认知hadoop
2020年3月17日
Hadoop是Apache旗下的一套开源软件平台
Hadoop提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量 数据进行分布式处理
Hadoop的核心组件:HDFS(分布式存储)、MapReduce(分布式计算)、Yarn(资源调度引擎)
HDFS:为海量数据提供存储
块级别的分布式文件存储系统
1)NameNode(nn)存储文件的元数据
2)DataNode(dn)在本地文件系统存储文件快数据,以及快数据的校验和
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照
MapReduce为海量数据提供计算
Map阶段:切分成一个个的小任务
Reduce阶段:汇总各个小任务的结果
YARN:资源协调者、Hadoop 资源管理器,提供统一的资源管理和调度
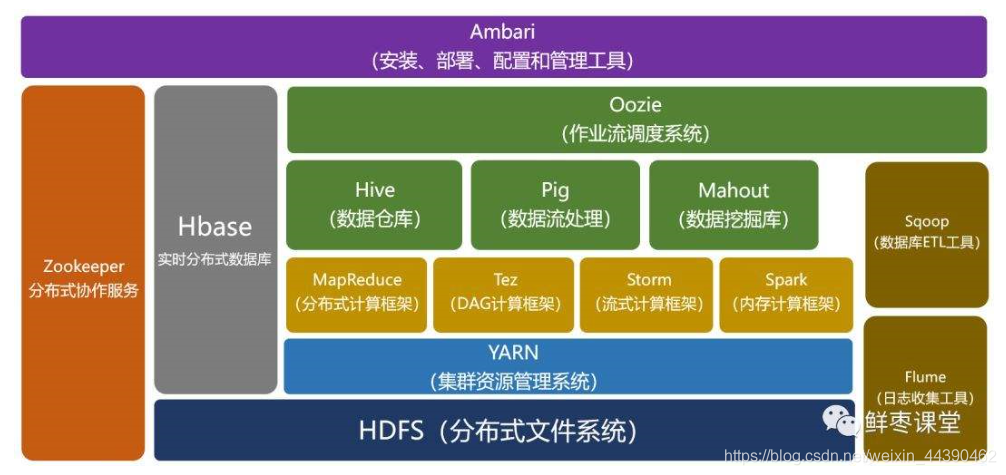
Hadoop生态圈:
业务模式:
PaaS:平台即服务
SaaS:软件即服务
Iaas:基础设施即服务
云计算的两大底层支撑技术为虚拟化和大数据技术
Hadoop是云计算的PaaS层的解决方案之一
Hadoop几种应用:
数据服务基础平台建设
用户画像
网站点击流日志数据挖掘
Hadoop的shell基础操作:
1.启动/关闭Hadoop集群
start-all.sh/stop-all.sh
2.查看HDFS上的文件和目录
hadoop fs -ls / (后面跟地址)
hadoop fs -ls -R / (递归查看全部文件)
3.在HDFS上创建文件夹
hadoop fs -mkdir -p /test/newtest
4.上传文件
hadoop fs -put source(本地文件路径)dest(HDFS路径)
5.下载文件
hadoop fs -get source(本地文件路径)dest(HDFS路径)
6.删除文件
hadoop fs -rm HDFS文件路径
hadoop fs -rm -r HDFS目录路径
7.查看文件内容
hadoop fs -cat HDFS文件路径
8.查看集群的工作状态
hdfs dfsadmin -report
附:大数据生态组件
Pig:Hadoop上的数据流执行引擎,由Yahoo开源,基于HDFS和MapReduce,使用PigLatin语言表达数据流,目的在于让MapReduce用起来更简单。
Sqoop:主要用于在Hadoop和传统数据库进行数据互导。
ZooKeeper:分布式的,开放源码的分布式应用程序协调服务。
Flume:分布式、可靠、高可用的服务,它能够将不同数据源的海量日志数据进行高效收集、汇聚、移动,最后存储到一个中心化数据存储系统中,它是一个轻量级的工具,简单、灵活、容易部署,适应各种方式日志收集并支持failover和负载均衡。
Hive:构建在Hadoop之上的数据仓库,用于解决海量结构化的日志数据统计,定义了一种类SQL查询语言。
YARN:资源协调者、Hadoop 资源管理器,提供统一的资源管理和调度。
Impala:基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata。
Solr:基于Lucene的全文检索引擎。
Hue:开源的Apache
Hadoop UI系统,基于Python Web框架Django实现的。通过使用Hue可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据。
Oozie:基于工作流引擎的服务器,可以在上面运行Hadoop任务,是管理Hadoop作业的工作流调度系统。
Storm:分布式实时大数据处理系统,用于流计算。
Hbase:构建在HDFS上的分布式列存储系统,海量非结构化数据仓库。
Spark:海量数据处理的内存计算引擎,Spark框架包含Spark
Streaming、Spark SQL、MLlib、GraphX四部分。
Mahout:Apache
Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现。
Drill:低延迟的分布式海量数据(涵盖结构化、半结构化以及嵌套数据)交互式查询引擎,使用ANSI SQL兼容语法,支持本地文件、HDFS、HBase、MongoDB等后端存储,支持Parquet、JSON、CSV、TSV、PSV等数据格式。
Tez:有向无环图的执行引擎,DAG作业的开源计算框架。
Shark:SQL on Spark,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业。

