Data-Free Learning of Student Networks
论文连接:https://arxiv.org/pdf/1904.01186.pdf
论文代码:https://github.com/huawei-noah/Data-Efficient-Model-Compression/tree/master/DAFL
compressing deep models without training data.
方法:the data-free teacher-student paradigm by exploiting GAN.
论文结构如图:
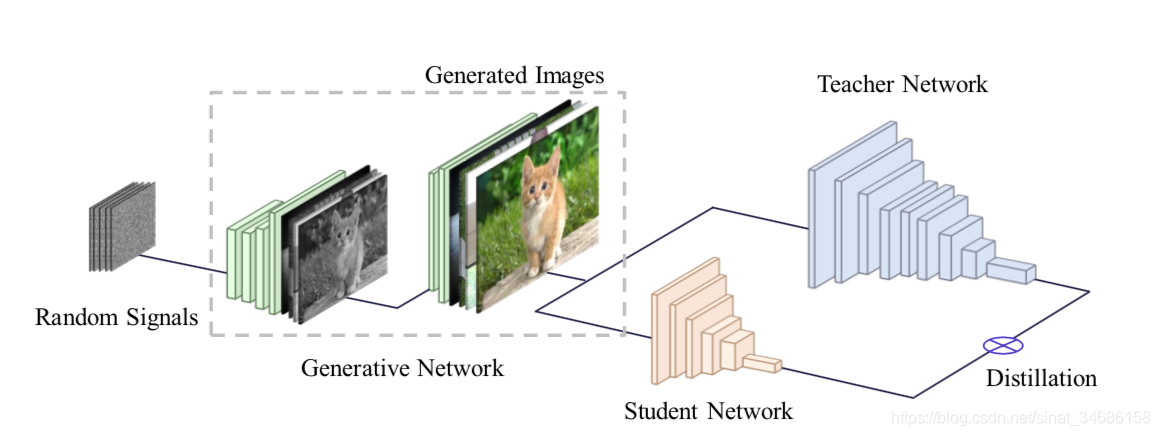
两阶段训练
1、将训练好的teacher network作为固定的判别器。输入一组随机向量,使用生成器G生成图像,然后通过teacher network优化生成器。使用 loss 函数
the parameters of original network D are fixed during training G.
G=T,而
G:判别生成图片真伪
T:判断图片类别
所以gan的loss不适用,提出以下三个loss的结合共同组成
-
one-hot loss function
输入分别表示学生网络和教师网络的输出。如果生成器G生成的图像与教师网络的训练数据分布相同,那么它们的输出也应该与训练数据具有相似的输出。因此使用one-hot loss促使教师网络生成的图像输出接近one-hot like vectors。也就是说,期望生成与教师网络完全兼容的合成图像,而不是适用于任何场景的一般真实图像。
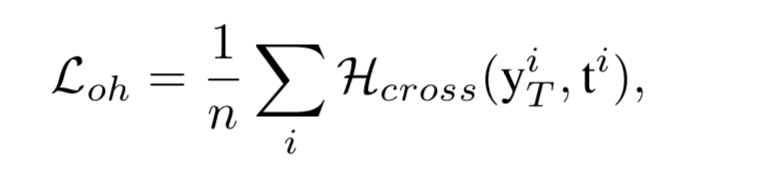
-
activation value loss
如果输入真实图像,而不是一些随机的向量,特征图往往会收到更高的激活。
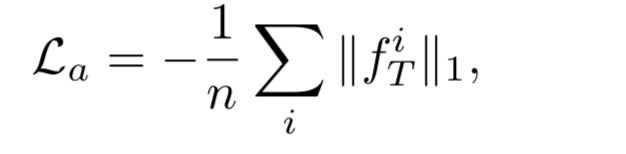
- entropy loss
训练数据的类别基本均衡,entropy loss 来衡量生成图片的类别均衡, 当所有的变量为 时得到最大值。 当loss最小的时候,每个 应该等于 。说明G生成的每个类别的图片的概率大致相等。因此, 最小化 能够得到一组类别数量均衡的生成样本。
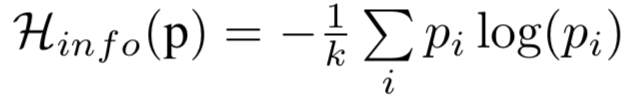
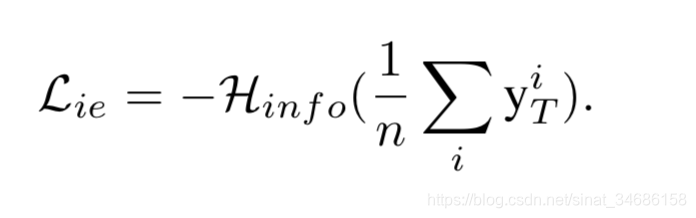
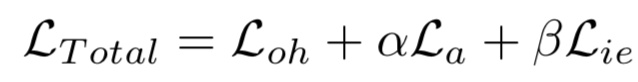
和
是超参
2、使用知识蒸馏的方法将知识从teacher network迁移到student network。使用KD loss
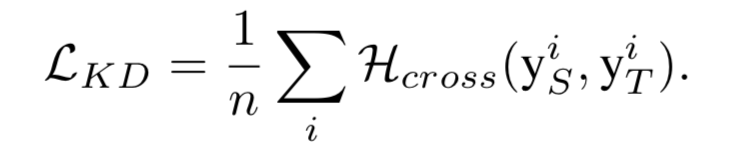
算法

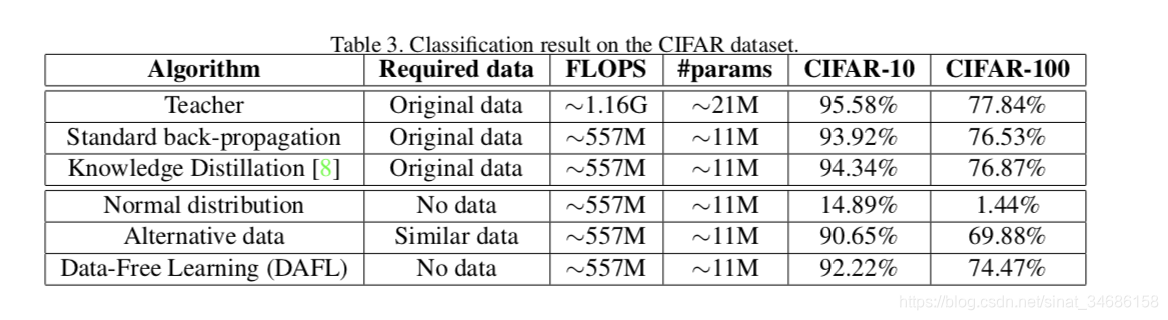
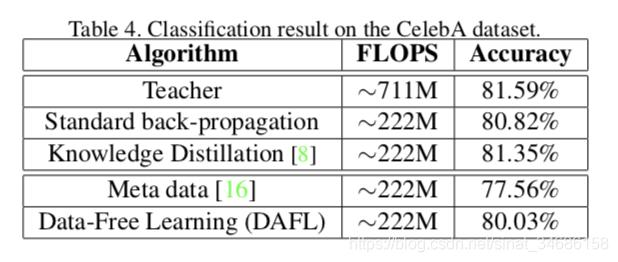
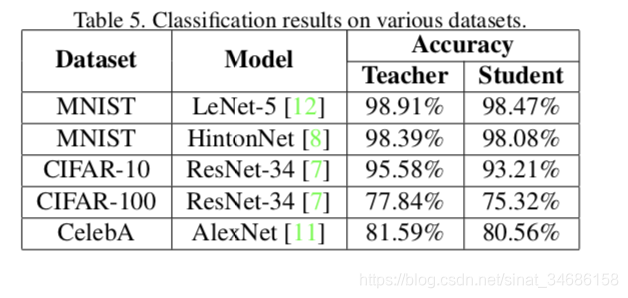
实验