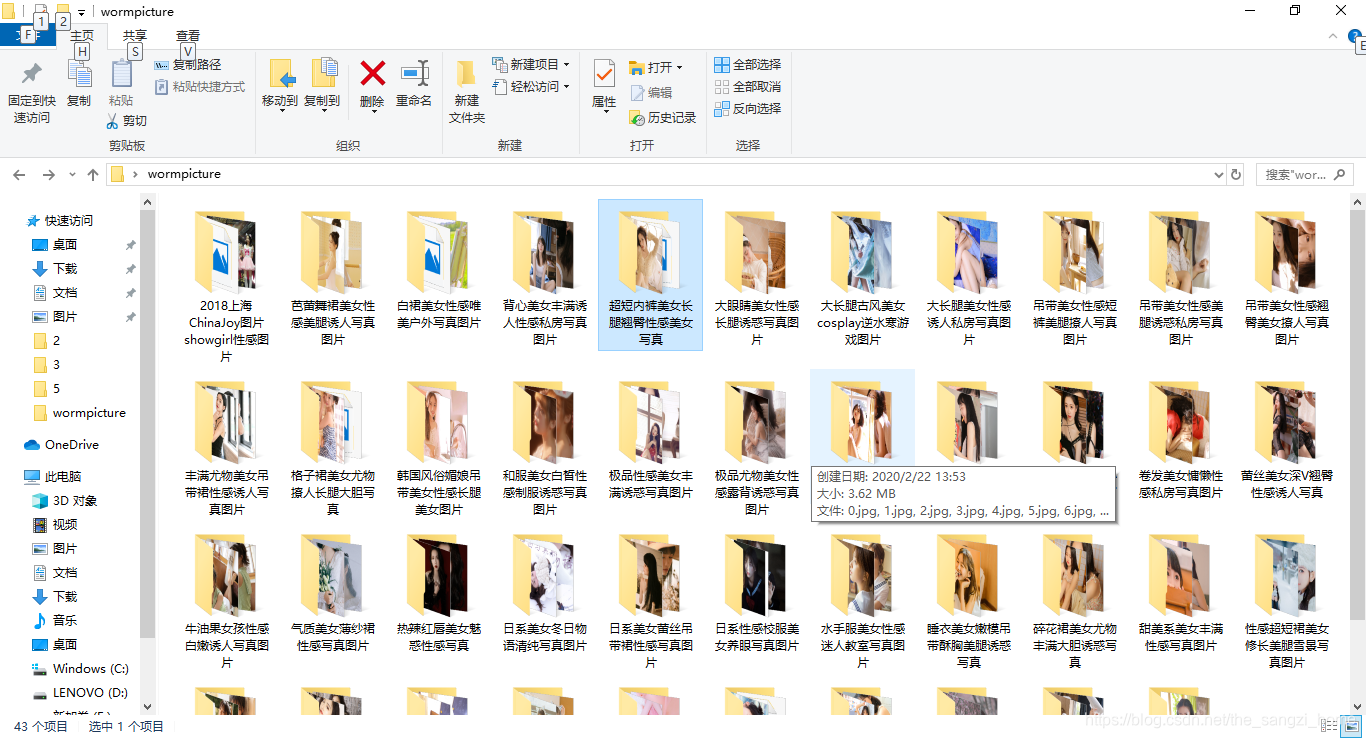
初学爬虫,将自己成功的案例贴上与大家一起进步学习。
所需环境
pycharm,第三方包下载了requests,bs4,lxml,urllib
大佬的爬虫第三方库
爬取网站图片,我选择的是这个不错的美图网站
http://www.win4000.com/
爬取过程比较顺利,直接上代码:
import time
import urllib
import requests
from bs4 import BeautifulSoup
import lxml
import re
import os
#得到页面html代码
def getPage(url):
headers = {'User-Agent':"User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"}
html = requests.get(url,headers=headers).content.decode('utf-8')
return html
#输入图片的网络url路径和存储路径进行存储操作
def savaImg(picurl,saveurl):
bytes = urllib.request.urlopen(picurl)
file = open(saveurl,'wb')
file.write(bytes.read())
file.flush()
file.close()
return True
def findCount(html):
pattern = re.compile('(<span>1</span>/<em>(.*)</em>)')
try:
Count = int(re.search(pattern,html).group(1))
return Count
except:
print('找不见多少页')
return 0
#创建文件夹
def mkdir(path):
path = path.strip()
isExists = os.path.exists(path)
if not isExists:
print('创建文件夹'+path)
os.makedirs(path)
return True
else:
print('文件夹已经创建')
return False
start = time.clock()
url = "http://www.win4000.com/meinvtag7_1.html" #爬取网页路径
html = getPage(url)
soup = BeautifulSoup(html,'lxml')
picturelink = soup.find('div',class_='w1180 clearfix').find_all('a')
pictureimg = soup.find('div',class_='w1180 clearfix').find_all('img')
#print(picturelink[0]['href'])
count = 0
for img in pictureimg:
print(img['alt'],img['data-original'])
mkdir('C:/Users/Lenovo/Desktop/wormpicture/'+img['alt'])#创建文件夹
diru = 'C:/Users/Lenovo/Desktop/wormpicture/'+img['alt']+'/'
newurl = picturelink[count]['href']
newhtml = getPage(newurl)
piccount = findCount(newhtml) #该套图多少张图片
loadnumber=0
while loadnumber<piccount:
soup1 = BeautifulSoup(newhtml,'lxml')
largepicurl = soup1.find('img',class_='pic-large')['url']
if savaImg(largepicurl,diru+str(loadnumber)+'.jpg'):
print('保存成功'+img['alt']+'('+str(loadnumber+1)+'/'+str(piccount)+')')
nextlink = soup1.find('div',class_='pic-next').find('a')['href']#下一张图片链接
newhtml = getPage(nextlink)
loadnumber+=1
count+=1
end = time.clock()
print('下载成功,花费'+str(end-start)+'秒')