本文简要叙述当前流行的Bregman迭代算法的一些原理。
1、简介
近年来,由于压缩感知的引入,L1正则化优化问题引起人们广泛的关注。压缩感知,允许通过少量的数据就可以重建图像信号。L1正则化问题是凸优化中的经典课题,用传统的方法难以求解。我们先从经典的图像复原问题引入:
在图像复原中,一种通用的模型可以描述如下: 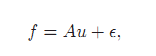
f:观测到的图像(m维向量)
u:未知的真实图像(n维向量)
A:线性算子,例如反卷积问题中的卷积算子,压缩感知中则是子采样测量算子。
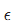
在式(1)中,我们仅知道观察到的图像f,其他的一概不知。因此这种问题是病态的,我们可以通过正则化把它变成良态的。
正则化方法:
假定对未知的参数 μ 引入一个先验的假设,例如稀疏性,平滑性。正则化问题的常见方法Tikhonov方法,它通过求解下面的优化问题:
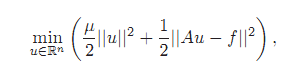
其中 μ 是一个大于零的标量,事先设定的常数,用于权衡观测图像f和正则项之间的平衡。双绝对值符号是L2范数。L2条件约束。
下面,为了引入Bregman迭代算法,需要对两个重要的概念进行描述(次梯度和Bregman距离)。
2、Bregman距离
这里先复习一下梯度和导数的概念:
导数:lim(△x->0) ( f(x+△x) - f(x) ) / △x
方向导数:lim( dis(P0,P1) ->0) ( f(P1) - f(P0) ) / dis(P0,P1)。。上面讲的导数就是沿着 x 轴 方向的方向导数。
!!导数是 f(x) 在某个方向的变化率,是一个值,标量。梯度:沿方向导数最大值的方向,大小为该方向导数的值。
!!梯度是一个向量。
次梯度
subgradient(次梯度,又称子梯度、弱梯度等),
泛函 J 在 u 点的次梯度定义如下:
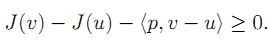
J: X->R, 凸函数。
u:作用域X中的一点。
v:作用域 X 中的任一点。
p:X 的对偶空间 X* 的中的某一点。 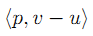
J 在 u 点的所有次梯度的集合成为 J 在 u 点的次微分,记为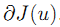
次梯度有什么好处呢?
对于一般的导数定义,例如 y=|x| 在0点是不可导的,但是对于次梯度,它是存在的。
Bregman距离
点u和v之间的Bregman距离定义如下:
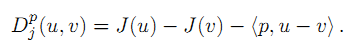
J:X->R, 凸函数。 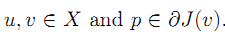
凸函数两个点u,v之间的Bregman距离:等于其函数值之差,再减去其次梯度点p与自变量之差的内积。
注意:这个距离不满足对称性,这和一般的泛函分析中距离定义是不一样的。
!!Bregman 距离有一些十分良好的性质,使得他在解决 L1 正则化问题时十分有效。
2. Bregman距离

注意这个定义,它是对泛函J在u点的subgradient的定义,p点是其对偶空间的中的某一点。subgradient可以翻译为次梯度,子梯度,弱梯度等。等式左边最右边一项是内积运算。如果泛函J是简单的一元函数,则就是两个实数相乘。次梯度有什么好处呢?对于一般的导数定义,例如y=|x|在0点是不可导的,但是对于次梯度,它是存在的。

上面的这个定义就是Bregman距离的定义。对于凸函数两个点u,v之间的Bregman距离,等于其函数值之差,再减去其次梯度点p与自变量之差的内积。要注意的是这个距离不满足对称性,这和一般的泛函分析中距离定义是不一样的。
3、Bregman迭代算法
要解决的问题:求u(最小化)
Bregman迭代算法可以高效的求解下面的泛函的最小值问题。
J:X->R, 凸函数,非负。u∈X。
H:X->R, 凸函数,非负。u∈X,f 是已知常数(通常是一个观察得到的图像数据,是矩阵或向量)。
X:作用域,是凸集也是闭集。
注意:上述泛函会根据具体问题的不同具有不同的具体表达式。例如,对于简介中的图像复原问题, J(u) 是平滑先验约束,是正则化项;而H则是数据项。
Bregman迭代算法

首先,初始化相关的参数为零;
然后,再迭代公式u。。直到 uk 满足收敛条件。
u,左边一项是泛函 J 的Bregman距离。
p,右边一项是泛函 H 的梯度(次梯度)。
可以看出:
· 第一次迭代,
u1=argmin(u) { D(u, 0) + H(u) }, 其中D(u, 0)=J(u) - J(0) - <0, u>=J(u) 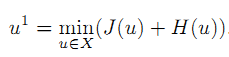
· 再经过多次的迭代,
就能够收敛到真实的最优解。
对于具体的问题: 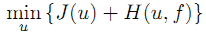
例如对于压缩感知使用的基追踪算法,J是L1范数;
而对于图像去噪问题,可能就是u的梯度L1范数,同时A也变成了恒等算子了。
3. Bregman迭代算法
Bregman迭代算法可以高效的求解下面的泛函的最小

上式中的第一项J,定义为从X到R的泛函,其定义域X是凸集也是闭集。第二项H,定义为从X到R的非负可微泛函,f是已知量,并且通常是一个观测图像的数据,所以f是矩阵或者向量。上述泛函会根据具体问题的不同具有不同的具体表达式。例如,对于简介中的图像复原啊问题,J(u)就是平滑先验约束,是正则化项;而H则是数据项。


Bregman迭代算法首先是初始化相关的参数为零,再迭代公式u,其左边一项是泛函J的Bregman距离。再来看p点的迭代公式,其最右边一项是泛函H的梯度。
其迭代一次产生的输出是公式3.2,经过多次的迭代,就能够收敛到真实的最优解。这个证明过程可以参考后面的文献。
对于具体的问题,泛函3.1定义的具体形式是不同的。例如对于压缩感知使用的基追踪算法,J是L1范数。而对于图像去噪问题,可能就是u的梯度L1范数,同时A也变成了恒等算子了。
4、线性Bregman迭代算法
Bregman算法对于基追踪问题来说是一种很好的工具。但是,算法中的每一步都要求解公式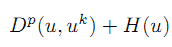
因此提出了——
线性Bregman迭代算法推导
首先,利用矩阵的泰勒公式,将公式
中的 H(u) 线性展开,得到:
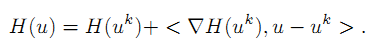
但是这种近似展开只有在u和uk十分接近的时候上式才准确。因此,把泰勒公式中的二次项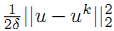
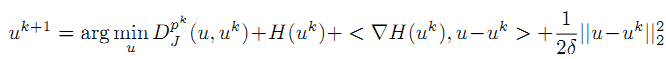
可以看到,二次项可以使 u 和 uk 很靠近。因为向量的平方就是L2范数的平方。
又因为:
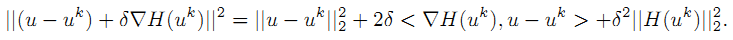
注意 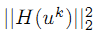
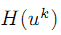
所以,
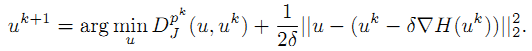
考虑基追踪算法,令 H(u) =
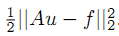
得到:
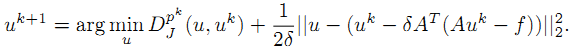
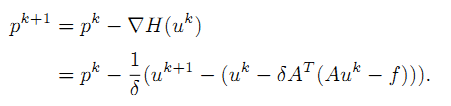
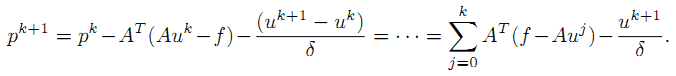
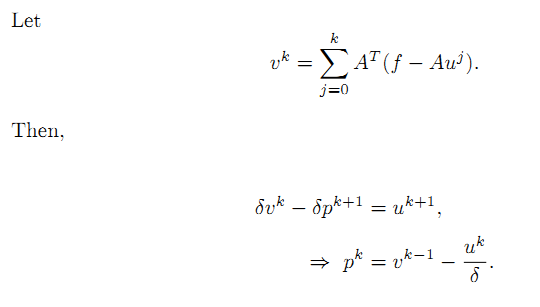
考虑该式的一个特殊情况,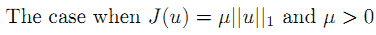
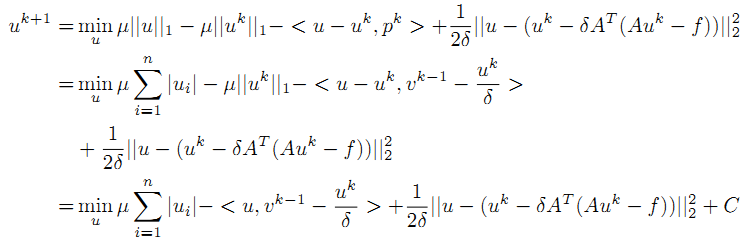
C是一个常量,与uk有关的常量。uk也是一个常量。
分3种情况来考虑 u,则
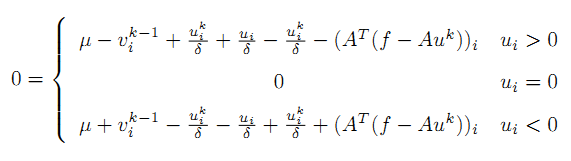
进一步整理,得到:
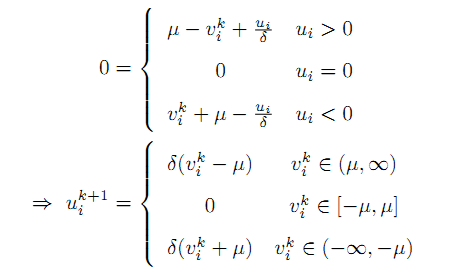
定义shrink算子,当a>0时,有:
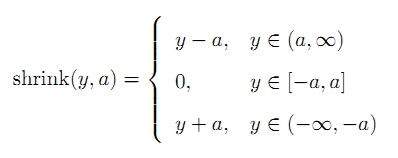
线性Bregman算法总结

4. 线性Bregman迭代算法


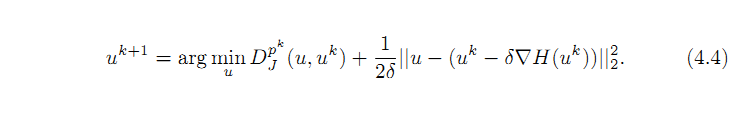
注意,上述公式4.2省略了泰勒公式中二次项。把二次项加上,带入前面基本的Bregman迭代算法公式的第一步,我们得到公式4.3。如果我们计算4.3和4.4中间那个表达式,比较其相同项,很容易得到公式4.4.

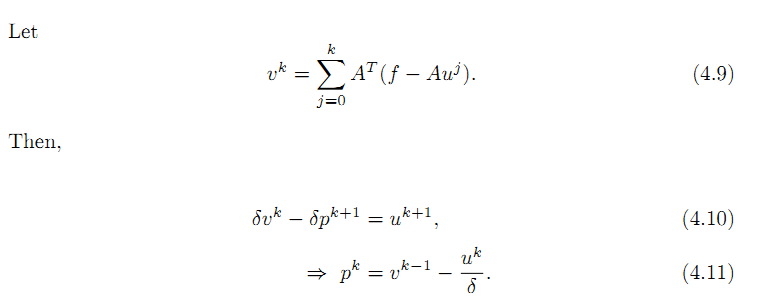
如果我们考虑基追踪算法,则H等于 ||Au - f||^2 /2, 将H的导数带入公式4.4,我们得到公式4.5, 公式4.6是基本Bregman迭代算法的第二步,注意上述4.6公式中u的上标是错的,应该改为 k+1 ,这样才可能得到公式4.7,公式4.8,4.9, 4.10, 4.11都是显而易见的。
下面我们把4.11和前面定义的Bregman距离带入到4.5里面去,具体如下:

在上面的推导中,u_k是常量,C是与u_k有关的一个常量,将上式对u求导,由于有绝对值项,所以要分开讨论,得到上面这个分段表达式。进一步整理得到:
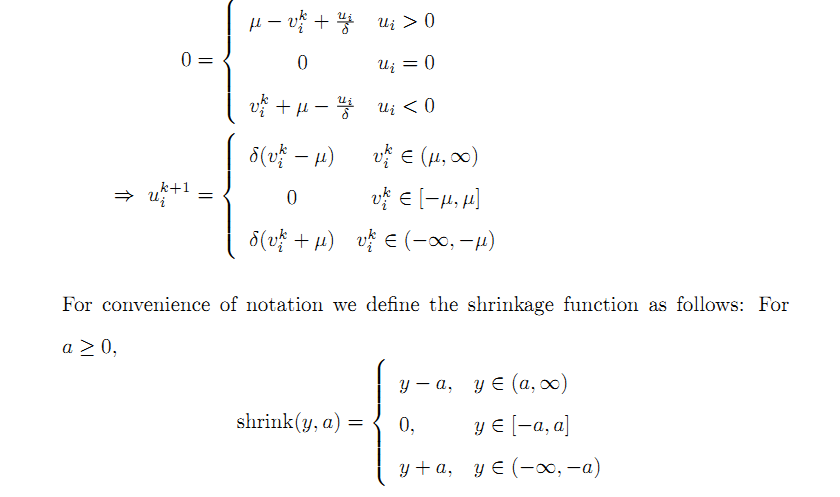
这里,我们定义了一个shrink操作,这个收缩算子很重要,在后面所有的Bregman算法中都有这个操作。根据这个操作,我们导出下面的表达式,并最终把线性Bregman迭代算法总结如下:

5. Split Bregman 算法
Split Bregman 算法是另一种高效的算法。我们已经知道,Bregman迭代算法用于求解下面的凸优化问题:
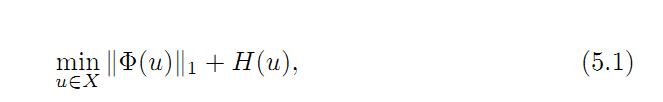
我们可以把上面的表达式变换为下面的等价形式:
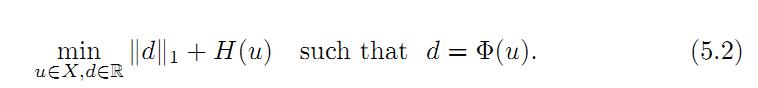
这一步,看似是多此一举,但是Bregman经过推导,得出了一种高效的迭代算法,分裂Bregman迭代。
上面的5.2是一个等式约束优化问题,把它转化为无约束优化问题如下:

上面这个公式中,优化变量多了一个d。做如下的变量替换:
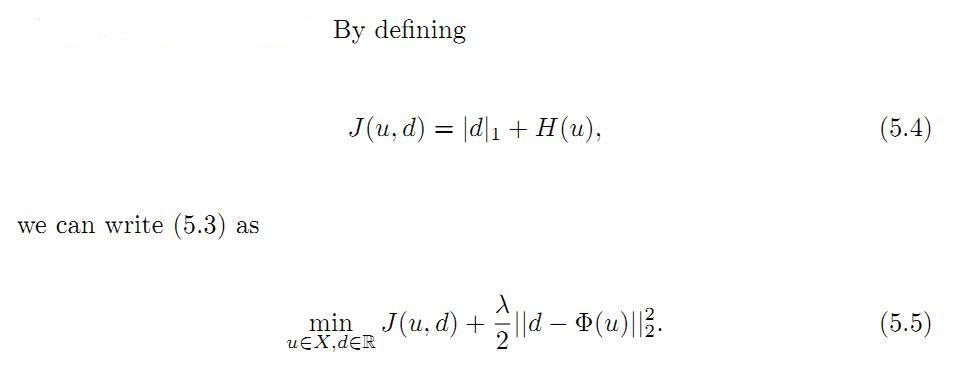
如果我们对5.5,应用最前面提到Bregman 迭代算法,很容易写出下面的迭代序列:

式5.9是根据5-6按照Bregman距离展开的结果。式5.7,5.7后面一项是对5-5分别对u,d求其偏导数得到。如果我们对5.7迭代展开,于是得到:
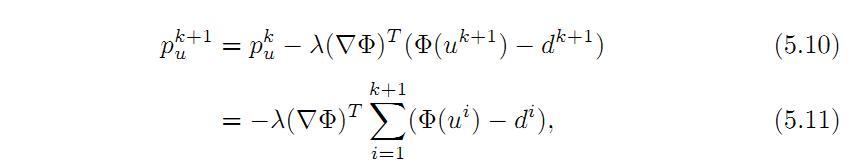
同理,对于5.8,有

注意到式5.11和5.12有一个公共的SIGMA求和项,把它重新定义如下:
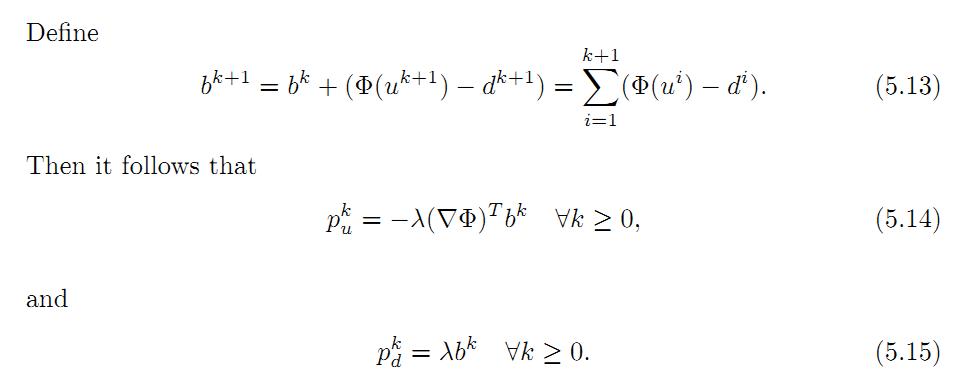
把5.14,5.15带入5.9,具体如下:
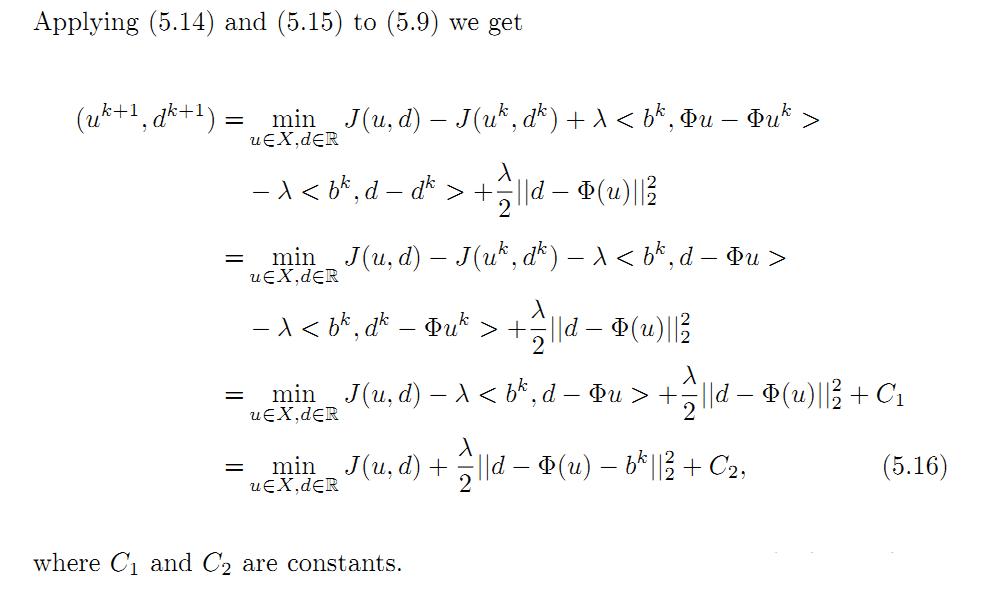
在对5.16的化简中,要注意的是u,d为变量,其它看做常量。
到此,我们可以给出Split Bregman迭代算法的通用优化步骤:

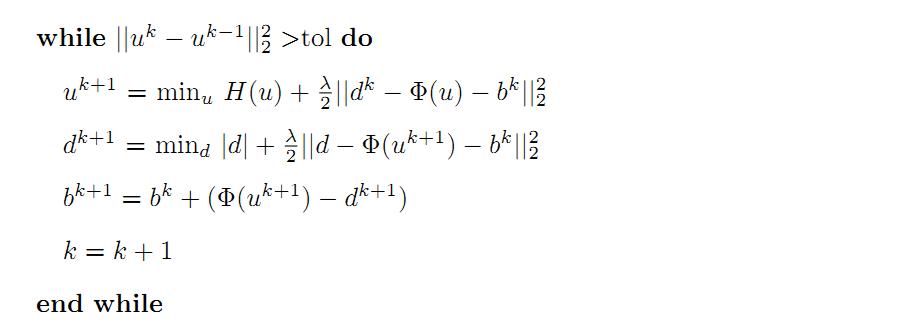
对u的迭代,把u看做自变量,其它所有变量看做常数,对d的迭代则是d为自变量,其它变量都是常数。 之所以说是通用迭代优化过程,是因为对于具体的问题,其迭代的具体表达式不同。例如,对于基于各向异性TV的去噪模型,各向同性TV去噪模型,其迭代的具体表达式是不同的。