分析csv文件的表头
import csv
filename = r'C:\Users\Administrator\Desktop\my\论文\实验数据\dzdp_wh_fun.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
print(header_row)


查看原csv文件可以发现是一样的。这里我还碰到了几个小问题
- vscode打开csv文件会报错,
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape,在百度一番之后发现应该是我的路径问题,这里vscode可能没有那么智能,把\看成了转义符,所以我们需要在前面加上一个r,

filename = r'C:\Users\Administrator\Desktop\my\论文\实验数据\dzdp_wh_fun.csv'
- vscode有一个很好用的功能,右键文件可以直接复制文件路径

将表头按顺序的输出
for index, column_header in enumerate(header_row): #enumerate用来获取索引以及值
print(index, column_header)

将一列数据全部输出
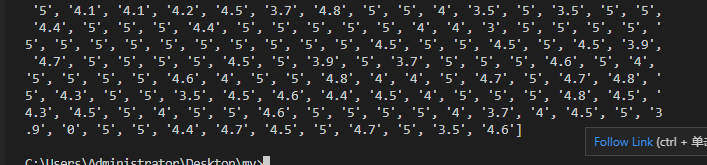
我选择将评分这一列输出,并是int格式,因为这一行每个分数后面都带有一个“分”,所以要先进行数据清洗
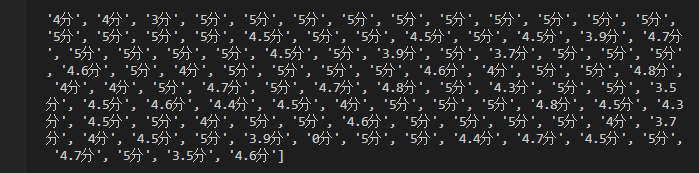
我这里并没有选择使用python来进行清洗,一是因为我不怎么会,二是因为有excel里面有这个功能。这不就是python的思想吗,能用别人的坚决不用自己的。
在excel中选中需要修改的那一行,Ctrl+F进入查找和替换页面,因为我是要删除,所以第二行“替换为”就不用填,再一次输出已经没有了“分”