spark Join空值操作
开门见山
- 准备数据:
val struct1: StructType = StructType(Seq(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", StringType, true)
))
val javaRows: util.List[Row] = List[Row](
Row(1, "zhangsan", "18"),
Row(1, null, "19"),
Row(2, "wangwu", "24"),
Row(4, "maliu", "16")
).asJava
val struct2: StructType = StructType(Seq(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("english", StringType, true)
))
val javaRows1: util.List[Row] = List[Row](
Row(1, "xiaohong", "64"),
Row(1, null, "56"),
Row(3, "xiaomin", "65"),
Row(4, null, "83")
).asJava
val df1: DataFrame = spark.createDataFrame(javaRows, struct1)
val df2: DataFrame = spark.createDataFrame(javaRows1, struct2)
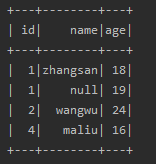
- df1的内容如下:
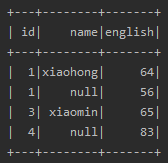
df2的内容如下:
如果按照id和name两个字段进行join操作的话:
eg1:利用spark默认的join操作:
df1.join(df2, Seq[String]("id","name"), "inner").show()
结果如下:
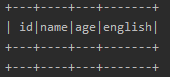
可以看出来,结果中的数据量为0
要让spark对null值在join中也进行比较的话,需要利用<=>符号,代码改写如下:
df1.join(df2,df1("id")<=>df2("id") && df1("name ")<=>df2("name"),"inner").show()
运行的结果如下:
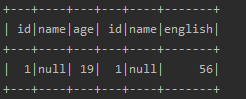
可以看到结果中有一条数据(因为这次对null值也进行了比较操作)
接下来我嫌这个表达式要写很长,所以我自定义了一个方法:
def joinWithEqualNullSafe(spark: SparkSession, dataFrame1: DataFrame, dataFrame2: DataFrame, columns: Seq[String], joinType: String) = {
val equalNullSafeExprColumn: Column = columns.map(x => {
dataFrame1.col(x).<=>(dataFrame2(x))
}).reduce((x, y) => {
x.&&(y)
})
val dataFrame1Columns: Array[Column] = dataFrame1.columns.map(dataFrame1(_))
val dataFrame2Columns: Array[Column] = dataFrame2.columns.diff(columns).map(dataFrame2(_))
dataFrame1.join(dataFrame2, equalNullSafeExprColumn, "inner").select(dataFrame1Columns++dataFrame2Columns:_*)
}
调用这个方法:
joinWithEqualNullSafe(spark, df1, df2, Seq[String]("id","name"), "inner").show()
产生结果:
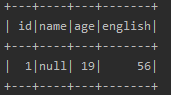
得到以上的结果(这里删去了原本df2中的id,name两列)
总结
这篇文章我最关心的是我自定义的方法有没有其他更好的实现方式,如果不小心阅读这篇文章的你有更好的想法的话,请在文章下面留言,让我学习学习,谢谢!感激不尽!
