目录
Lastmodified 模式:append、merge-key
sqoop的概论
sqoop产生的原因:
- 多数使用hadoop技术的处理大数据业务的企业,有大量的数据存储在关系型数据中
- 由于没有工具支持,对hadoop和关系型数据库之间数据传输是一个很困难的事
Apache框架Hadoop是一个越来越通用的分布式计算环境,主要用来处理大数据。随着云提供商利用这个框架,更多的用户将数据集在Hadoop和传统数据库之间转移,能够帮助数据传输的工具变得更加重要。Apache Sqoop就是这样一款工具,可以在Hadoop和关系型数据库之间转移大量数据(百度百科)。
sqoop的介绍
sqoop是连接关系型数据库和hadoop的桥梁,主要有两个方面(导入和导出):
- 将关系型数据库的数据导入到Hadoop 及其相关的系统中(Hadoop生态系统),如 Hive和HBase
- 将数据从Hadoop 生态圈导出到关系型数据库

准备数据 创建三张表: emp 雇员表、 emp_add 雇员地址表、emp_conn 雇员联系表。
CREATE TABLE `emp` (
`id` int(11) DEFAULT NULL,
`name` varchar(100) DEFAULT NULL,
`deg` varchar(100) DEFAULT NULL,
`salary` int(11) DEFAULT NULL,
`dept` varchar(10) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
INSERT INTO `emp` VALUES ('1201', 'gopal', 'manager', '50000', 'TP');
INSERT INTO `emp` VALUES ('1202', 'manisha', 'Proof reader', '50000', 'TP');
INSERT INTO `emp` VALUES ('1203', 'khalil', 'php dev', '30000', 'AC');
INSERT INTO `emp` VALUES ('1204', 'prasanth', 'php dev', '30000', 'AC');
INSERT INTO `emp` VALUES ('1205', 'kranthi', 'admin', '20000', 'TP');
CREATE TABLE `emp_add` (
`id` int(11) DEFAULT NULL,
`hno` varchar(100) DEFAULT NULL,
`street` varchar(100) DEFAULT NULL,
`city` varchar(100) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
INSERT INTO `emp_add` VALUES ('1201', '288A', 'vgiri', 'jublee');
INSERT INTO `emp_add` VALUES ('1202', '108I', 'aoc', 'sec-bad');
INSERT INTO `emp_add` VALUES ('1203', '144Z', 'pgutta', 'hyd');
INSERT INTO `emp_add` VALUES ('1204', '78B', 'old city', 'sec-bad');
INSERT INTO `emp_add` VALUES ('1205', '720X', 'hitec', 'sec-bad');
CREATE TABLE `emp_conn` (
`id` int(100) DEFAULT NULL,
`phno` varchar(100) DEFAULT NULL,
`email` varchar(100) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
INSERT INTO `emp_conn` VALUES ('1201', '2356742', '[email protected]');
INSERT INTO `emp_conn` VALUES ('1202', '1661663', '[email protected]');
INSERT INTO `emp_conn` VALUES ('1203', '8887776', '[email protected]');
INSERT INTO `emp_conn` VALUES ('1204', '9988774', '[email protected]');
INSERT INTO `emp_conn` VALUES ('1205', '1231231', '[email protected]');Sqoop 导入
Sqoop 导入单个表从 RDBMS 到 HDFS。表中的每一行被视为 HDFS 的记 录。所有记录都存储为文本文件的文本数据
全量导入 mysql 表数据到 HDFS
连接 Sqoop 执行数据导入 到HDFS,从 MySQL 数据库服务器中的 emp 表导入 HDFS
bin/sqoop-import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--target-dir /sqoopresult \
--table emp --m 1
全量导入 mysql 表数据到 HIVE
方式一:
第一步:先复制表结构到 hive 中再导入数据 (两步走战略)
将关系型数据的表结构复制到hive中
bin/sqoop-create-hive-table \
--connect jdbc:mysql://node03:3306/userdb \
--table emp_add \
--username root \
--password 123456 \
--hive-table sqoop_test.emp_add_sp 从Hive 中查看表结构已经存在。
从Hive 中查看表结构已经存在。
第二步:从关系数据库导入文件到 hive 中
bin/sqoop-import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp_add \
--hive-table sqoop_test.emp_add_sp \
--hive-import \
--m 1
现在回到 Hive 中 再查看一下关系数据库中的文件是否导入到Hive中

如果 数据 库 不 存在 会怎么样了(因为第一次执行时数据库的名字 指定的不对)
执行 数据导入 到 Hive , 执行 mapreduce 将 产生 一个 临时的 HDFS 文件,然后将这个数据文件加载进Hive 数据库 的表中 , 最后删除这个临时的 HDFS文件。 如果失败 请将这个 临时 文件删除掉,再执行导入
方式二:直接复制表结构数据到 hive 中
方式二:直接导入数据到hive中 包括表结构和数据
bin/sqoop-import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp_conn \
--hive-import \
--m 1 \
--hive-database sqoop_test;到 Hive 中查询 一下

导入表数据子集(where 过滤)
--where 可以指定从关系数据库导入数据时的查询条件。它执行在数据库服 务器相应的 SQL 查询,并将结果存储在 HDFS 的目标目录。
执行 表数据子集
导入表数据子集
Where查询过滤导入:
bin/sqoop-import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--where "city ='sec-bad'" \
--target-dir /wherequery \
--table emp_add --m 1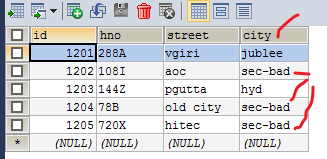

导入表数据子集(query 查询)
- 使用 sql 语句来进行查找是不能加参数--table
- 并且 必须要 添加 where条件
- 并且where条件后面必须带一个$CONDITIONS 这个字符串
- 并且这个sql语句必须用单引号,不能用双引号
bin/sqoop-import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--target-dir /wherequery12 \
--query 'select id,name,deg from emp WHERE id>1203 and $CONDITIONS' \
--split-by id \
--fields-terminated-by '\001' \
--m 2sqoop命令中 –split-by id 通常配合-m 10参数使用。首先 sqoop 会向关系型数据库比如mysql发送一个命令:select max(id),min(id) from test。然后会把max、min之间的区间平均分为 10 分,最后10个并行的map去找数据库,导数据就正式开始。
增量导入
在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据每次都全部导入到 hive 或者hdfs 当中去,这样会造成数据 重复的问题。因此一般都是选用一些字段进行增量的导入, sqoop 支持增量的 导入数据。 增量导入是仅导入新添加的表中的行的技术。
--check-column (col)用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数进行导入,和关系型数据库中的自增字段及时间戳类似。 注意:这些被指定的列的类型不能 是 任意字符类型,如 char、varchar 等类 型都是不可以的,同时-- check-column 可以去指定多个列。
--incremental (mode)append:追加,比如对大于 last-value 指定的值之后的记录进行追加导入。
lastmodified:最后的修改时间,追加 last-value 指定的日期之后的记录
--last-value (value) 指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值。
Append 模式增量导入
执行以下指令先将我们之前的数据导入:
Append模式
执行以下指令先将我们之前的数据导入
bin/sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--target-dir /appendresult \
--table emp --m 1
在mysql的emp中插入2条数据:
insert into `userdb`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) values ('1206', 'allen', 'admin', '30000', 'tp');
insert into `userdb`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) values ('1207', 'woon', 'admin', '40000', 'tp');执行如下的指令,实现增量(append)的导入:
bin/sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp --m 1 \
--target-dir /appendresult \
--incremental append \
--check-column id \
--last-value 1205
很明显的可以 看到 两条记录 更新 到了

增量导入小结:
--incremental append 表示使用谁家导入模式
--check-column id 和 --last-value 1205 表示上一次导入关系型数据库的最后一条数据是 id 为1205的 数据 ,现在从 1205 后面开始 导入。 注意 L检查字段的类型必须是 int
Lastmodified 模式增量导入
首先我们要创建一个customer表,指定一个时间戳字段
create table customer_test(id int,name varchar(20),last_mod timestamp default current_timestamp on update current_timestamp);
此处的时间戳设置为在数据的产生和更新时都会发生改变
INSERT INTO customer_test(id,NAME) VALUES(1,'neil');
INSERT INTO customer_test(id,NAME) VALUES(2,'jack');
INSERT INTO customer_test(id,NAME) VALUES(3,'martin');
INSERT INTO customer_test(id,NAME) VALUES(4,'tony');
INSERT INTO customer_test(id,NAME) VALUES(5,'eric');执行sqoop指令将数据导入hdfs:
此时执行sqoop指令将数据导入hdfs:
bin/sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--target-dir /lastmodifiedresult \
--table customer_test --m 1查看此时导出的结果数据:

INSERT INTO customer_test(id,NAME) VALUES(6,'james')日志的打印 , Retrieved 6 records.


此处已经导入了我最后插入的一条记录,但是却发现此处插入了 6 条数据,这是为什么呢?
因为采用 lastmodified 模式去处理增量时,会将大于等于 last-value 值的数据当做增量插入,而我的前五条记录时间戳相等,就导致 了 6 条 数据的 插入 。
Lastmodified 模式:append、merge-key
更新之后,这条数据的时间戳会更新为我们更新数据时的系统时间.
执行如下指令,把id字段作为merge-key:
bin/sqoop-import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table customer_test \
--target-dir /lastmodifiedresult \
--check-column last_mod \
--incremental lastmodified \
--last-value "2019-11-04 10:15:58" \
--m 1 \
--merge-key id
Sqoop 导出
将数据从 Hadoop 生态体系导出到 RDBMS 数据库导出前,目标表必须存在于 目标数据库中
- 默认操作是从将文件中的数据使用 INSERT 语句插入到表中;
- 更新模式:Sqoop 将生成 UPDATE 替换数据库中现有记录的语句;
- 调用模式:Sqoop 将为每条记录创建一个存储过程调用;
默认模式导出 HDFS 数据到 mysql
默认情况下, sqoop export 将每行输入记录转换成一条 INSERT 语句,添加到 目标数据库表中。如果数据库中的表具有约束条件(例如,其值必须唯一的主键 列)并且已有数据存在,则必须注意避免插入违反这些约束条件的记录。如果 INSERT 语句失败,导出过程将失败。 此模式主要用于将记录导出到可以接收这些 结果的空表中 。通常用于全表数据导出。 导出时可以是将 Hive 表中的全部记录或者 HDFS 数据(可以是全部字段也可 以部分字段)导出到 Mysql 目标表。
准备 HDFS 数据
1201,gopal,manager,50000,TP
1202,manisha,preader,50000,TP
1203,kalil,php dev,30000,AC
1204,prasanth,php dev,30000,AC
1205,kranthi,admin,20000,TP
1206,satishp,grpdes,20000,GRUSE userdb;
CREATE TABLE employee (
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(20),
deg VARCHAR(20),
salary INT,
dept VARCHAR(10)
);
执行导出命令
bin/sqoop export \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table employee \
--columns id,name,deg,salary,dept \
--export-dir /emp_data/

相关配置参数
--input-fields-terminated-by '\t'- 指定文件中的分隔符
--columns- 选择列并控制它们的排序。当导出数据文件和目标表字段列顺序完全一 致的时候可以不写。否则以逗号为间隔选择和排列各个列。没有被包含在– columns 后面列名或字段要么具备默认值,要么就允许插入空值。否则数据 库会拒绝接受 sqoop 导出的数据,导致 Sqoop 作业失败
--export-dir - 导出目录,在执行导出的时候,必须指定这个参数,同时需要具 备--table 或--call 参数两者之一,--table 是指的导出数据库当中对应的表
--input-null-string --input-null-non-string如果没有指定第一个参数,对于字符串类型的列来说,“NULL”这个字符 串就回被翻译成空值,如果没有使用第二个参数,无论是“NULL”字符串还 是说空字符串也好,对于非字符串类型的字段来说,这两个类型的空串都会 被翻译成空值。比如:
--input-null-string "\\N" --input-null-non-string "\\N"更新导出(updateonly 模式)
-- update-key-- updatemod指定 updateonly(默认模式),仅仅更新已存在的数据记录, 不会插入新纪录
1201,gopal,manager,50000
1202,manisha,preader,50000
1203,kalil,php dev,30000 USE userdb;
CREATE TABLE updateonly (
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(20),
deg VARCHAR(20),
salary INT);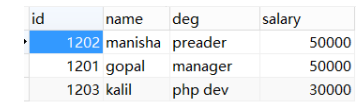
新增一个文件updateonly_2.txt:修改了前三条数据并且新增了一条记录
1201,gopal,manager,1212
1202,manisha,preader,1313
1203,kalil,php dev,1414
1204,allen,java,1515执行更新导出
执行更新导出:
bin/sqoop-export \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table updateonly \
--export-dir /updateonly_2/ \
--update-key id \
--update-mode updateonly更新导出(allowinsert 模式)
- -- update-key,更新标识,即根据某个字段进行更新,例如 id,可以指定多 个更新标识的字段,多个字段之间用逗号分隔
- -- updatemod,指定 allowinsert,更新已存在的数据记录,同时插入新纪录。 实质上是一个 insert & update 的操作
准备 HDFS 数据
在HDFS “/allowinsert_1/”目录的下创建一个文件allowinsert_1.txt:
1201,gopal,manager,50000
1202,manisha,preader,50000
1203,kalil,phpdev,30000执行全部导出操作
// 执行全部导出操作
bin/sqoop export \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table allowinsert \
--export-dir /allowinsert_1/新增一个文件 ,执行更新导出操作
allowinsert_2.txt。修改了前三条数据并且新增了一条记录。上传至/ allowinsert_2/目录下:
1201,gopal,manager,1212
1202,manisha,preader,1313
1203,kalil,phpdev,1414
1204,allen,java,1515
执行更新导出
bin/sqoop-export \
--connect jdbc:mysql://node03:3306/userdb \
--username root --password 123456 \
--table allowinsert \
--export-dir /allowinsert_2/ \
--update-key id \
--update-mode allowinsert至此Sqoop 入门案例就完成了。
