nodeJs中常用的一些内置模块有:
- url,用于处理与解析 URL;
- querystring,用于解析和格式化 URL 查询字符串;
- http,HTTP服务;
- path,路径,用于处理文件路径和目录路径;
- events,事件触发器,用于事件的派发与监听;
- fs,文件系统,用于文件的读写操作;
- ctypto,用于数据的加密和解密;
- stream,流
- zlib,压缩
1.url URL操作
1.1 new URL()
new URL(urlString,base),如果 urlString 是相对路径,则需要 base。 如果 urlString 是绝对路径,则忽略 base。它的部分属性如下:
- hostname,获取及设置 URL 的主机名部分,它和host的区别是,它不包含端口。
- pathname,获取及设置 URL 的路径部分,也就是端口号后面的所有内容。
- port,获取及设置 URL 的端口部分。http协议的默认端口号是80,https协议的默认端口号是443。ftp协议的默认端口号是21。
- search,获取及设置 URL 的序列化查询部分。也就是 ?号后面的所有内容,包含?号。
const myURL = new URL('https://example.org:8088/abc/foo#bar');
console.log(myURL.hash); //#bar
console.log(myURL.hostname); //example.org
console.log(myURL.pathname); //abc/foo#bar
const searchURL = new URL('https://example.org/abc?123');
console.log(searchURL.search); //?123
searchURL.search = 'abc=xyz';
console.log(searchURL.href); //https://example.org/abc?abc=xyz
在http请求中,可以使用new URL()来获取想要的数据:
- 第一个参数相当于
request.url; - 第二个参数相当于
request.headers.host;
let url=new URL("/user?name=haha&age=18", "http://localhost:8088");
//"/user?name=haha&age=18"相当于request.url
//"http://localhost:8088"相当于request.headers.host
console.log(url);
打印结果如下:
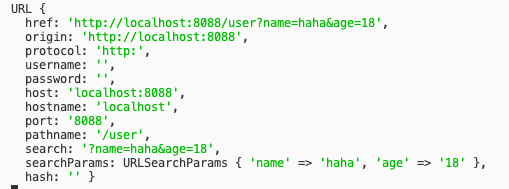
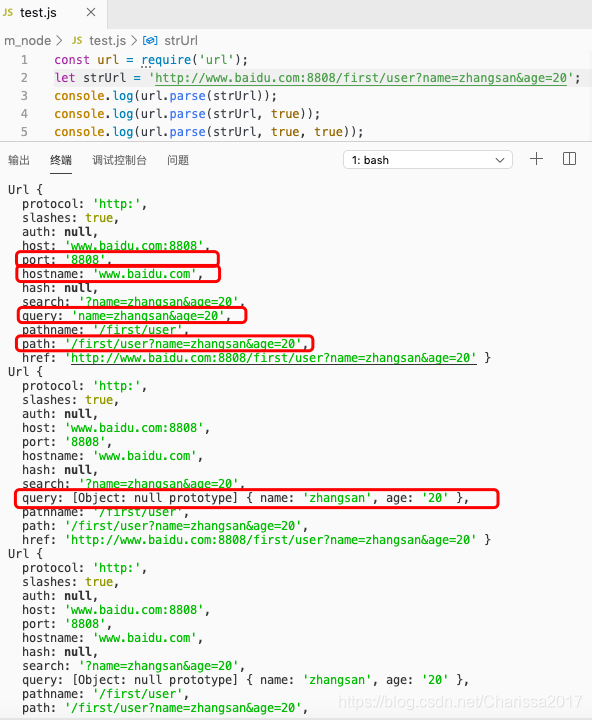
1.2 url.parse()
解析传进来的路径。
语法:url.parse(urlString, parseQueryString, slashesDenoteHost);
- urlString,url地址字符串。
- parseQueryString,布尔值,表示是否将url的query解析为js对象,默认为false,设置为true后,可以通过query属性获取参数对象。
- slashesDenoteHost,布尔值,如果为真,那么字符串//之后的第一个令牌和下一个/之前的第一个令牌将被解释为主机。例如,给定//foo/bar,结果应该是{host: ‘foo’, pathname: ‘/bar’}而不是{pathname: ‘//foo/bar’}。默认值:false。
详细内容如下图:
1.3 url.format(urlObject)
将传入的url对象,拼接成Url路径字符串;
const url = require('url');
var params = {
protocol: 'https:',
hostname: 'www.lagou.com',
port: '8080',
pathname: '/a',
search: '?name=zhangsan&age=20',
hash: '#position',
}
console.log(url.format(params));
//https://www.lagou.com:8080/a?name=zhangsan&age=20#position
1.4 url.resolve(from, to)
拼接url路径,按照第一个参数的目录路径来拼接,类似于path的resolve();
const url = require('url');
url.resolve('/one/two/three', 'four');
// '/one/two/four'
url.resolve('http://example.com/', '/one');
// 'http://example.com/one'
url.resolve('http://example.com/one', '/two');
// 'http://example.com/two'
2. querystring 解析查询字符串
2.1 escape和unescape
querystring.escape(str),对给定的 str 执行 URL 百分比编码,通常不会直接使用,直接使用querystring.stringify();querystring.unescape(str),对给定的 str 上执行 URL 百分比编码字符的解码,通常不会直接使用,直接使用querystring.parse();默认使用 JavaScript 内置的 decodeURIComponent() 方法进行解码;
const qs = require('querystring');
var strUrl = 'https://www.baidu.com/s?key=前端&date=0317';
var tmp = qs.escape(strUrl);
console.log(tmp);
//https%3A%2F%2Fwww.baidu.com%2Fs%3Fkey%3D%E5%89%8D%E7%AB%AF%26date%3D0317
console.log(qs.unescape(tmp));
//https://www.baidu.com/s?key=前端&date=0317
2.2 querystring.parse()
querystring.parse(str, sep, eq, options),将 URL 查询字符串 str 解析为键值对的集合。
- str,要解析的 URL 查询字符串。
- sep,用于在查询字符串中分隔键值对的子字符串。默认值: ‘&’。
- eq,用于在查询字符串中分隔键和值的子字符串。默认值: ‘=’。
const qs = require('querystring');
var myUrl=new URL('https://www.baidu.com/s?key=前端&date=0317');
var searchStr=myUrl.search.substring(1);
console.log(qs.parse(searchStr));
//{ key: '前端', date: '0317' }
2.3 querystring.stringify()
querystring.stringify(obj, sep, eq, options),将传入的对象拼接成字符串。
- obj,要序列化为 URL 查询字符串的对象。
- sep,对象与对象之间的连接符。默认值: ‘&’。
- eq,key和value之间的连接符。默认值: ‘=’。
const qs = require('querystring');
var params = {
name: 'wangh',
age: 20
}
console.log(qs.stringify(params));
//name=wangh&age=20
console.log(qs.stringify(params, '#', '^'));
//name^wangh#age^20
3. http 请求
3.1 http.get()
由于大多数请求都是没有主体的 GET 请求,因此 Node.js 提供了这个便捷的方法。 这个方法与 http.request() 的唯一区别是它将方法设置为 GET 并自动调用 req.end()。
- 语法:
http.get(url,callback) - callback 调用时只有一个参数,为服务端返回的数据。
- 如果请求失败,需要执行
res.resume();来释放内存。
const http=require("http");
http.get('http://localhost:3000', (res) => {
res; //服务端返回的响应数据
res.statusCode; //响应的状态码
res.headers; //响应的消息头对象。
if(请求失败) res.resume();
}
3.2 http.request()
- 语法:
http.request(url, options, callback)。 - 一般用来发送POST请求。
- http.request() 返回 http.ClientRequest 类的实例,可以链式调用。
- 如果同时指定了 url 和 options,则对象会被合并,其中 options 属性优先。
- 必须调用
req.end()来表示请求的结束,
const options = {
hostname: 'localhost',
port: 80,
path: '/upload',
method: 'POST',//GET 或者 POST,大写
headers: {//请求头信息}
};
const clientReq = http.request(options, (res) => {
res; //服务端返回的响应数据
});
//请求遇到问题
clientReq.on('error', (e) => {
console.error(`请求遇到问题: ${e.message}`);
});
//发送请求
clientReq.write(postData);
//请求结束
clientReq.end();
3.3 http.createServer()
创建服务,http.createServer()返回新的 http.Server 实例。
const http = require('http')
var app = http.createServer((request, response) => {
request.method; //判断是GET请求还是POST请求
request.url; //路径端口号后面的内容
request.header; //请求头内容
request.on("data",()=>{}); //收到客户端发来的数据
request.on("end",()=>{ //数据接收完毕
response.setHeader(); //设置响应头内容
response.write(str); //发送数据给客户端
response.end(); //响应完毕
});
})
app.listen(3000, () => { //开启服务
console.log('localtion start 3000')
})
3.3.1 setHeader和writeHead
-
response.setHeader(name, value)
- 为隐式响应头设置
单个响应头的值。 如果此响应头已存在于待发送的响应头中,则其值将被替换。
- 为隐式响应头设置
-
response.writeHead(statusCode, headers)
- 状态码是一个 3 位的 HTTP 状态码,如 404。
- 只能在消息上调用一次,并且
必须在 response.end() 之前调用。 - 将提供的响应头值写入网络通道而不在内部进行缓存。
-
当使用 response.setHeader() 设置响应头时,它们将与传给 response.writeHead() 的任何响应头合并,其中
response.writeHead() 的响应头优先。 -
response.getHeader() 只能获取到 setHeader() 的内容。
// 返回 content-type = text/plain
const server = http.createServer((req, res) => {
res.setHeader('Content-Type', 'text/html');
res.setHeader('X-Foo', 'bar');
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('ok');
});
4. path 路径
用于处理文件路径和目录路径。
4.1 path.dirname()
该方法返回 path 的目录名,类似于 Unix 的 dirname 命令。
path.dirname('/foo/bar/baz/asdf/quux');
// 返回: '/foo/bar/baz/asdf'
4.2 path.extname()
该方法返回 path 的扩展名。
path.extname('index.html');
// 返回: '.html'
path.extname('.index.md');
// 返回: '.md'
4.3 path.parse()
该方法返回一个对象,其属性表示 path 的重要元素。 尾部的目录分隔符将被忽略。

path.parse('/home/user/dir/file.txt');
// 返回:
// { root: '/',
// dir: '/home/user/dir',
// base: 'file.txt',
// ext: '.txt',
// name: 'file' }
4.4 path.resolve()
- 该方法将路径或路径片段的序列解析为绝对路径。
- 如果在处理完所有给定的 path 片段之后还未生成绝对路径,则再加上当前工作目录。
- 生成的路径已规范化,并且除非将路径解析为根目录,否则将删除尾部斜杠。
- 如果没有传入 path 片段,则 path.resolve() 将返回当前工作目录的绝对路径。
path.resolve('/foo/bar', './baz');
// 返回: '/foo/bar/baz'
path.resolve('/foo/bar', '../baz');
// 返回: '/foo/baz'
path.resolve('/foo/bar', '/tmp/file/');
// 返回: '/tmp/file'
5. events 事件触发器
- 所有能触发事件的对象都是 EventEmitter 类的实例。 这些对象有一个 eventEmitter.on() 函数,用于将一个或多个函数绑定到命名事件上。事件的命名通常是驼峰式的字符串。
eventEmitter.emit(),用于抛发/派发事件。eventEmitter.on(),用于侦听事件,可以传任意数量的参数到监听器函数。eventEmitter.once(),表示事件只被侦听一次。 当事件被触发时,监听器会被注销。- 当监听器函数被调用时, this 关键词会被指向监听器所绑定的 EventEmitter 实例。
const eventEmitter = require('events');
class MyEventEmitter extends eventEmitter { }
const em = new MyEventEmitter();
em.on('event', function () {
console.log('触发事件', arguments);
})
em.emit('event', 'aa','bb','cc');
//打印结果:触发事件 [Arguments] { '0': 'aa', '1': 'bb', '2': 'cc' }
5.1 自定义事件
var Events = {
listens: {},
on: function (eventName, cb) {
if (this.listens[eventName]) {
this.listens[eventName].push(cb);
} else {
this.listens[eventName] = [cb];
}
},
trigger: function (eventname) {
let evt.currentTarget = this;
for (let i = 0; i < this.listens[eventname].length; i++) {
this.listens[eventname][i].call(evt.currentTarget);
}
}
}
Events.on('event', () => {
console.log('触发事件');
})
Events.trigger('event');
6. fs 文件系统
- 模仿标准 POSIX 函数的方式与文件系统进行交互,例如文件的新建、编辑、删除等。
- 所有文件系统操作都具有同步和异步两种形式。
- 建议使用异步的形式,因为同步的形式会阻塞整个进程。
- 异步形式中最后一个参数为回调函数。根据nodejs 中错误优先的原则,回调函数中第一个参数为err,如果操作成功完成,则err 为 null 或 undefined。
const fs = require('fs');
fs.unlink('/tmp/hello', (err) => {
if (err) throw err; //throw 抛出异常
console.log('已成功删除 /tmp/hello');
});
6.1 fs.writeFile() 创建文件
fs.writeFile(path,content,cb),创建一个文件,是一个异步操作,必须有回调函数。fs.writeFileSync(path,content),创建一个文件,是一个同步操作。- 第一个参数path为文件名称,第二个参数content为文件的内容,可以是字符串或 buffer格式,第三个参数cb为回调函数。
- 如果文件已经存在,重复创建,会覆盖里面的内容。
let fs = require("fs");
//创建一个a.txt,并写入内容 hello!!
fs.writeFile("./a.txt","hello!!",(err)=>{
if(err) throw err;
})
6.2 fs.readFile() 读取文件内容
fs.readFile(path,options,cb),读取文件的全部内容,是一个异步操作,必须有回调函数。fs.readFileSync(path),读取文件的全部内容,是一个同步操作。- 第一个参数path为文件名称,第二个参数可以设置读取出来的文件内容的编码规则,第三个参数cb为回调函数。
- 如果没有指定文件内容的编码规则,则返回原始的 buffer。
- 回调函数中会传入两个参数 (err, data),其中 data 是文件的内容。
//a.txt文件
{"name":"张三"}
//js文件
let fs = require("fs");
fs.readFile("./a.txt",(err,data)=>{
if(err) throw err;
console.log(data); //<Buffer 7b 0a 20 20 ... 0a 7d>
})
fs.readFile("./a.txt","utf-8",(err,data)=>{
if(err) throw err;
console.log(data); //{"name":"张三"}
})
6.3 fs.unlink() 删除文件
fs.unlink(path,cb),删除文件,是一个异步的操作,必须有回调函数。fs.unlinkSync(path),删除文件,是一个同步的操作。- 第一个参数path为文件名称,第二个参数cb为回调函数。
- fs.unlink() 不能用于删除目录。 要删除目录,需要使用 fs.rmdir()。
let fs = require("fs");
// 假设 'path/file.txt' 是常规文件。
fs.unlink('path/file.txt', (err) => {
if (err) throw err;
console.log('文件已删除');
});
6.4 fs.appendFile() 在文件中追加内容
fs.appendFile(path,content,cb),在文件中追加内容,是一个异步操作,必须有回调函数。fs.appendFileSync(path,content),在文件中追加内容,是一个同步操作。- 第一个参数path为文件名称,第二个参数content为要追加的内容,可以是字符串或 buffer格式,第三个参数cb为回调函数。
- 如果文件尚不存在,则会创建该文件。
let fs = require("fs");
// 在aa.txt中追加内容
fs.appendFile('aa.txt', 'my name is haha', (err) => {
if (err) throw err;
console.log('数据已追加到文件');
});
6.5 fs.mkdir() 创建目录
fs.mkdir(path,options,cb),创建文件夹,是一个异步操作,必须有回调函数。fs.mkdirSync(path),创建文件夹,是一个同步操作。- 第一个参数path为文件夹名称,第二个参数可以设置是否要创建父文件夹,第三个参数cb为回调函数。
- 第二个参数 options中recursive 表示是否要创建父文件夹,默认为false。
- 文件夹重复创建,会报错。
let fs = require("fs");
//会报错,Error: ENOENT: no such file or directory, mkdir './tmp1/a/apple'
fs.mkdir('./tmp1/a/apple', (err) => {
if (err) throw err;
});
//在项目的根目录下创建了tmp2->a->apple,一共3个文件夹
fs.mkdir('./tmp2/a/apple', { recursive: true }, (err) => {
if (err) throw err;
});
//文件夹重复创建,会报错
//Error: EEXIST: file already exists, mkdir './tmp2/a/apple'
6.6 fs.readdir() 读取目录的内容
fs.readdir(path,cb),读取目录的内容,是一个异步操作,必须有回调函数。fs.readdirSync(path),读取目录的内容,是一个同步操作。- 第一个参数path为文件夹名称,第二个参数cb为回调函数。
- 回调函数中有两个参数 (err, files),其中 files 是目录中的文件名的数组(不包括 ‘.’ 和 ‘…’)。
- 如果是同步操作,则fs.readdirSync(path)返回目录中的文件名的数组。
let fs = require("fs");
//tmp文件夹下有a目录和text.txt文件
let path="./tmp"
fs.readdir(path,(err,files)=>{
console.log(files); //['a','text.txt']
})
console.log(fs.readdirSync(path)); //['a','text.txt']
6.7 fs.rmdir() 删除目录
fs.rmdir(path,cb),删除目录,是一个异步操作,必须有回调函数。fs.rmdirSync(path),删除目录,是一个同步操作。- 第一个参数path为文件夹名称,第二个参数cb为回调函数。
- 只能删除空的目录,如果该目录里有内容,则会报错。
案例:传入文件名或者目录名,删除该文件或者该目录下所有的内容:
let fs = require("fs");
function removeFile(path){
//如果传进来的是文件,则直接删除并跳出
if(fs.statSync(path).isFile()) return fs.unlinkSync(path);
//如果是目录,递归删除该目录下的所有文件
fs.readdirSync(path).forEach((item)=>removeFile(path+"/"+item));
//最后删除这个空的目录
fs.rmdirSync(path);
}
6.8 fs.rename() 重命名目录或文件名
fs.rename(oldpath,newpath,cb),修改目录或文件名称,是一个异步操作,必须有回调函数。fs.renameSync(oldpath,newpath),修改目录或文件名称,是一个同步操作。- 第一个参数oldpath为当前的目录或文件名称,第二个参数newpath为修改后的目录或文件名称,第三个参数cb为回调函数。
- 如果 newPath 已存在,则会覆盖它。
let fs = require("fs");
// 将aa.txt 重命名为bb.txt
fs.rename('aa.txt', 'bb.txt', (err) => {
if (err) throw err;
console.log('重命名完成');
});
//将目录tmp2 重命名为tmp
fs.renameSync("./tmp2","./tmp")
6.9 fs.existsSync() 判断文件夹是否已存在
fs.existsSync(path),参数为文件夹路径。- 如果路径存在,则返回 true,否则返回 false。
- fs.exists() 已废弃,使用fs.existsSync() ,即不需要再使用回调。
let fs = require("fs");
if (fs.existsSync('./tmp1/a')) {
console.log('文件已存在');
}
6.10 fs.stat() 返回文件与目录的信息
fs.stat(path,cb),返回文件与目录的信息,是一个异步操作,必须有回调函数。fs.statSync(path),返回文件与目录的信息,是一个同步操作。- 第一个参数 path,为文件名称或者目录路径。
- 回调函数中有两个参数 (err, stats),其中 stats 是一个 fs.Stats 对象。
- 如果是同步操作,则fs.statSync(path)返回一个 fs.Stats 对象。
fs.Stats 对象,有以下方法:stats.isDirectory(),如果path是文件夹,则返回 true。stats.isFile(),如果path是文件,则返回 true。stats.size,返回文件的大小(以字节为单位)。
let fs = require("fs");
const list = ['./txtDir', './txtDir/file.txt'];
for (let i = 0; i < list.length; i++) {
//异步操作
fs.stat(list[i], function(err, stats) {
console.log(stats.isDirectory()); //true false
console.log(stats); //打印结果如下
});
}
//同步操作
console.log(fs.statSync('./txtDir').isDirectory()); //true
stats 打印结果如下:
Stats {
dev: 16777220,
mode: 33188,
nlink: 1,
uid: 501,
gid: 20,
rdev: 0,
blksize: 4096,
ino: 10803859,
size: 24,
blocks: 8,
atimeMs: 1584527766640.159,
mtimeMs: 1584527742951.745,
ctimeMs: 1584527742951.745,
birthtimeMs: 1584526535605.706,
atime: 2020-03-18T10:36:06.640Z,
mtime: 2020-03-18T10:35:42.952Z,
ctime: 2020-03-18T10:35:42.952Z,
birthtime: 2020-03-18T10:15:35.606Z }
7. crypto 加密
crypto模块的目的是为了提供通用的加密和哈希算法。用纯JavaScript代码实现这些功能不是不可能,但速度会非常慢。Nodejs用C/C++实现这些算法后,通过cypto这个模块暴露为JavaScript接口,这样用起来方便,运行速度也快。
crypto 模块提供了加密功能,包括对 OpenSSL 的哈希、HMAC、加密、解密、签名、以及验证功能的一整套封装。
使用MD5、SHA1、Hmac这几种方式,对数据进行加密后,是没有办法解密的。AES的方式,可以对数据进行解密。
7.1 检测是否支持 crypto
可以在不包括支持 crypto 模块的情况下构建 Node.js,这时调用 require(‘crypto’) 将导致抛出异常。
let crypto;
try {
crypto = require('crypto');
} catch (err) {
console.log('不支持 crypto');
}
7.2 MD5和SHA1
MD5是一种常用的哈希算法,用于给任意数据一个“签名”。这个签名通常用一个十六进制的字符串表示。
调用 hash.digest() 方法之后, Hash 对象不能被再次使用。 多次调用将会导致抛出错误。
//引入crypto模块
const crypto = require('crypto');
//使用md5模式 创建并返回一个 Hash 对象
const hash = crypto.createHash('md5');
//update 使用给定的内容更新哈希的内容
hash.update('hello world');
//digest 计算传入要被哈希(使用 hash.update() 方法)的所有数据的摘要。
let result = hash.digest('hex');
//打印出结果:5eb63bbbe01eeed093cb22bb8f5acdc3
console.log(result);
7.3 Hmac
Hmac算法也是一种哈希算法,它可以利用MD5或SHA1等哈希算法。不同的是,Hmac还需要一个密钥。
只要密钥发生了变化,那么同样的输入数据也会得到不同的签名,因此,可以把Hmac理解为用随机数“增强”的哈希算法。
调用 hmac.digest() 方法之后, Hmac 对象不能被再次使用。 多次调用 hmac.digest() 将会导致抛出错误。
//引入crypto模块
const crypto = require('crypto');
//创建 Hmac 实例
const hmac = crypto.createHmac('sha256', 'secret-key');
//使用给定的内容更新 Hmac 的内容
hmac.update('hello world');
//计算使用 hmac.update() 传入的所有数据的 HMAC 摘要
let result = hmac.digest('hex');
//打印出:095d5a21fe6d0646db223fdf3de6436bb8dfb2fab0b51677ecf6441fcf5f2a67
console.log(result);
7.4 AES
对称加密算法,加密和解密都用相同的秘钥。
const crypto = require('crypto');
//数据加密
function aesEncrypt(data, key) {
//用指定的算法和秘钥,返回一个cipher对象
const cipher = crypto.createCipher('aes192', key)
var crypted = cipher.update(data, 'utf8', 'hex')
crypted += cipher.final('hex');
return crypted;
}
//数据解密
function aesDecrypt(encrypted, key) {
const decipher = crypto.createDecipher('aes192', key)
var decrypted = decipher.update(encrypted, 'hex', 'utf8');
decrypted += decipher.final('utf8')
return decrypted;
}
var data = 'hello world';
var key = 'password';
var encrypted = aesEncrypt(data, key);
var decrypted = aesDecrypt(encrypted, key);
console.log(encrypted); //7e280d9850cd8fc1b99b2ba01f64d609
console.log(decrypted); //hello world
8. stream 流
流(stream)是 Node.js 中处理流式数据的抽象接口。 stream 模块用于构建实现了流接口的对象。所有的流都是 EventEmitter 的实例。
Node.js 中有四种基本的流类型:
- Writable - 可写入数据的流(例如 fs.createWriteStream())。
- Readable - 可读取数据的流(例如 fs.createReadStream())。
- Duplex - 可读又可写的流(例如 net.Socket)。
- Transform - 在读写过程中可以修改或转换数据的 Duplex 流(例如 zlib.createDeflate())。
流的使用跟gulp中的pipe()类似,都是通过管道将文件进行输出。
const http = require('http');
const server = http.createServer((req, res) => {
// req 是一个 http.IncomingMessage 实例,它是可读流。
// res 是一个 http.ServerResponse 实例,它是可写流。
let body = '';
// 接收数据为 utf8 字符串,
// 如果没有设置字符编码,则会接收到 Buffer 对象。
req.setEncoding('utf8');
// 如果添加了监听器,则可读流会触发 'data' 事件。
req.on('data', (chunk) => {
body += chunk;
});
// 'end' 事件表明整个请求体已被接收。
req.on('end', () => {
try {
const data = JSON.parse(body);
// 响应信息给用户。
res.write(typeof data);
res.end();
} catch (er) {
// json 解析失败。
res.statusCode = 400;
return res.end(`错误: ${er.message}`);
}
});
});
server.listen(1337);
9. zlib 压缩
zlib 模块提供通过 Gzip 和 Deflate/Inflate 实现的压缩功能。
9.1 zlib.createGzip()
压缩或者解压数据流(例如一个文件)通过 zlib 流将源数据流传输到目标流中来完成。
const fs = require('fs');
const zlib = require('zlib');
//创建一个文件
fs.writeFileSync('log.txt', 'gp18');
//读取文件流
fs.createReadStream('log.txt')
//压缩文件
.pipe(zlib.createGzip())
//输出流
.pipe(fs.createWriteStream('log.txt.gzip'));
更多内置模块,可以查看nodejs官方文档。
