微机接口【第一课摘要】
CPU的结构
在第一课里写到,程序是保存在硬盘中的,要载入内存才能高效运行,CPU也被设计为只能从内存中读取数据和指令。
对于CPU来说,内存仅仅是一个存放指令和数据的地方,并不能在内存中完成计算功能,例如要计算 a = b + c,必须将 a、b、c 都读取到CPU内部才能进行加法运算。为了了解具体的运算过程,我们不妨先来看一下CPU的结构。
CPU是一个复杂的计算机部件,它内部又包含很多小零件,如下图所示:
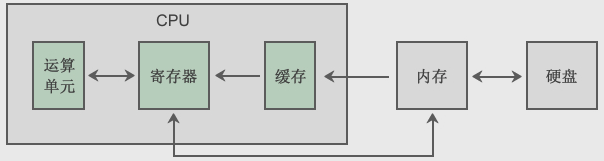
运算单元是CPU的大脑,负责加减乘除、比较、位移等运算工作,每种运算都有对应的电路支持,速度很快。
寄存器(Register)是CPU内部非常小、非常快速的存储部件,它的容量很有限,是 CPU 运算时存放、处理数据的地方。
现在我们说的 16位、32 位、64 位、128 位系统,就来源于寄存器的位数。
一般来说,2007 年或以上的计算机是 64 位系统,2007 年以下的是 32 位系统。
对于32位的CPU,每个寄存器一般能存储32位(4个字节)的数据,对于64位的CPU,每个寄存器一般能存储64位(8个字节)的数据。为了完成各种复杂的功能,现代CPU都内置了几十个甚至上百个的寄存器,嵌入式系统功能单一,寄存器数量较少。
我们经常听说多少位的CPU,指的就是寄存器的的位数。现在个人电脑使用的CPU已经进入了64位时代,例如 Intel 的 Core i3、i5、i7 等。
寄存器在程序的执行过程中至关重要,不可或缺,它们可以用来完成数学运算、控制循环次数、控制程序的执行流程、标记CPU运行状态等。
那么,在CPU内部为什么又要设置缓存呢?
在第一课里写到:负责计算的 CPU 速度很快,而从纸袋的打孔卡读取计算步骤的速度非常慢,因此现在的设计是先一次性地把打孔卡的程序信息读进来,存到内存里,而后在计算过程中让 CPU 直接和内存交换信息,这就能大大加快计算速度。
虽然内存的读取速度已经很快了,但是和CPU比起来,还是有很大差距的,不是一个数量级(西瓜和大象也不是一个数量级的)的,如果每次都从内存中读取数据,会严重拖慢CPU的运行速度,CPU经常处于等待状态,无事可做。
在CPU内部设置一个缓存,可以将使用频繁的数据暂时读取到缓存,需要同一地址上的数据时,就不用大老远地再去访问内存,直接从缓存中读取即可。
大家在购买CPU时,也会经常关心缓存容量,例如 Intel Core i7 3770K 的三级缓存为 8MB,二级缓存为 256KB,一级缓存为 32KB。容量越大,CPU越强悍。
缓存的容量是有限的,CPU只能从缓存中读取到部分数据,对于使用不是很频繁的数据,会绕过缓存,直接到内存中读取,所以不是每次都能从缓存中得到数据。
寄存器这个小而快速的存储部件,在程序运行过程中起着至关重要的作用,CPU就是用它来记录程序的运行状态,然后根据它的值再决定下一步的操作…
运算器的底层逻辑:开关网络
在第一课摘要里,我们认识了 图灵、冯诺伊曼、摩尔、阿姆达尔 这些大佬,每一位在计算机历史上都有举重若轻的地位,不可代替。
我们感受一下呼吸巨人的气息,今天像您介绍另一位大佬:香农。
CPU 来源于,22岁的香农在硕士毕业时发表的一篇论文,名为《开关网络》,开关就俩种状态,开 or 关。
因此,他的那篇硕士论文后来被誉为了20世纪最重要的硕士论文。
CPU 和中国也有共同点,中国有十几亿人口,而 CPU 里也有十几亿的晶体管。
我们的国家是分层管理的,从乡到县,从县到厅,从厅到省,从省到国家,都是一级一级管理的。
CPU便是由十几亿的晶体管以分层的思想,制造出来的。
在《开关网络》这篇论文里,香浓大佬解释了一切的逻辑运算如何用开关实现。
所以,晶体管您可以直观理解为开关,而十几亿开关组成的 CPU,也可以直观理解成 开关网络。
一个晶体管(开关)如图:

普通晶体管 有 3 极(三只脚):
gate : 栅极 source : 源极 drain : 漏极
- 栅极 电压高时,源极和漏极会连通,等同 开关打开
- 栅极 电压低时,源极和漏极会断开,等同 开关关闭
而互补晶体管 ,结构和功能与晶体管几乎一致:

互补晶体管 也是 3 极(作用却是相反的):
- 栅极 电压高时,源极和漏极会断开,等同 开关关闭
- 栅极 电压低时,源极和漏极会连通,等同 开关打开
那晶体管是如何分层的 ?
所有信息都可以只用 0 和 1 两个数字编码,作出各种电路逻辑实现运算。
比如,一个晶体管和一个互补晶体管来实现一个叫做 “非门” 的东西。
非门的功能就是您输入 0 ,TA给您输出 1,输入 1 TA输出 0。
如果用高电压代表 1,低电压代表 0。
只要把一个晶体管和一个互补晶体管像下图这样连在一起,就是一个非门:

比如您在输入端(in)接一个 3V 的高压(代表1),像图中中间的情况,我们知道下面的晶体管会“开”,所以输出(out)会和下面的低压相连接,输出就是低压(代表0)。
反过来说如果您输入的是低压,那就是图中右边的情况,上面的互补晶体管会开,输出就会和上面的高压相连接,输出就是高压。
“非门”是一个逻辑门。
一般来说,所谓逻辑门的功能就是对输入的 0 或者 1 进行操作,形成输出。
逻辑门可以有两个输入。
比如所谓“与门”,就是当且仅当输入的 A 和 B 都是 1 时,才会输出 1,否则一律输出 0。
类似地,还有“或门”、“与非门”、“异或门”等等。

下图就是顺着分层的思想,做的一个由 400 个晶体管、76个逻辑门 组成的运算器:

输入 A 和 B 两个二进制的 4位数,能判断 A 和 B 是否相等,还能计算 A+B 和 A-B。
香农在他的那篇硕士论文里就设计了一个类似的运算器。
运算器是计算机 CPU 的一部分,CPU 中还有 “数字同步逻辑”之类的组件,但是不管 CPU 有多复杂多高级,也是用各种逻辑门组成的,而逻辑门是用开关做的。
CPU 本质上就是一个开关网络!开关的功能是如此的简单。
只能根据两种命令完成两个动作,虽然是纯机械化地事,没有任何智能;但是亿万个这样的开关组成在一起,就是 CPU,就能运行软件,就能实现人工智能。
最后 程序员小哥哥 只需要对一块 CPU,而不是十几亿个晶体管编程。
很厉害,是吗~
分层可以使简单的东西解决复杂的问题,似积木。
小结:
大佬的开关网络,可以简单理解为,是将所有的加减乘除运算都可以变成布尔的二进制的逻辑运算(0 和 1 的 与、或、非),二进制就和简单的电路之间搭起了一座桥梁。
科学研究需要找到基本的颗粒。物理学找到了原子,生物学找到了细胞和基因,信息学找到了比特和晶体管。探求世界奥秘和改变世界的过程,其实就是搞清楚它们的基本单元和构建它们之间关系的过程。
像香农的开关网络、图灵的图灵机都是先搞清楚基本的颗粒,而后用简单的方法 KO 。如果一个人、一个团队搞一个项目,而他们不清楚问题的本质,一开始没什么问题,但后来为了实现复杂的功能,发明的复杂度也随之提高,最后谁都驾驭不了,那项目肯定是做不成的。
CPU的数据处理
计算机的物理结构由寄存器(存储位模式)和逻辑电路(计算寄存器中数据的功能)组成。
这些逻辑电路将信号从输入寄存器传播到输出寄存器需要一定的时间。
如果在电路稳定之前提供了新的输入,则后续电路可能会误读输出。
工程师通过向计算机添加时钟解决了这个问题。
在每个时钟的滴答声中,逻辑电路的输出被存储在寄存器中。
节拍之间的间隔足够长,以保证电路在其输出被存储之前完全稳定下来。
如果没有时钟,冯·诺依曼架构的计算机就无法运行。
时钟的存在,也为数字领域的 “算法步骤” 提供了精确的物理解释。
在尝试下一个步骤之前,必须完成每个算法步骤。
如果没有 “步” 这个概念,各方面的计算没有协调,可能会导致两组电信号同时出现,系统就会出错,使用 “步” 的概念后也解决了 CPU 时钟的同步。
因此,时钟说是 CPU 的 心脏 也不为过 ~
今天的计算机按其时钟频率进行评级 - 例如,“3.8 GHz处理器” 的时钟频率为每秒 38 亿次,即 1 GHz = 10 亿次。
在过去几十年里(受摩尔定律影响),CPU频率在计算机的发展过程中飞速提升。从最初的几十 KHz,到后来的几百 MHz,再到现在的 4GHz,终于因为硅晶体的物理特性很难再提升,只能向多核方向发展。
时钟的频率决定了CPU单位时间内的数据处理次数。
决定了计算机的数据处理能力和寻址能力(性能)不止有 时钟,还有一个数据总线。
数据总线:用于在CPU和内存之间传输数据。
CPU一次(时钟一步内)能处理的数据的大小:
- 由寄存器的位数和有多少根数据总线决定(通常它们是相等的)。
数据总线的宽度和时钟的频率都是CPU的重要指标:
- 数据总线决定了CPU单次的数据处理能力
- 主频决定了CPU单位时间内的数据处理次数
- 它们的乘积就是CPU单位时间内的数据处理量
内存对齐与寻址
计算机内存是以字节(Byte)为单位划分的,理论上CPU可以访问任意编号的字节,但实际情况并非如此。
CPU 通过地址总线[^数据总线和地址总线不是一回事,数据总线用于在CPU和内存之间传输数据,地址总线用于在内存上定位数据]来访问内存,一次能处理几个字节的数据,就命令地址总线读取几个字节的数据。
32 位的 CPU 一次可以处理 4个字节 的数据,那么每次就从内存读取 4个字节 的数据;少了浪费频率,多了没有用。
64位的处理器也是这个道理,每次读取8个字节。
以32位的CPU为例,实际寻址的步长为 4个字节,也就是只对编号为 4 的倍数的内存寻址,例如 0、4、8、12、1000 等,而不会对编号为 1、3、11、1001 的内存寻址。
如下图所示:

这样做可以以最快的速度寻址:不遗漏一个字节,也不重复对一个字节寻址。
将一个数据尽量放在一个步长之内,避免跨步长存储,这称为内存对齐。
在32位编译模式下,默认以4字节对齐;在64位编译模式下,默认以8字节对齐。
为了提高存取效率,编译器会自动进行内存对齐的。
如果只是编程,寻址方面知道内存对齐就可以了;如果是底层安全,还需要研究各种模式下的寻址方式。
复盘:
