一、spark-sql shell介绍
Spark sql是以hive SQL提交spark任务到spark集群执行。
由于spark是计算框架没有存储功能,所有spark sql数据表映射关系存储在运行shell的当前目录下metastore_db目录里面(spark默认使用derby数据库创建的本地存储,使用其他非本地数据库没有此目录),切换不同的目录启动spark-sql shell会创建不同位置的metastore_db目录存储关系数据。而且metastore_db目录在spark-sql shell里面访问权限是独占的,同一个目录只能启动一个spark-sql shell进程,多启动会报错。
二、启动spark-sql shell
--driver-class-path是指定driver程序启动数据库连接驱动类库
--jars是给worker执行调用的类库,需要指定数据库连接驱动类库
数据库连接驱动类库放在spark-sql机器的指定目录。也可以添加到spark集群每台机器的spark安装目录的jars目录下,这样就不用指定--driver-class-path --jars
cd ~/software/spark-2.4.4-bin-hadoop2.6
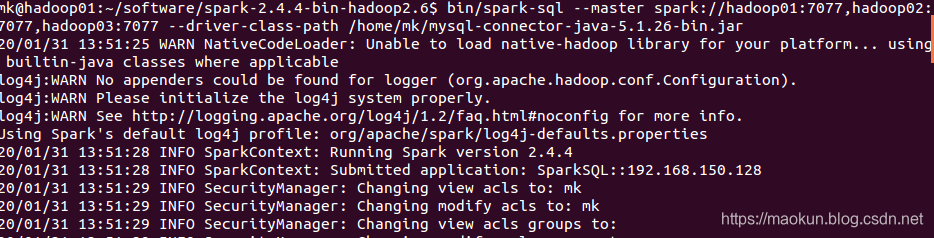
bin/spark-sql --master spark://hadoop01:7077,hadoop02:7077,hadoop03:7077 --driver-class-path /home/mk/mysql-connector-java-5.1.26-bin.jar --jars /home/mk/mysql-connector-java-5.1.26-bin.jar
执行结果:

三、执行sql
(1)创建表
create table test(id int, name string)
USING org.apache.spark.sql.jdbc
options(url 'jdbc:mysql://192.168.150.1:3306/spark-mysql?user=root&password=admin', dbtable 'test_a');
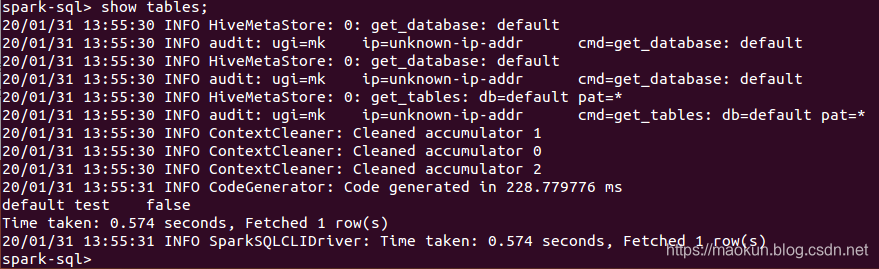
show tables;

(2)插入数据
insert into test values(1, 'a'), (2, 'b'), (3, 'c');
select * from test;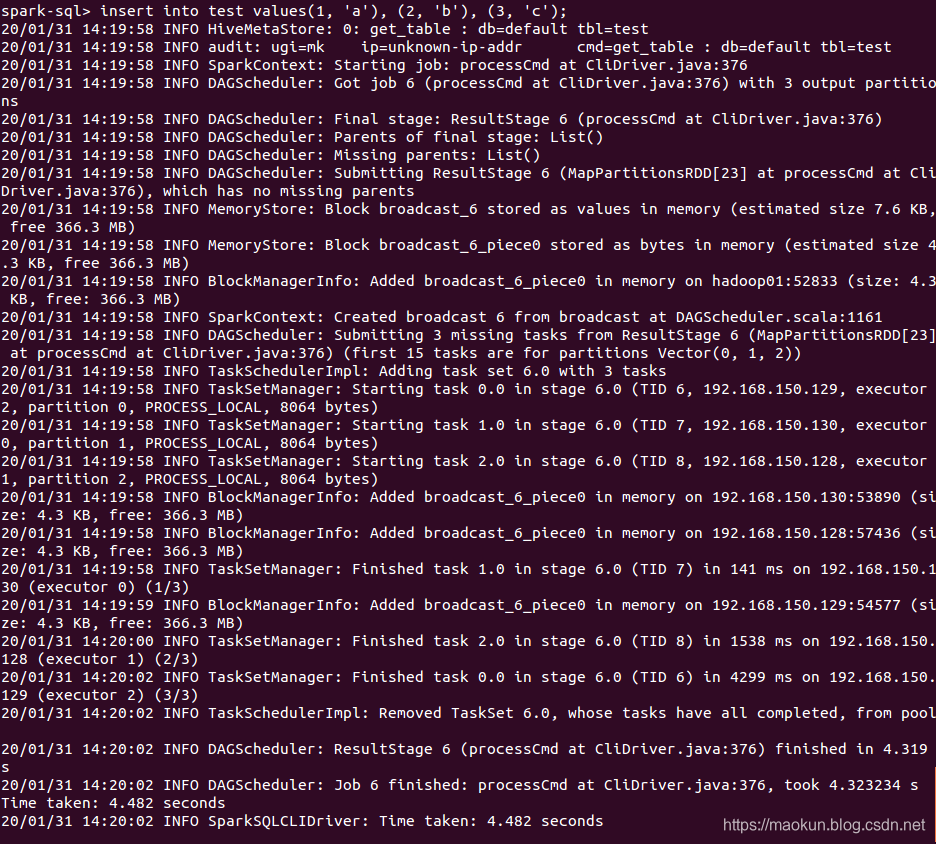
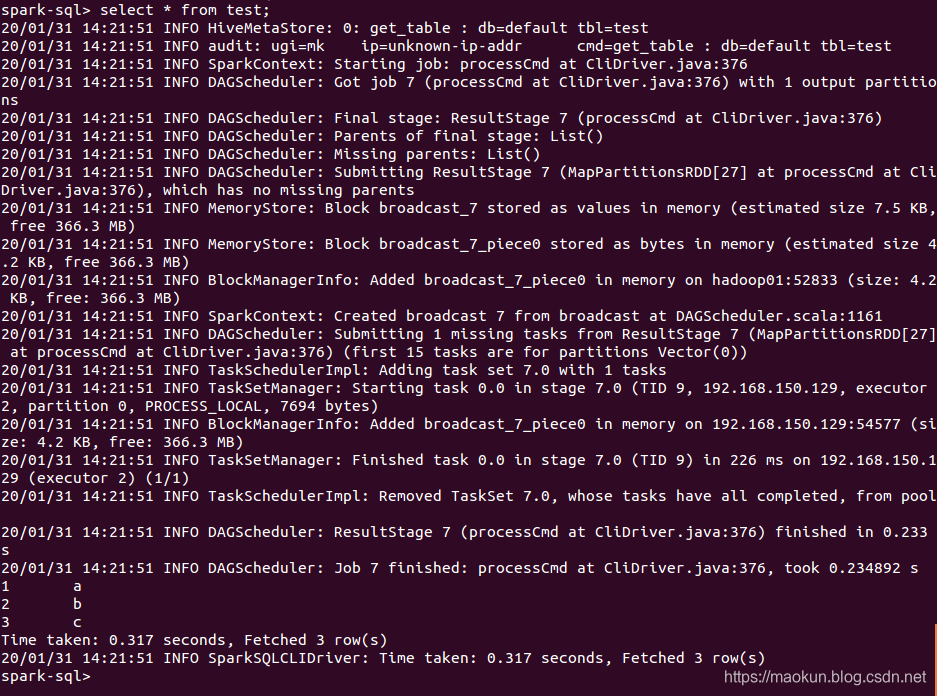
(3) 删除元数据表
drop table test;