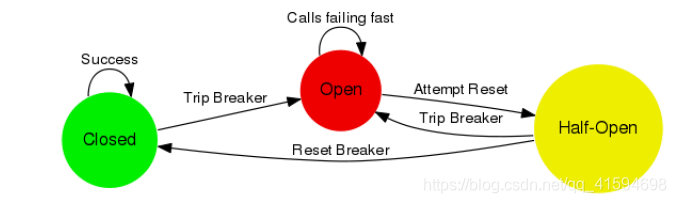
原理是一个状态机,三种状态进行切换 -
舱壁隔离(Bulkhead)模式
对资源进行失败单元的隔离,每个或若干个失败单元出问题都不影响整体
- 容错理念
1 凡是依赖都可能会失败(这也是写代码时要考虑健壮性的原因,如判空)
2 凡是资源都有限制: CPU/Memory/Threads/Queue
3 网络并不可靠
4 延迟是应用稳定性差的主要原因(延迟会占据大量的资源)
5 弹性理念:出问题后恢复原状的能力
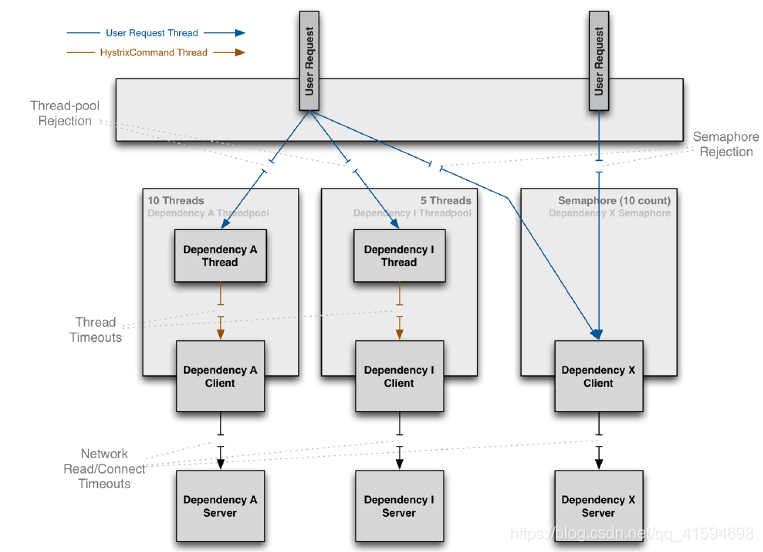
- 限流:线程和信号量隔离
线程池隔离:为每个服务创建一个线程池
信号量隔离:一个服务拥有一个计数器,一个请求代表一个数
- 请求熔断
当Hystrix Command请求后端服务失败数量超过一定比例(默认50%),断路器会切换到开路状态(Open);
此时所有请求会直接失败而不会发送到后端服务.;
断路器保持在开路状态一段时间后(默认5秒),,自动切换到半开路状态(HALF-OPEN),这时熔断器只允许一个请求通过.;
当该请求调用成功时,,熔断器恢复到关闭状态, 若该请求失败, 熔断器继续保持打开状态,,接下来的请求被禁止通过;
如此循环反复
- 服务降级
Fallback相当于是降级操作.;
对于查询操作,可以实现一个fallback方法,当请求后端服务出现异常的时,可以使用fallback方法返回的值.;fallback方法的返回值一般是设置的默认值或者来自缓存,告知后面的请求服务不可用了,不要再来了。
3 架构设计
- 工作流程:自适应反馈机

流程中会判断电路是否打开?线程池/队列是否满了?超时?等状况,如果失败,则进入getFallback()
最后这些状况都会报告给Calculate Circuit Health,提供下次判断的依据
Hystrix命令模式封装了命令运行逻辑(run)和服务调用失败时回退逻辑(getFallback)。
其command抽象类是HystrixCommand,用于包装执行具有潜在风险功能的代码(通常指通过网络进行的服务调用),具备容错和延时,统计和性能指标捕获,断路器和舱壁功能。
getFallback即熔断之后的降级流程,可以看到熔断和降级在Hystrix中是相结合的
- 内核设计:一秒一个的滚筒式设计
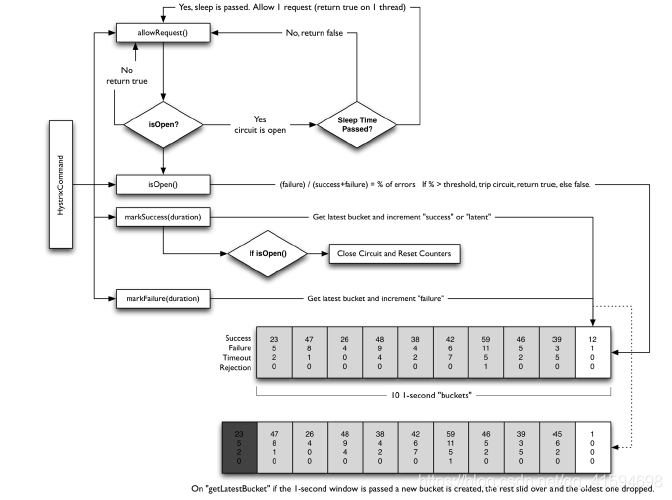
一秒产生一个新桶,统计”成功”“失败”“超时“”拒绝”的请求个数
每次请求进行先到达allowRequest,如果isOpen为false,则可以通过,执行一个请求
isOpen()计算错误率是否超过阀值,如果超过则close circuit
滚筒即Metrics,有两个,一个是现在的,一个是新生成的,用来统计信息,即Calculate Circuit Health
4 参考部署
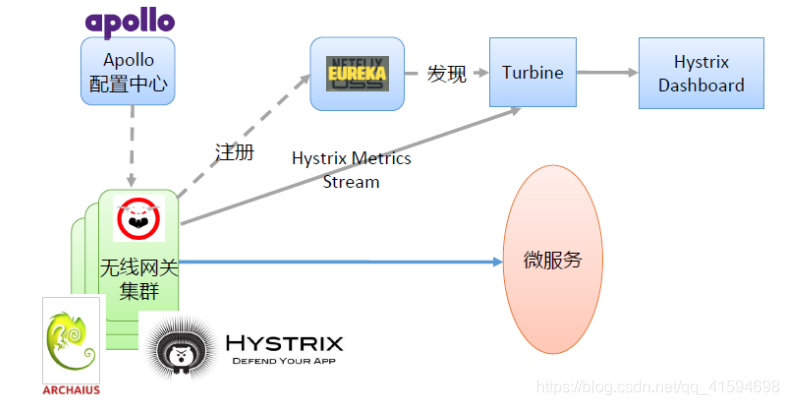
turbine:聚合Hystrix的流,通过Eureka发现网卡的实例,发起流的连接,通过apollo动态地调配Hystrix的配置(每个微服务的配置不同,使用apollo集中配置好一点)
