我们前面已经在探讨了编译器的 前端技术 。它的重点,是让编译器能够读懂程序。无结构的代码文本,经过前端的处理以后,就变成了 Token、AST 和语义属性、符号表等结构化的信息。基于这些信息,我们可以实现简单的 脚本解释器 。
编译器后端要解决的问题:现在给你一台计算机,你怎么生成一个可以运行的程序,然后还能让这个程序在计算机上正确和高效地运行?
程序运行机制
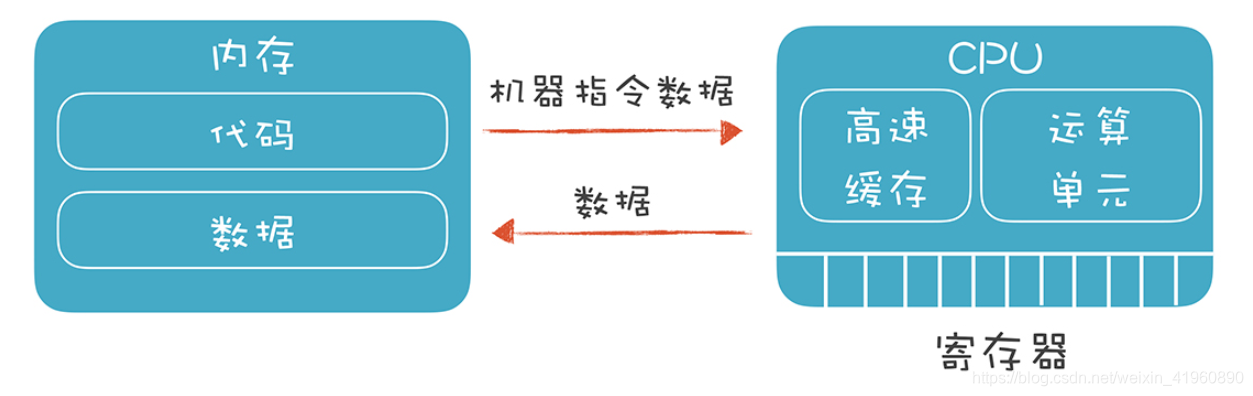
我们关注的是两个底层硬件:
- CPU:它能接受机器指令和数据,并进行计算。它里面有寄存器、高速缓存和运算单元,充分利用寄存器和高速缓存会让系统的性能大大提升。
- 内存:我们要在内存里保存编译好的代码和数据,还要设计一套机制,让程序最高效地利用这些内存。
生成代码
编译器后端的最终结果,就是生成目标代码。如果目标是在计算机上直接运行,就像 C 语言程序那样,那这个目标代码指的是 汇编代码。而如果运行目标是 Java 虚拟机,那这个目标代码就是指 JVM 的字节码。
写汇编跟使用高级语言有很多不同,其中一点就是要关心 CPU 和内存这样具体的硬件。比如,我们需要了解不同的 CPU 指令集的差别,还需要知道 CPU 是 64 位的还是 32 位的,有几个寄存器,每个寄存器可以用于什么指令,等等。但这样导致的问题是,每种语言,针对每种不同的硬件,都要生成不同的汇编代码。
所以,为了降低后端工作量,提高软件复用度,就需要引入 中间代码(Intermediate Representation,IR)的机制,它是独立于具体硬件的一种代码格式。各个语言的前端可以先翻译成 IR,然后再从 IR 翻译成不同硬件架构的汇编代码。如果有 n 个前端语言,m 个后端架构,本来需要做 m*n 个翻译程序,现在只需要 m+n 个了。这就大大降低了总体的工作量。
总的来说,我们可以把各种语言翻译成中间代码,再针对每一种目标架构,通过一个程序将中间代码翻译成相应的汇编代码就可以了。
代码分析与优化
生成正确的、能够执行的代码比较简单,可这样的代码执行效率很低,因为直接翻译生成的代码往往不够简洁,比如会生成大量的临时变量,指令数量也较多。因为翻译程序首先照顾的是正确性,很难同时兼顾是否足够优化,这是一方面。另一方面,由于高级语言本身的限制和程序员的编程习惯,也会导致代码不够优化,不能充分发挥计算机的性能。所以我们一定要对代码做优化。程序员在比较各种语言的时候,一定会比较它们的性能差异。一个语言的性能太差,就会影响它的使用和普及。
优化工作又分为 “独立于机器的优化” 和 “依赖于机器的优化” 两种。
- 独立于机器的优化,是基于 IR 进行的。它可以通过对代码的分析,用更加高效的代码代替原来的代码。
- 依赖于机器的优化,是依赖于硬件的特征。
- 寄存器优化。对于频繁访问的变量,最好放在寄存器中,并且尽量最大限度地利用寄存器,不让其中一些空着。
- 充分利用高速缓存。
- 并行性。现代计算机都有多个内核,可以并行计算。
- 流水线。CPU 在处理不同的指令的时候,需要等待的时间周期是不一样的,在等待某些指令做完的过程中其实还可以执行其他指令。
- 指令选择。有的时候,CPU 完成一个功能,有多个指令可供选择。而针对某个特定的需求,采用 A 指令可能比 B 指令效率高百倍。
- 其他优化。比如可以针对专用的 AI 芯片和 GPU 做优化,提供 AI 计算能力,等等。
总结
后端技术,就是生成一个可运行的程序,并且支持他在机器上正确、高效地运行。其又分为两个步骤。首先生成中间代码,为的是方便扩展,提高软件服用度,减少工作量。另一方面,是在保证程序能够正确运行的前提下能对代码进行优化。优化分方式分为两种,独立于机器是针对中间代码进行优化,而依赖于机器是针对机器硬件特性做优化的。
参考:《极客时间-编译原理之美》
