一、自动化测试
软件自动化测试就是通过测试工具或者其他手段,按照测试人员的预定计划对软件产品进行自动化测试,能够快速,全面的对软件进行测试,从而提高软件质量,节省经费,缩短软件的发布周期。测试自动化意味着使用测试工具
二、优点
- 缩短测试周期
- 避免人为出错
- 测试信息存储
- 轻易获取覆盖率
- 其他
三、分类
- 自动化功能测试
单元测试
功能测试(Web功能测试,移动端功能测试)
接口测试(工具:jmeter) - 自动化性能测试(工具:Loaderunner,jmeter)
四、使用条件
- 手动测试已经完成,后期再不影响进度的前提下逐渐实现自动化
- 项目周期长,重复性的工作都交给机器去实现
- 需求稳定,项目变动不大
- 自动化测试脚本复杂度比较低
- 可重复利用
五、应用场景
- 频繁的回归测试(开发者修改返回后的再次测试)
- 冒烟测试(所有功能测试一遍)
- 互联网迭代频繁
- 传统行业需求变化不大,应用频繁(政府企业)
六、Web自动化测试工具
- QTP(收费)
- Selenium(开源)
- RFT(收费,功能和回归测试工具)
- Watir(开源)
- Sahi(开源)
七、QTP VS Selenium

八、CSS选择器
-
概念
CSS 中,选择器是一种模式,用于选择需要添加样式的元素。计算机能够通过css选择器定位到相应元素,我们在编写自动化测试脚本的时候很多时候是在不断地找到css选择器。 -
语法
-
1)通过伪类名、id、标签名定位

eg:
① .topbe-wrapper # 定位class(类选择器)属性值为topbe-wrapper的节点
② #topbeWrapper # 定位id(id选择器)的属性值为topbeWrapper 的节点
③ * #通配符,会选择所有标签(Xpath://*)
④ div # 选择所有的div标签(对比于Xpath选择器,无绝对路径)
- 2)通过元素之前嵌套关系
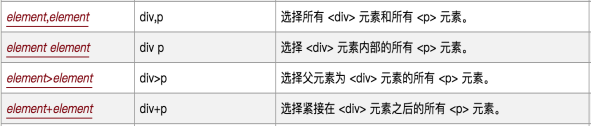
eg:
①meta,link # 选择所有的meta和link标签(Xpath://mea|//link)
②div a # 定位div所有子孙标签中的a标签(后代选择器)
③div>a #定位所有div标签的子标签是a标签的节点(父代选择器)(父子关系)
④div>div>a #多层嵌套关系(爷父孙关系)
⑤div+p #同属于一个父节点(后紧接着)(同胞节点)
- 3)通过属性

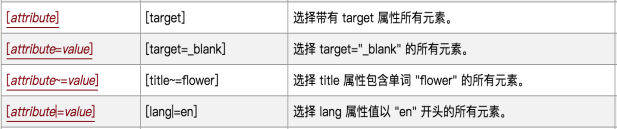
Eg:
①[id] # 定位所有具有id属性值的标签(Xpath: //[@id])
②[target="_blank"] # 定位所有含有target属性,并且属性值为"_blank"的标签(Xpath: //[@target="_blank"])
③[class=“mnav”] # 定位所有含有class属性,并且属性值含有mnav独立单词的标签(每个单词之间用空格隔开)
注意:属性值中不能含有连字号,或下划线
④[type|=“text”] #定位所有具有type属性,且type的属性值以text开头的标签
(Xpath://[starts-with(@type,’text’)])
⑤[style^=‘display:non’] # 定位所有style属性中以display:non开头的属性值标签
⑥[style$=’:none;’] #定位所有style属性中以:none;结尾的属性值标签
⑦[id=‘user’] # 定位所有id属性中属性值有user的标签
注意
①默认所有属性值均带双引号
②[attribute|= value] 和 [attribute@= value]的区别
[attribute|=value]必须是选取整个单词或者中间有连字符的单词
[attribute^=value] 无此限制!
- 4)通过父子关系
Eg:
① div:only-child # 定位div标签的父标签只有一个子标签div标签的父节标签
②div:nth-child(2) # 定位其父节点的第二个子节点是div节点的子节点
③div:nth-last-child(2) # 定位其父节点的倒数第二个节点是div的节点
④*:only-child # 定位所有父节点只有一个子节点的子节点
注意
以上通过父子关系定位的节点均定位的是子节点
- 5)元素状态(很少用到)
Eg:
①div:empty # 定位所有没有子节点的div标签
②not(link) # 定位所有不是link的节点
九、Xpath选择器
- 概念
XPath即为XML路径语言,它是一种用来(标准通用标记语言的子集)在 HTML\XML 文档中查找信息的语言。
- 语法
- 1)常用

Eg:
①//meta //meta[@name] //meta[@name=’msapplicationTileColor’]
②/html/meta/body
②/html/meta/body/…
③/html/body/[@style]
- 2)索引

Eg:
①.//[@id=‘endtext’][1] # 符合条件的第一个元素(从1开始)
②.//[@id=‘endtext’][last()] # 符合条件的最后一个元素
③.//[@id=‘endtext’][last()-1] # 符合条件的倒数第二个元素
④.//[@id=‘endtext’][position()] # 符合条件的所有元素(等同于.//[@id=‘endtext’])
⑤.//[@id=‘endtext’][position()=3] # 符合条件的第三元素(等同于.//[@id=‘endtext’][3])
⑥.//[@id=‘endtext’][position()>3] # 符合条件的除前三个以外的所有元素
⑦//span[i=459] #利用span子节点i的值来查找
//span[i>459]
- 3)通配符

Eg:
① //* # 匹配所有的标签
②/* # 匹配绝对路径最外层(根节点的第一个子节点html)
③//[@] #匹配所有具有属性的节点
④//div[@] #匹配所有div标签中具有属性的节点
⑤/html/node()/meta # 匹配html标签中所有子孙标签中的meta标签(node()相当于)
⑥/html/*/meta # 匹配html标签中任意节点(标签)下的meta标签(等同于上一个写法)
- 4)或
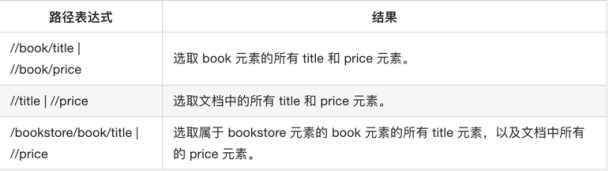
Eg : //meta|//script|//link #同时定位多个元素
- 5)其他

Eg:
① //[text()=’靖国英雄花木兰’]
② //[starts-with(@href,‘http’)] # 定位属性href的属性值以http开头(也可写整个属性值)
③//[contains(@href,’//gss0.bdstatic.com’)] #定位属性href的属性值中含有//gss0.bdstatic.com的元素
④//[(@href=“https://gss1.bdstatic.com” and @ rel=“dns-prefetch” )] # 同时符合两个条件
