zookeeper简介
官方文档上这么解释zookeeper,它是一个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。简单来说zookeeper在大数据开发当中就是各框架的润滑剂,保存一些集群的配置信息。从设计模式的角度来理解:zookeeper是一个基于观察者模式的分布式服务管理框架,它负责存储和管理大家的都关心的数据,然后接受观察者的注册,一旦这些数据状态发生改变,zookeeper就将负责通知在zookeeper上注册的那些观察者做出相应的反应。
zookeeper的特点
1、zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群
2、集群中只要有半数以上节点存活,zookeeper集群就能正常服务
3、全局数据一致性:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一直的
4、更新请求顺序进行,来自同一个client的更新请求按其发送顺序一次执行
5、数据更新原子性,一次数据更新要么成功要么失败
6、实时性,在一定时间范围内,client能读到最新数据
zookeeper数据结构
树型结构:与unix文件系统类似,整体一棵树,每个节点称作一个ZNode,每个默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。

zookeeper选举机制
半数机制:集群中半数以上机器存活,集群可用。所有适合安装奇数台服务器。zookeeper配置文件中不指定Master和Slave,zookeeper工作时一个节点为Leader其他为Follower,Leader是通过内部选举机制产生的。在安装集群时会配置myid每个服务器的id不一样,也不是同时启动,所有按照myid启动顺序,一台一台启动服务器,已经启动的服务器进行投票选举,如果没有超过半数则下一轮投票myid比自己大的服务器。例如:三台服务器集群myid分别为1、2、3,1启动时1号服务器投票自己,获得一票,未过半数,第二轮2号启动,1号投票2号,2号投票自己,获得两票过半数,2号为Leader,启动3号,不再投票。
zookeeper节点类型
持久:客户端和服务器断开连接后,创建节点不删除
短暂:客户端和服务器断开连接后,创建的节点自己删除
分布式安装部署
1)下载解压
tar -zxvf zookeeper-3.4.14.tar.gz -C /opt/mudole
xsync zookeeper-3.4.14/ #分发到集群
2)配置服务器编号
zkData文件夹为在zoo.cfg文件中配置的数据存储目录
注意分发myid时每台机器的编号必须不同
#在安装目录创建 mkdir -p zkData #在zkData新建myid文件 touch myid vim myid #写上编号 例如:1
3)配置文件
重命名zookeeper-3.4.14/conf下的zoo_sample.cfg为zoo.cfg
vim zoo.cfg #添加内容 dataDir=/opt/module/zookeeper-3.4.14/zkData server.1=hadoop-101:2888:3888 server.2=hadoop-102:2888:3888 server.3=hadoop-103:2888:3888
server.1=hadoop-101:2888:3888这个必须按照自己实际集群环境搭建,server.后面的数字就是myid编号,2888表示服务器与集群Leader服务器交换信息的端口,3888表示万一Leader服务器故障通过这个端口进行重新选举
4)启动测试
在zookeeper安装目录下通过bin/zkServer.sh start命令开启 每个服务器都要开启,bin/zkServer.sh status查看状态
监听器原理
1)要有main()线程
2)在main线程中创建zookeeper客户端,这时会创建两个线程,一个负责网络通信连接(connect)一个负责监听(listener)
3)通过connect线程注册监听事件发送给zookeeper
4)在zookeeper的注册监听器列表中将注册的监听事件添加到列表
5)zookeeper监听到有数据或路径变化,就会发送这个消息给listener线程
6)listener线程内部调用了process()方法
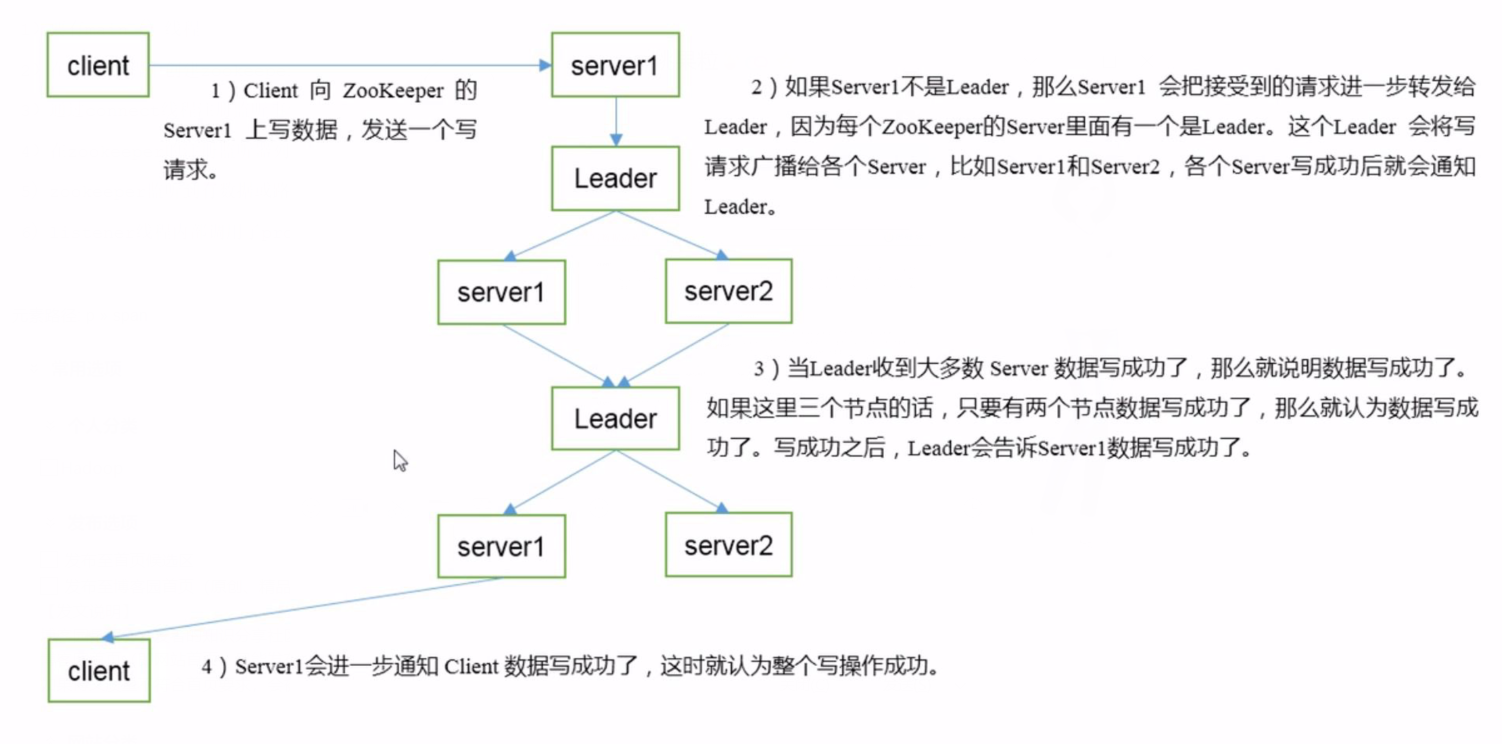
写数据流程
eclipse环境搭建
创建maven工程
添加pom文件
<dependencies> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.14</version> </dependency> </dependencies>
拷贝log4j.properties文件到项目目录的src/main/resources目录下
log4j.rootLogger=INFO,stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%nS
创建zookeeper客户端
package com.hadoop.zookeeper; import org.junit.Test; import java.io.IOException; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.ZooKeeper; public class TestZookeeper{ private String connectString = "hadoop-101:2181,hadoop-102:2181,hadoop-103:2181"; private int sessionTimeout = 2000; private ZooKeeper zkClient; @Test public void init() throws IOException { zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() { public void process(WatchedEvent event) { // TODO Auto-generated method stub } }); } }
测试
运行能看到这些信息则表示成功配置客户端!