本

Scrapy 入门
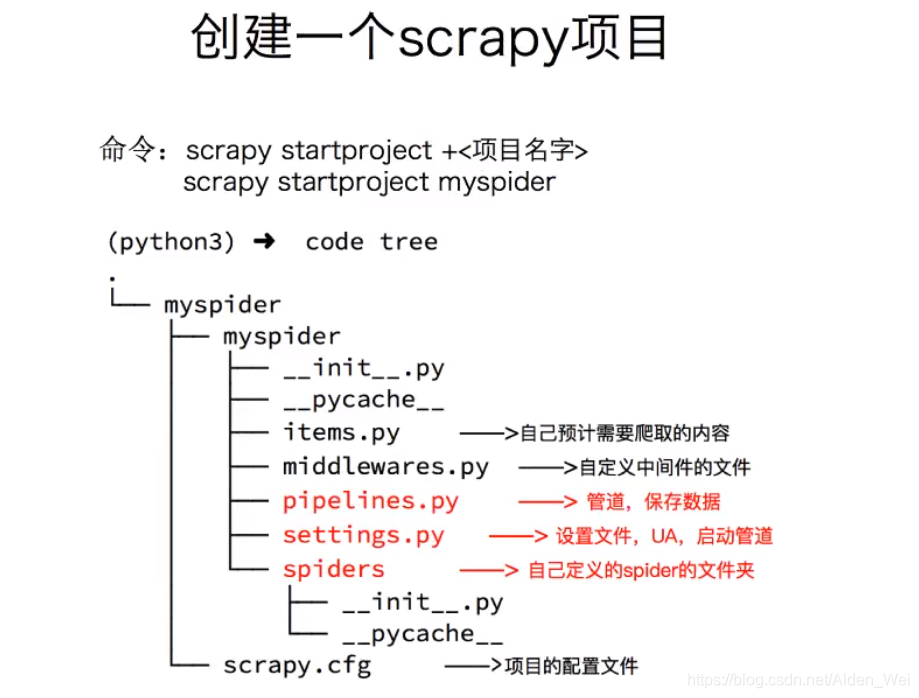
1.创建一个scrapy项目 :
scrapy startproject mySpider(mySpider为项目名,可任意更改)
2.生成一个爬虫 :
scrapy genspider itcast itcast.cn(itcast为爬虫文件的名字,必须唯一,且不能和项目名重复,后边itcast.cn为我们将要爬取的网址,防止爬取其他地址)
3.提取数据 :
scrapy crawl itcast#进行爬取
完善spider,使用xpath等方法
填写parse方法,并且不能对parse方法修改名字,只能为parse()
def parse(self,response):
#处理start_url地址对应的响应
ret1=response.xpath("//div[@class='tea_con']//h3/text()").extract()
print(ret1)
在settings中尽心进行设置,log_level一共四个等级,debug,info,warning和error,设置为warning之后只显示warning及其以上的日志,这样可以让一些没用的日志不去显示,方便查看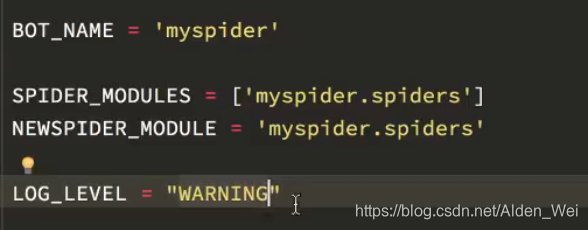
scrapy对提取到的结果进行了一次封装,包含xpath规则和提取到的结果
 因此在xpath方法后添加.extract()方法,extract方法返回的是,本应通过xpath直接提取的数据
因此在xpath方法后添加.extract()方法,extract方法返回的是,本应通过xpath直接提取的数据

进一步优化,获得讲师的职称
li_list=response.xpath("//div[eclass='tea_con']//Li")
for li in li_list:
item={}
item["name"]=1i.xpath(".//h3oirtext()").extract_first()
item["title"]=1i.xpath(".//h4/text()").extract_first()
yield item #将想要的item传给pipeline,由pipeline统一进行处理,但是首先需要在setting中将pipeline开启,默认setting中pipeline是加#作为注释的
yield后不能为列表,只能为request对象,Baseitem,字典或者none,否则报错

#extract_first()
相当于extract()[0],但是当无法无法提取数据是,extract()[0]返回的是完全空列表,而extract_first()则是在无法提取的部分用NONE代替,更符合我们的使用情况。因此最好用extract_first()代替extract()[0]
翻页需求
通过yield scrapy.Request方法实现
yield scrapy.Reques(next_page_url,callback=self.parse) #callback:指定传入的url交给哪个解析函数去处理
scrapy.Request能构建一个requests,同时指定提取数据的callback函数,由于此处让然使用该函数进行处理,因此使用self.prase
同时设置请求头USER_AGENT时在setting中设置,也是默认加#号,自己改
4.保存数据 :
pipeline中保存数据
在spider中使用yield item 将想要的item传给pipeline,由pipeline统一进行处理,但是首先需要在setting中将pipeline开启,默认setting中pipeline是加#作为注释的,只需将pipeline的#号去掉即可
``然后就可以在pipeline中print(item)
后边的return item不可删除。
设置setting中的pipeline时注意: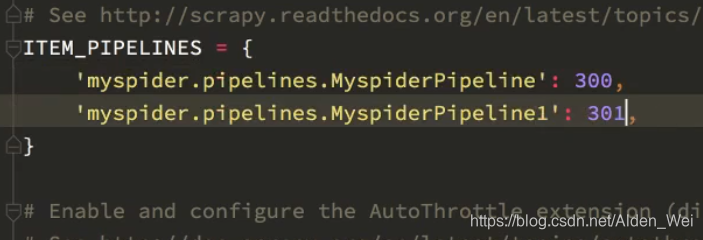
后边的数字代表距离engine的远近,数字越小离engine越近,就先经过该pipeline,比如此处的pipeline和pipeline距离engine的距离分别为300,301,先经过并处理pipeline,后经过pipeline1,以此体现先后顺序。
pipeline中类名可以更改,比如myspiderpipeline,或者myspiderpipeline1,但是方法名process_item()不能更改