一、fork函数
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
该函数的每次调用都返回两次,在父进程中返回的是子进行的PID,在子进程中返回的是0.失败时返回-1
#include <iostream>
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
int main()
{
pid_t pid;
cout << "开始" << endl;
pid = fork();
if(pid == -1)
{
perror("fork error");
exit(-1);
}
else if(pid == 0) //子进程
{
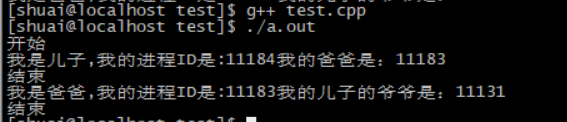
cout << "我是儿子,我的进程ID是:" << getpid() << "我的爸爸是:" << getppid() << endl;
}
else
{
sleep(5);
cout << "我是爸爸,我的进程ID是:" << getpid() << "我的儿子的爷爷是:" << getppid() << endl;
}
cout << "结束" << endl;
return 0;
}上述简单示例,可以初步体会到fork函数的用法
运行结果:
循环创建n个子进程程序:
#include <iostream>
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
int main()
{
pid_t pid;
cout << "开始" << endl;
//开始循环
for(int i = 0; i < 3; i++)
{
pid = fork();
if(pid == -1)
{
perror("fork error");
exit(-1);
}
if(pid == 0) //子进程,子进程不再进入循环
{
cout << "我是第" << i + 1 << "个子进程" << endl;
break; //为啥要break,搞清楚
}
else
{
cout << "反正我就是爹" << i + 1 << endl;
sleep(1);
}
}
cout << "结束" << endl;
return 0;
}
相信通过上面两个程序,对fork函数已经有所了解
干货:
fork函数复制当前进程,在内核进程表中创建一个新的进程表项。新的进程表项有很多属性和原进程相同,比如堆指针、栈指针和标志寄存器的值。但也有很多属性被赋予了新的值,比如该进程的PPId被设置成了原进程的PID,信号位图被清除。子进程的代码和父进程的代码完全相同,同时它还会复制父进程的数据(堆数据、栈数据和静态数据)。数据的复制采用的是写时复制,也就是只有在任一进程对数据执行了写操作是,复制才会发生。此外,创建子进程后,父进程中打开的文件描述符默认在子进程中也是打开的,且文件描述符的引用计数+1。
关于数据共享:
#include <iostream>
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
int x = 100;
int main()
{
pid_t pid;
cout << "开始" << endl;
pid = fork();
if(pid == -1)
{
perror("fork error");
exit(-1);
}
if(pid == 0) //子进程
{
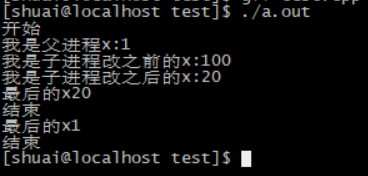
cout << "我是子进程改之前的" << "x:" << x << endl;
x = 20;
cout << "我是子进程改之后的" << "x:" << x << endl;
}
else
{
x = 1;
cout << "我是父进程" << "x:" << x << endl;
sleep(1);
}
cout << "最后的x" << x << endl;
cout << "结束" << endl;
return 0;
}
什么是写时复制:
在linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,linux中引入了“写时复制”技术,也就是只有进程空间的各段的内容要发生变化时,才将父进程的内容复制一份给子进程。
那么子进程的物理空间没有代码,怎么去取指令执行exec系统调用呢??
在fork之后exec之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,其对应的物理空间是一个。当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间。如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者都有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
在网上看到的还有个细节问题是:fork之后内核会将子进程排在队列的前面,以让子进程先执行,以免父进程执行导致写时复制,而后子进程执行exec系统调用,因无意义的复制而造成效率的下降。
父子进程真正共享的部分:1.文件描述符 2.mmap
二、gdb调试多进程程序
set follow-fork-mode child
set follow-fork-mode parent
需要在fork函数调用之前设置
三、exec系列系统调用
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg,
..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[],
char *const envp[]);有时候,我们需要在子进程中执行其他程序,即替换当前进程映像,就使用上面这些函数可以实现。
四、处理僵尸进程
僵尸进程:进程终止,父进程尚未回收,子进程残留资源(PCB)存在于内核中,变成僵尸进程。
孤儿进程:就是爹死了,但是儿子没死,然后就成孤儿了,孤儿最后被好心人隔壁老王(init)领养了。
#include <iostream>
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
int main()
{
pid_t pid;
cout << "开始" << endl;
pid = fork();
if(pid == -1)
{
perror("fork error");
exit(-1);
}
if(pid == 0) //子进程
{
while(1)
{
cout << getppid() << endl;
sleep(2);
}
}
else
{
sleep(3);
cout << "爹即将死去" << endl;
}
cout << "结束" << endl;
return 0;
}
上面是一个孤儿进程程序:

可以看到ctrl+c都停不下来,然后
ps -all

然后可以把它kill掉。
#include <iostream>
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
int main()
{
pid_t pid;
cout << "开始" << endl;
pid = fork();
if(pid == -1)
{
perror("fork error");
exit(-1);
}
if(pid == 0) //子进程
{
sleep(10);
cout << "子进程也死了" << endl;
}
else
{
while(1)
{
sleep(3);
cout << "我是爹,我还活着" << endl;
}
}
cout << "结束" << endl;
return 0;
}
上面代码是一个关于僵尸进程的代码,


可以看到上面的僵尸进程。
所以说如何处理僵尸进程呢?
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);
int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);
这俩函数。差别就是,wait阻塞等待一个子进程退出并回收,waitpid则是回收指定子进程,可以不则塞,这样的话,就需要轮询。
五、进程间通信
在进程间完成数据传递需要借助操作系统提供特殊的方法,如:文件、管道、信号、共享内存、消息队列、套接字、命名管道等。随着计算机的蓬勃发展,一些方法由于自身设计缺陷而被淘汰,目前常用的进程间通信方式有四种:管道(使用最简单)信号(开销最小)共享映射区(无血缘关系)本地套接字(最稳定)
1.管道
管道是一种最基本的IPC机制,作用于有血缘关系的进程之间,完成数据传递。调用pipe函数即可创建一个管道。有如下特性:
1).其本质是一个伪文件(实为内核缓冲区)
2).两个文件描述符引用,一个表示读端,一个表示写端
3).规定数据从管道的写端流入管道,从读端流出
管道的原理:管道实为内核使用唤醒队列机制,借助内核缓冲区(4k)实现
pipe函数:
int pipe(int pipefd[2], int flags);#include <iostream>
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <wait.h>
using namespace std;
int main()
{
pid_t pid;
int fd[2];
int ret = pipe(fd);
int status = -1;
if(ret == -1)
{
perror("pipe error");
exit(-1);
}
cout << "开始" << endl;
pid = fork();
if(pid == -1)
{
perror("fork error");
exit(-1);
}
if(pid == 0) //子进程 读数据
{
//将写端关闭
//为保证写的时候,读操作已经完成了,所以儿子先睡一下
sleep(2);
close(fd[1]);
char buf[1024];
int ret = read(fd[0], buf, sizeof(buf));
if(ret == -1)
{
perror("child read error");
exit(-1);
}
cout << buf << endl;
}
else //父进程 写数据
{
//将读端关闭
close(fd[0]);
char hh[1024] = "我是数据";
int ret = write(fd[1], hh, sizeof(hh));
if(ret == -1)
{
perror("parent write error");
exit(-1);
}
//回收子进程
wait(&status);
}
cout << "结束" << endl;
return 0;
}上面代码简单示例了利用管道进行进程间通信。
2.FIFO
https://blog.csdn.net/firefoxbug/article/details/8137762
可以自行了解一下,我不是很感兴趣
3.mmap
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void *addr, size_t length);