集群角色介绍
Spark是基于内存计算的大数据并行计算框架,实际中运行计算任务肯定是使用集群模式,那么我们先来学习Spark自带的standalone集群模式了解一下它的架构及运行机制。
Standalone集群使用了分布式计算中的master-slave模型
- master是集群中含有master进程的节点
- slave是集群中的worker节点含有Executor进程
Spark架构图如下:
http://spark.apache.org/docs/latest/cluster-overview.html
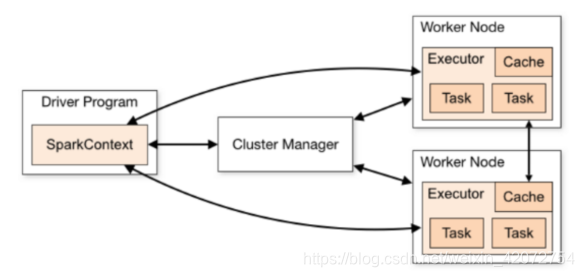
standalone集群模式配置
第一步:集群规划
- hadoop01:master
- hadoop02:slave/worker
- hadoop03:slave/worker
第二步:修改配置并分发
- 修改Spark配置文件
cd /export/servers/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
#配置java环境变量
export JAVA_HOME=/export/servers/jdk1.8
#指定spark Master的IP
export SPARK_MASTER_HOST=hadoop01
#指定spark Master的端口
export SPARK_MASTER_PORT=7077
mv slaves.template slaves
vim slaves
hadoop02
hadoop03
- 配置spark环境变量 (建议不添加,避免和Hadoop的命令冲突)
将spark添加到环境变量,在/etc/profile.d目录下创建sparkhome.sh,输入以下内容
export SPARK_HOME=/export/servers/spark
export PATH=$PATH:$SPARK_HOME/bin
注意:
hadoop/sbin 的目录和 spark/sbin 目录下可能会因为文件重名,导致有以下两个命令冲突,:
start-all.sh
stop-all.sh
解决方案:
1.把其中一个框架的 sbin 从环境变量中去掉;
2.改名 hadoop/sbin/start-all.sh 改为: start-all-hadoop.sh
第三步:通过scp 命令将配置文件分发到其他机器上
cd /export/servers/
scp -r /export/servers/spark hadoop02:$PWD
scp -r /export/servers/spark hadoop03:$PWD
cd /etc/profile.d/
scp sparkhome.sh hadoop02:$PWD
scp sparkhome.sh hadoop03:$PWD
第四步:在各个节点执行以下命令
source /etc/profile
第五步:启动和停止
- 集群启动和停止
在主节点上启动spark集群
/export/servers/spark/sbin/start-all.sh
在主节点上停止spark集群
/export/servers/spark/sbin/stop-all.sh
- 单独启动和停止
在 master 安装节点上启动和停止 master:
start-master.sh
stop-master.sh
在 Master 所在节点上启动和停止worker(work指的是slaves 配置文件中的主机名)
start-slaves.sh
stop-slaves.sh
第六步:查看web界面
正常启动spark集群后,查看spark的web界面,查看相关信息。
http://hadoop01:8080/
第七步:测试
- 需求
使用集群模式运行Spark程序读取HDFS上的文件并执行WordCount
- 集群模式启动spark-shell
/export/servers/spark/bin/spark-shell --master spark://hadoop01:7077
- 运行程序
sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
.saveAsTextFile("hdfs://node01:8020/wordcount/output2")
- SparkContext web UI
- 注意
集群模式下程序是在集群上运行的,不要直接读取本地文件,应该读取hdfs上的
因为程序运行在集群上,具体在哪个节点上我们运行并不知道,其他节点可能并没有那个数据文件
