一、基本概念

2、有向图和无向图
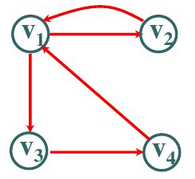
如果边是有方向的则称为有向图,如果边没有方向则称为无向图
3、无权图和带权图
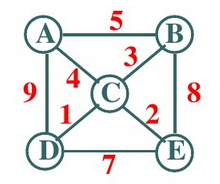
对图中的边赋予具有一定意义的数值(路程、费用等等)的图称为带权图
4、完全图:任意两个顶点之间都存在一条边
稀疏图:有很少的边
稠密图:有很多的边,最稠密的图就是完全图
5、邻接:如果两个顶点在同一条边上,则称它们互为邻接点。即(v, v') ∈ E,v和v'互为邻接点
6、顶点的度:对于无向图,顶点v的度就是和v相关联的边的条数
对于有向图,顶点v的度分为入度和出度
7、路径:非空序列V0 E1 V1 E2 ... Vk称为顶点V0到顶点Vk的一条路径。
无权图的路径长就是路径包含的边数。
有权图的路径长要乘以每条边的权。


8、图的连通性:
如果从顶点v到顶点v'有路径或从顶点v'到顶点v有路径,则称顶点v和顶点v'是连通的。
如果图中任意两个顶点都是连通的,则称该图是连通图。
对于有向图,如果图中每一对顶点Vi和Vj是双向连通的,则该图是强连通图。
9、生成树
一个连通图G的一个包含所有顶点的极小连通子图T是
①T包含G的所有顶点(n个)
②T为连通图
③T包含的边数最少(n-1条)
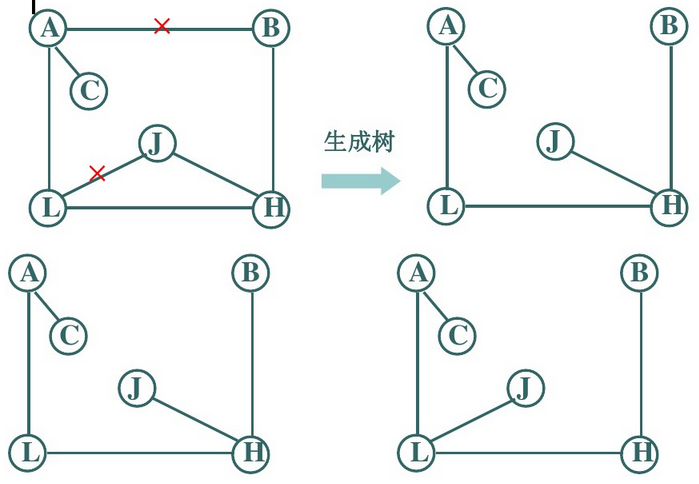
10、生成树的性质
⑴一个有n个顶点的连通图的生成树有且仅有n-1条边
⑵一个连通图的生成树并不唯一
二、图的存储结构
这部分内容摘自:https://www.cnblogs.com/polly333/p/4760275.html
1、邻接矩阵
邻接矩阵用两个数组保存数据。一个一维数组存储图中顶点信息,一个二维数组存储图中边的信息。

无向图中二维数组是个对称矩阵。
特点:
⑴0表示这两个顶点之间没有边,1表示有边
⑵顶点的度是行内数组之和
⑶求顶点的邻接点,遍历行内元素即可
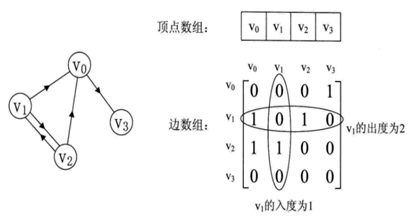
有向图的邻接矩阵:各行之和是出度,各列之和是入度
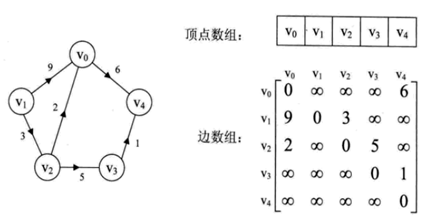
带权图的邻接矩阵表示
缺点:邻接矩阵的存储方式对于边数远远小于顶点数的图,在空间上是极大的浪费!
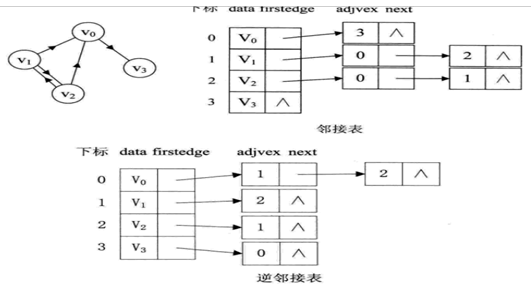
2、邻接表
即用数组和链表相结合的方式存储图(类似于链表的数组)

把顶点声明为一个枚举类型:
enum Vertex{V0,V1,V2,V3};
数组元素的类型可以表示为一个结构体:
struct Vertex_Table {
enum Vertex v; // 顶点
Adjacent *p; // 指向第一个邻接点
};
链表节点的类型也声明为一个结构体:
struct Adjacent {
int Location; // 存储某顶点的邻接点在数组中的下标位置
struct Adjacent *p // 指向下一邻接点
};
有向图可以用两个邻接表存储,出度表叫邻接表,入度表叫逆邻接表
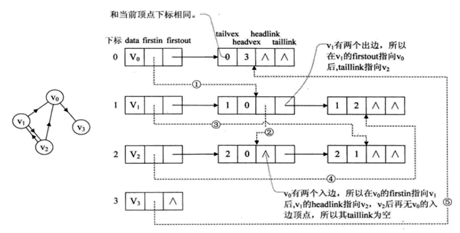
3、十字链表
邻接表对于有向图的表示分为邻接表和逆邻接表,我们无法从一个表中获取某顶点的出度和入度情况,所以有人提出了十字链表的存储方式。
顶点表:

firstin:入边表头指针,指向顶点入边表的第一个节点
firstout:出边表头指针,指向顶点出边表的第一个节点
边表:

tailvex是边起点在顶点表的下标,headvex边终点在顶点表的下标
headlink入边表指针,指向终点相同的下一条入边;taillink出边表指针,指向起点相同的下一条出边
三、图论算法
1、拓扑排序
研究的是有向无圈图
2、最短路径
已知图G,把其中一个顶点V作为输入,求V到图中其它顶点的所有路径的最小值。
①无权图 ②赋权图——Dijkstra算法
3、最小生成树
在一给定的无向图G=(V,E)中,最小生成树具有下面的性质
①包含图G的所有顶点 ②包含的边是E的子集
③任意两个顶点之间都是连通的 ④所有边的权重和最小
算法: Prim算法 Kruskal算法
4、关键路径
5、网络流问题