字符编码与转码
详细文章:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.diveintopython3.net/strings.html
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节),utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
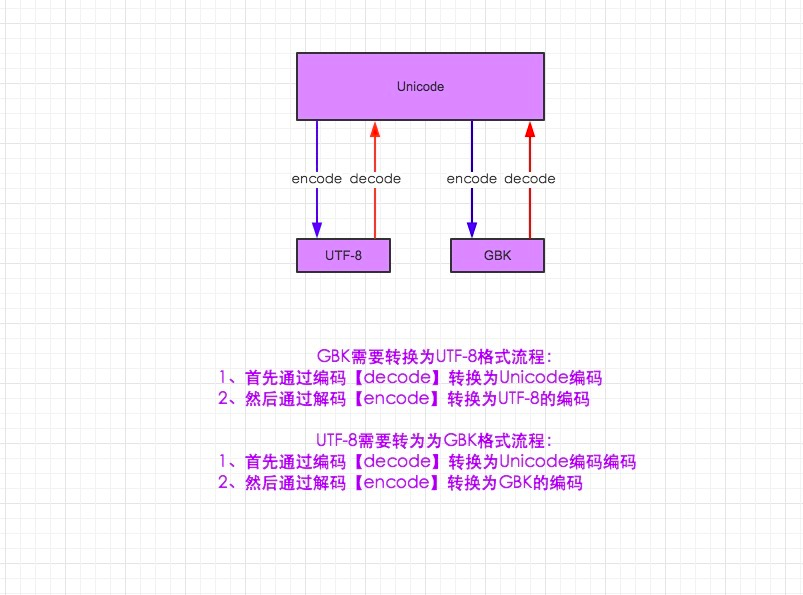
在python2中编码转换示例:
#编辑code 设置编码为utf-8 #/usr/bin/python #-*- coding:utf-8 -*- import sys print(sys.getdefaultencoding()) #打印系统默认编码 #设置视窗的编码现在为utf-8 str = "你好" print(str) str_to_unicode = str.decode("utf-8") #utf-8转换为unicode编码 print(str_to_unicode) str_to_gbk = str_to_unicode.encode("gbk") #unicode转换为gbk print(str_to_gbk) gbk_to_utf8 = str_to_gbk.decode("gbk").encode("utf-8") #gbk转换为utf-8 print(gbk_to_utf8) s = u"你好" #前面加一个u表示是utf-8编码 print(s) #将编码设置为utf-8编码后运行结果 [oracle@localhost ~]$ python str_code.py ascii 你好 你好 ţº 你好 你好 #将编码设置为gbk后运行结果 [oracle@localhost ~]$ python str_code.py ascii 浣.ソ 浣.ソ 你好 浣.ソ 浣.ソ
python3中编码转换
py3有两种数据类型:str和bytes; str类型存unicode数据,bytse类型存bytes数据,python中默认为unicode
#python3中默认为unicode编码 #解释器默认编码utf-8 import sys print(sys.getdefaultencoding()) #utf-8 s = "你好" #unicode编码 print(type(s)) #<class 'str'> #unicode转换为utf8 unicode_to_utf8 = s.encode("utf-8") print(unicode_to_utf8) #b'\xe4\xbd\xa0\xe5\xa5\xbd' utf8编码后的bytes类型 #转换为中文 print(unicode_to_utf8.decode("utf-8")) #需要声明现在的编码是utf8 #unicodez转换为gbk unicode_to_gbk = s.encode("gbk") print(unicode_to_gbk) #b'\xc4\xe3\xba\xc3' gbk编码后的bytes类型 #转换为中文 print(unicode_to_gbk.decode("gbk"))