目录
一、聚合函数
聚合函数是 一类比较特殊的函数, 其可以对多行进行一些计算,然后得到一个结果值, 更确定的说,比如:常用的 count。
说明:collect_list 不去重,collect_set 去重
1)创建原数据表
drop table if exists stud; create table stud (name string, area string, course string, score int);2)向原数据表中插入数据
insert into table stud values('zhang3','bj','math',88);
insert into table stud values('li4','bj','math',99);
insert into table stud values('wang5','sh','chinese',92);
insert into table stud values('zhao6','sh','chinese',54);
insert into table stud values('tian7','bj','chinese',91);3)查询表中数据


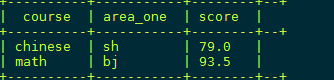
4)把同一分组的不同行的数据聚合成一个集合
select course,collect_set(area) as area ,avg(score) as score from stud group by course;5) 用下标可以取某一个
二、日期处理函数
1)date_format函数(根据格式整理日期)
select date_format('2019-11-27','yyyy-MM');
可以配合使用 regexp_replace(string s string regex, string replacement)
date_format(regexp_replace(createDate,'/','-'),'yyyy-MM')
2)date_add函数(加减日期)
select date_add('2019-11-27',-1);
select date_add('2019-11-27',1);
3)next_day函数 环比 分析
(1)取当前天的下一周的周一
select next_day('2019-11-27','MO')


(2)取当前周的周一 -----下一周周一 减掉 7 天 为 本周 周一
select date_add(next_day('2019-11-27','MO'),-7);

4)last_day函数(求当月最后一天日期)
select last_day('2019-12-2');

三、case...when...then 句式
case...when...then 语句和if 条件语句类似,用于处理单个列 的查询结果。
1) 数据准备
-- 创建 emp_sex.txt
悟空 A 男
大海 A 男
宋宋 B 男
凤姐 A 女
婷姐 B 女
婷婷 B 女
-- 创建表
create table emp_sex (
name string ,
dept_it string ,
sex string
)
row format delimited fields terminated by '\t';
load data local inpath '/export/hivegui/atguigu/emp_sex.txt' into table emp_sex;需求:求出不同部门男女各多少人。结果如下: 两种风格的 SQL
-- 第一种 SQL 风格
select dept_id,
sum(
case
sex when '男' then 1 else 0
end
) male_count ,
sum (
case
sex when '女' then 1 else 0
end
)
from
emp_sex
group by
dept_id;
------------------------------------------------------
-- 第二种
select
dept_id,
sum(case
when sex='男' then 1 else 0
end
) male_count,
sum(case
when sex='女' then 1 else 0
end) female_count
from
emp_sex
group by
dept_id; 两种SQL形式 稍有 差别,结果一样。
两种SQL形式 稍有 差别,结果一样。
写一个实际的场景 例子 判断 薪资 等级范围
select name, salary
case
when salary < 50000.0 then 'low'
when salary >= 50000.0 and salary < 70000.0 then 'middle'
when salary >= 70000.0 and salary < 100000.0 then 'high'
else 'very high'
end as bracket
from
employee;四、行列互转
4.1 行转列
1)相关函数说明
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字 符串;
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
2)数据准备
-- constellation.txt
孙悟空 白羊座 A
大海 射手座 A
宋宋 白羊座 B
猪八戒 白羊座 A
凤姐 射手座 A
-- 建表
create table person_info (
name string ,
constellation string ,
blood_type string
)
row format delimited fields terminated by '\t'
load data local inpath '/export/bigdata/hivegui/constellation.txt' into table person_info;需求:把 星座 和 血型一样的 人归类到一起
-- 1. 可以先将星座和血型 两个列 合为一列
select
name,
concat(constellation,",",blood_type)
from
person_info ;
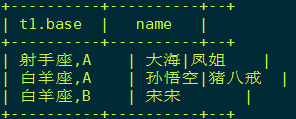
-- 2. 使用collect_set去重, collect_set本身就是聚合函数多对一
select
t1.base, -- 将 星座 ,血型放在前面
concat_ws('|',collect_set(t1.name)) name --
from (
select
name,
concat(constellation,",",blood_type) base
from
person_info
) t1
group by
t1.base;第一步: 使用concat 将 星座和血型 合为一列

第二步: 使用 collect_set ,返回 集合元素数组
4.2 列转行
1)函数说明(表生成函数,如:json_tuple,parse_url_tuple)
EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。(炸裂函数)
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合
lateral view 是UTDF的搭档(兄弟)可以把 UDTF 函数生成的表结构和原来的表进行关联操作 tabelA lateral view UDTF(xxx) 视图别名(虚拟表名) as a,b,c 此处的 UTDF可以自定义 实现 JSON 等 数据的解析
为什么 要使用 lateral view UDTF ?
不使用侧视图 会报错 UDTF's are not supported outside the SELECT clause, nor nested in expressions,使用 侧视图 生成临时表 会和 原表 进行join,将集合 或数组中与原表中的其他 字段 组合成一个新表。项目类似的UDTF自定义和UDF函数的使用很多,使用UDTF 函数将 进过过滤原始数据中一些表 转为 宽表。
看图说话

王炸后的结果

2)数据准备
-- movie.txt
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
-- 表的创建 ,数据加载
create table movie_info(
movie string,
category array<string>)
row format delimited fields terminated by "\t"
collection items terminated by ",";
load data local inpath "/export/bigdata/hivegui/movie.txt" into table movie_info;查看结果:

