Python开发之NumPy的简单使用
前言:主要介绍了NumPy的常用方法。
1.NumPy的环境配置
如果你已经配置过matplotlib的环境,就不需要再配置了,如果没有配置请参考我的《Python开发之matplotlib的简单使用(一)》,因为matplotlib包含NumPy的环境。
2.NumPy生成数组和查看数据类型
- 可以使用np.array或者np.arange方法来生成数组。
- 常用的数据类型有整型、浮点型、布尔型、复数型(不常用)
代码:
import numpy as np
import random
#使用numpy生成数组,得到ndarray的类型
t1 = np.array([1,2,3])
print("t1:",t1)
print("t1的类型",type(t1))
t2 = np.array(range(10))
print("t2:",t2)
print("t2的类型",type(t2))
t3 = np.arange(4,10,2)
print("t3:",t3)
print("t3的类型",type(t3))
print("t3的数据类型",t3.dtype)
#numpy中的数据类型
t4 = np.array(range(1,4), dtype="i1")
print("t4:",t4)
print("t4的数据类型",t4.dtype)
#numpy中的bool类型
t5 = np.array([1,1,0,1,0,0], dtype=bool)
print("t5:",t5)
print("t5的数据类型",t5.dtype)
#调整数据类型
t6 = t5.astype("int8")
print("t6:",t6)
print("t6的数据类型",t6.dtype)
#numpy中的小数
t7 = np.array([random.random() for i in range(10)])
print("t7:",t7)
print("t7的数据类型",t7.dtype)
t8 = np.round(t7,2)
print("t8",t8)
print("t8的数据类型",t8.dtype)
输出:

3.NumPy的形状
代码:
import numpy as np
a = np.array([[2,4,5,6,7,8],[4,5,6,7,8,9]])#一个数组
print("a:",a)
print("a的形状:",a.shape)#查看数组的形状
b = a.reshape(3,4)
print("b的形状:",b.shape)
print("b:",b)
#把数组转换成一维数组
print("b转换成1维数组:",b.reshape(1,12))#不是
print("b的flatten方法",b.flatten())#是
输出:

4.数组和数的计算
代码:
import numpy as np
a = np.array([[2,4,5,6,7,8],[4,5,6,7,8,9]])#一个数组
print("a:",a)
print("a+2:",a+2)
print("a*3",a*3)
输出:

5.数组和数组的计算
代码1:
import numpy as np
a = np.array([[2,4,5,6,7,8],[4,5,6,7,8,9]])#一个数组
b = np.array([[21,22,23,24,25,26],[27,27,29,30,31,32]])#一个数组
print("a的值:\n",a)
print("b的值:",b)
print("a+b的值:\n",(a+b))
print("a*b的值:\n",(a*b))
c = np.array([1,2,3,4,5,6])
print("c的值:",c)
print("a-c的值:\n",(a-c))
输出1:

代码2:
import numpy as np
a = np.array([[3,4,5,6,7,8],[4,5,6,7,8,9]])#一个数组
c = np.array([1,2,3,4,5,6])
print("c的值:",c)
print("a-c的值:",(a-c))
print("a*c的值:",(a*c))
输出2:

代码3:
import numpy as np
a = np.array([[3,4,5,6,7,8],[4,5,6,7,8,9]])#一个数组
c = np.array([[1],[2]])
print("a的值:",a)
print("c的值:",c)
print("c+a的值:",(c+a))
print("a*c的值:",(a*c))
print("c*a的值:",(c*a))
输出3:

6.loadtxt和savetxt(重点)
loadtxt:读取txt文件
savetxt:存储txt文件
np.loadtxt(FILENAME, dtype=int, delimiter=’ ')
np.savetxt(FILENAME, a, fmt="%d", delimiter=",")
接下来我们读取一个data.txt数据
内容截图:

代码:
import numpy as np
data_file_path = "data.txt"
t1 = np.loadtxt(data_file_path,delimiter=",",dtype="int",unpack=False)
print("t1的类型:",type(t1))
print("t1的数据类型:",t1.dtype)
print("t1的形状:",t1.shape)
print("t1的内容:\n",t1)
输出:

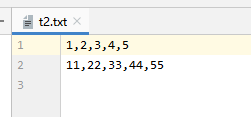
存储代码:
import numpy as np
t2 = np.array([[1,2,3,4,5],[11,22,33,44,55]])
np.savetxt("t2.txt", t2, fmt="%d", delimiter=",")
输出:
7.索引和切片(重点)
代码:
import numpy as np
data_file_path = "data.txt"
t1 = np.loadtxt(data_file_path,delimiter=",",dtype="int",unpack=False)
print("t1的类型:",type(t1))
print("t1的数据类型:",t1.dtype)
print("t1的形状:",t1.shape)
print("t1的内容:\n",t1)
print("*"*100)
#取行
print("取第3行:",t1[2])
#取连续的多行
print("取第3行以后的(包括第3行):",t1[2:])
#取不连续的多行
print("取第3行、9行、11行:",t1[[2,8,10]])
print("取第2行:",t1[1,:])
print("取第3行以后(包括第3行):",t1[2:,:])
print("取第3行、11行、4行:",t1[[2,10,3],:])
#取列
print("取第1列:",t1[:,0])#第一列
#取连续的列
print("取第3列以后(包括第三列):",t1[:,2:])
#取不连续的多列
print("取第1列和第3列:",t1[:,[0,2]])
#取行和列,取第三行,第四列
a = t1[2,3]
print(a)
print(type(a))
#取第三行到第五行,第二列到第四列的结果
b = t1[2:5,1:4]
print(b)
#取多个不相邻的点
c = t1[[0,2,3],[0,1,3]]
print(c)
输出:

8.转置
代码:
import numpy as np
t = np.array([[0,1,2,3,4,5],[6,7,8,9,10,11],[12,13,14,15,16,17]])
print(t)
print(t.transpose())
print(t.swapaxes(1,0))
print(t.T)
输出:

9.数值的修改
代码:
import numpy as np
t = np.array([[0,1,2,3,4,5],
[6,7,8,9,10,11],
[12,13,14,15,16,17],
[18,19,20,21,22,23]])
print("输出t:",t)
print("输出第3列和第5列:",t[:,2:4])
t[:,2:4] = 0 #修改第3列和第5列为0
print(t)
输出:

10.布尔索引
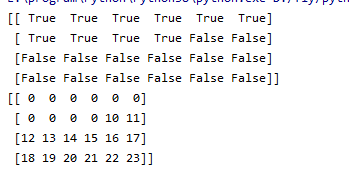
代码:
import numpy as np
t = np.arange(24).reshape((4,6))
print(t<10)
t[t<10] = 0
print(t)
输出:
11.三元运算符
代码:
import numpy as np
t = np.arange(24).reshape((4,6))
print(t)
a = np.where(t<10,0,10)
print(a)
输出:

12.裁剪
代码:
import numpy as np
t = np.arange(24).reshape((4,6))
t = t.astype(float)
t[3,3] = np.nan
print(t)
print("*"*100)
print(t.clip(10,18))
输出:

13.nan和inf
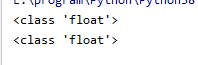
代码:
import numpy as np
a = np.inf
print(type(a))
b = np.nan
print(type(b))
输出:
14.nan的注意点
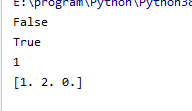
import numpy as np
print(np.nan == np.nan)
print(np.nan != np.nan)
t = np.array([1., 2., np.nan])
print(np.count_nonzero(t!=t))
t[np.isnan(t)] = 0
print(t)
输出:
15.常用统计函数
import numpy as np
a = np.array([[2,4,5,6,7,8],
[4,5,6,7,8,9],
[11,22,12,54,66,99]])#一个数组
#0代表竖着求
#1代表横着求
print(a.sum(axis=0))#求和
print(a.mean(axis=0))#均值
print(np.median(a,axis=0))#中值
print(a.max(axis=0))#最大值
print(a.min(axis=0))#最小值
print(np.ptp(a,axis=0))#极值
print(a.std(axis=0))#标准差
16.ndarry缺失值填充均值
import numpy as np
def fill_ndarray(t1):
for i in range(t1.shape[1]): #遍历每一列
temp_col = t1[:,i] #当前的一列
print("---",temp_col)
nan_num = np.count_nonzero(temp_col != temp_col) #判断nan的个数
print("判断nan的个数", nan_num)
if nan_num != 0: #不为0,说明当前这一列中有nan
temp_not_nan_col = temp_col[temp_col == temp_col]
print("temp_not_nan_col", temp_not_nan_col)
# 选中当前为nan的位置,把值赋值为不为nan的均值
temp_col[np.isnan(temp_col)] = temp_not_nan_col.mean()
return t1
if __name__ == "__main__":
t1 = np.arange(24).reshape((4,6)).astype("float")
t1[1,2:] = np.nan
print(t1)
t1 = fill_ndarray(t1)
print(t1)
输出:

17.数组拼接
代码:
import numpy as np
t1 = np.array([[0,1,2,3,4,5],
[6,7,8,9,10,11]])
t2 = np.array([[12,13,14,15,16,17],
[18,19,20,21,22,23]])
a = np.vstack((t1, t2)) #竖着拼接
print(a)
b = np.hstack((t1, t2))
print(b)
输出:
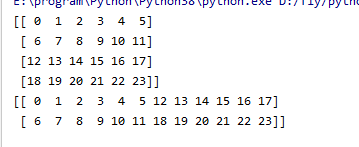
18.数组的行列交换
代码:
import numpy as np
t = np.arange(12, 24).reshape(3, 4)
print(t)
t[[1,2],:] = t[[2,1],:]#行交换
print(t)
t[:,[0,2]] = t[:,[2,0]]#列交换
print(t)
输出:
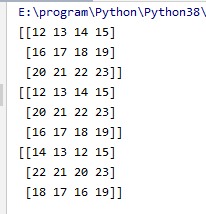
19.获取值的位置
代码:
import numpy as np
t = np.arange(24).reshape((6,4)).astype(int)
print(t)
#获取最大值最小值的位置
print(np.argmax(t,axis=0))
print(np.argmax(t,axis=1))
print(np.argmin(t,axis=0))
print(np.argmin(t,axis=1))
print(np.zeros((3,4))) #全为0的数组
print(np.ones((4,5))) #创建一个全1的数组
print(np.eye(3)) #创建一个对角线为1的正方形数组(方阵
输出:

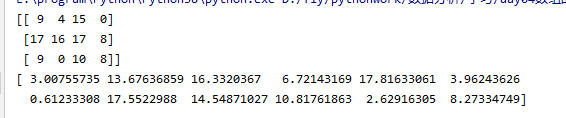
20.生成随机数
代码:
import numpy as np
np.random.seed(10)
t1 = np.random.randint(0,20,(3,4))
print(t1)
t2 = np.random.uniform(0,20,(12))
print(t2)
输出:
结束!
