一、说下实现的功能:
在Jenkins中提供了自动化测试系统,我们要实现svn中实时获取文件,构建任务,谁提交的任务就在钉钉上给谁发送消息,提示它当前项目id号,svn版本号,失败还是成功,输出错误日志。
二、做之前需要看的文档
首先要查看钉钉官方文档提供的接口文档:点击打开链接
对于发送的自定义的格式参考钉钉官方文档格式,使用那个钉钉给你的token就可以将消息发送到钉钉上,网络的传输协议可以用java,python等,这里我们用python
参考这个链接来得到python的网络传输模块:点击打开链接
三、了解钉钉封装好的功能
虽然在jenkins中可以安装钉钉插件实现已经封装好的功能,如图

但是在钉钉上接受的消息是这样的
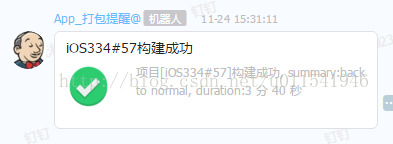
不是我们想要的格式,我们想要的格式是:
1、显示信息:提交人的姓名,svn版本号,build的id,构建结果,以及解析后的错误日志,
2、触发时机:失败才会发送
3、发送给谁:反馈给提交者,而不是钉钉群里所有人。
四、具体步骤
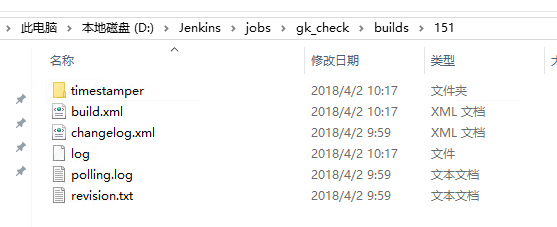
对于获取提交人的姓名我们发现在Jenkins的安装目录下D:\Jenkins\jobs\gk_check\builds这里gk_check是Jenkins项目名,构建后的所有输出日志全部放到了build文件夹下面,对第151次构建下的日志进行分析,
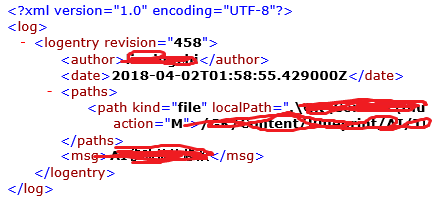
1、提交者的名称在changelog中,是个xml文件,我们只需解析出author即可。
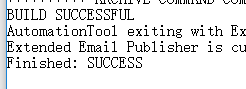
2、当前任务的svn版本号和构建id,可以在批处理时获得,会输出在log日志中

3,对于构建结果,在一个很大的log日志文件中,通过python获取文本最后一行,看有没有success来判断是否成功
4、写一个python,最后再Jenkins批处理中去执行这个脚本将信息发送到钉钉指定人手里,由于任务执行完再执行这个脚本,时间很短,python脚本在获取log日志输出的时候得到的最后一行可能还没有写完,因此该批处理指令要延迟一段时间在执行脚本
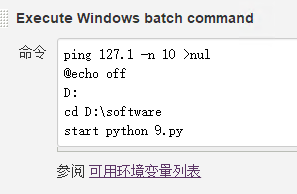
五、贴出python代码:
注意python版本为2.7.13,这个python是自己写的哈,刚接触python,写的不好,哪里写的不好可以提出来哈
#! usr/bin/python
#coding=utf-8
# -*- coding: cp936 -*-
import json,urllib2,time,os,sys
#sys获取数据格式如下:
#第一个数据是svn版本
#第二个数据是build的id
#创建所有同事字典
def getDict():
dict={'tangkun':'13711111111'}
return dict
def getNameDict(authornames):
allNames=[]
dict={"zhangergou":"张二狗"
}#保存本地姓名字典
for item in authornames:
if dict.has_key(item):
allNames.append(dict[item])
#print dict[item]
else:
allNames.append(item)
#print allNames
return allNames
#获取提交者的所有电话
def getTelephone(authornames,myDict):
telephone=[]
for item in authornames:
if myDict.has_key(item):
telephone.append(myDict[item])
#print telephone
return telephone
#读取文件模块(读取提交者姓名)
def ss():
f = open(pathAuthor, 'r')
#for line in f.readlines():#这样是一行一行读取
ff=f.read()#这样读取时读取整个的
#print ff
authornames=[] #用一个列表保存所有作者
lastFFnumber=0
while('<author>' in ff[lastFFnumber:len(ff)]):#遍历该xml中所有作者名
nameStartnum=ff[lastFFnumber:len(ff)].find('<author>')
nameEndnum=ff[lastFFnumber:len(ff)].find('</author>')
startname=ff[nameStartnum:nameStartnum+8]
currentAuthorname=ff[nameStartnum+8+lastFFnumber:nameEndnum+lastFFnumber]
if(currentAuthorname not in authornames):#找到作者名且不再作者列表里就插入到作者列表中
authornames.append(currentAuthorname)
lastFFnumber=nameEndnum+lastFFnumber+1
#print(ff[nameStartnum+8:nameEndnum])
#print authornames[0:len(authornames)]
return authornames
#读取提交者的修改信息
def getAuthorChangeInformation():
ff = open(pathAuthor, 'r').read()
changeInformations=""
lastFFnumber=0
while('<msg>' in ff[lastFFnumber:len(ff)]):#遍历该xml中所有作者名
Startnum=ff[lastFFnumber:len(ff)].find('<msg>')
Endnum=ff[lastFFnumber:len(ff)].find('</msg>')
currentInformation=ff[Startnum+lastFFnumber+5:Endnum+lastFFnumber]
changeInformations=changeInformations+currentInformation+","
lastFFnumber=lastFFnumber+Endnum+1
#print currentInformation
return changeInformations
#读取提交者svn版本和build的id
def getSvnAndID():
#f = open(pathSvn, 'r')
#for line in f.readlines():#这样是一行一行读取
#ff=f.read()#这样读取时读取整个的
mySvnAndID=[]
#StartSvnIndex=ff[0:len(ff)].find('SVN_vision_')
#EndSvnIndex=ff[StartSvnIndex:len(ff)].find('_GK_CLIENT_BUILD_ID_')+StartSvnIndex
#mySvnAndID.append(ff[StartSvnIndex+11:EndSvnIndex])
#mySvnAndID.append(jobCurrentNumber)
mySvnAndID.append(sys.argv[1])#外部获取版本号和build的id
mySvnAndID.append(sys.argv[2])
return mySvnAndID
#获取当前构建结果是失败还是成功,获取日志最后一行看有没有success来判断是否成功
def getResult():
fname = pathSvn
with open(fname, 'r') as f: #打开文件
first_line = f.readline() #读第一行
off = -50 #设置偏移量
while True:
f.seek(off, 2) #seek(off, 2)表示文件指针:从文件末尾(2)开始向前50个字符(-50)
lines = f.readlines() #读取文件指针范围内所有行
if len(lines)>=2: #判断是否最后至少有两行,这样保证了最后一行是完整的
last_line = lines[-1] #取最后一行
break
#如果off为50时得到的readlines只有一行内容,那么不能保证最后一行是完整的
#所以off翻倍重新运行,直到readlines不止一行
off *= 2
if 'SUCCESS' in last_line:
return 1
else:
return 0
#print '文件' + fname + '最后一行为:'+ last_line
#获取下一次构建的Number和当前构建的number
def getNextNumber():
f = open(r'J:\Jenkins\jobs\gk_check\nextBuildNumber', 'r')
currentNumber=int(f.read())-1
#print currentNumber
return currentNumber
#网络模块,用于钉钉发送信息
def dd(allNameList,SvnAndID,result,allTelephone,Informations):
url='https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxx'
i=0
allName=''
while(i<len(allNameList)): #用于把list中的名字遍历拼接到一个字符串中
allName=allName+allNameList[i]
allName=allName+','
#print i
i=i+1
#print allName
if result ==1:
con={"msgtype":"text","text":{"content":"提交者:"+allName+"\n"+"svn版本号:"+str(SvnAndID[0])+"\n"+"构建id:"+str(SvnAndID[1])+"\n"+"修改信息:"+Informations+"\n"+"构建结果:成功"},
"at":{"atMobiles":allTelephone,"isAtAll":"false"}}#输出作者列表中所有作者
else:
con={"msgtype":"text","text":{"content":"提交者:"+"\n"+allName+"\n"+"svn版本号:"+str(SvnAndID[0])+"\n"+"构建id:"+str(SvnAndID[1])+"\n"+"修改信息:"+Informations+"\n"+"构建结果:不成功"},
"at":{"atMobiles":allTelephone,"isAtAll":"true"} }#输出作者列表中所有作者
jd=json.dumps(con)
req=urllib2.Request(url,jd)
req.add_header('Content-Type', 'application/json')
response=urllib2.urlopen(req)
#print response,time.ctime()
if __name__ == '__main__':
jobCurrentNumber=getNextNumber() #获取当前构建number
myDict=getDict()#获取同事所有联系方式
path="J:\\Jenkins\\jobs\\gk_check\\builds\\"+str(jobCurrentNumber)+"\\" #获取当前构建的目录比如D:\Jenkins\jobs\gk_check\builds\153,这里一定注意路径\要用两个斜杠,不然输出乱码
pathSvn=path+"log" #获取svn版本和id信息的文件路径
pathAuthor=path+"changelog.xml" #获取递交者信息的文件路径
#print path
authornames=ss() #执行读取提交者名模块
allNameList=getNameDict(authornames)#获取本地所有同事名字字典
Informations=getAuthorChangeInformation()#读取提交者修改信息
allTelephone=getTelephone(authornames,myDict)#根据同事字典保存的所有同事电话和获取提交者来得到所有提交者的电话列表
result=getResult() #读取构建结果
SvnAndID=getSvnAndID() #执行获取svn和id模块
dd(allNameList,SvnAndID,result,allTelephone,Informations) #最后执行dd函数
getResult()