前言
本文介绍了人脸匹配的基本概念及分类,罗列出了人脸匹配算法的几种常见性能评价指标(其中详细介绍了其中用于评估人脸识别性能的CMC曲线),并对人脸匹配方法中用到的两个传统机器学习方法进行了概要性介绍,最后阐述了使用深度学习提取特征相比使用特征工程提取图像特征的优势。
1.什么是人脸匹配
人脸匹配大体上包括人脸验证、人脸识别和人脸检索三大方面。
- 人脸验证:输入为一个人脸图片,要匹配的也是一张人脸,我们要做的,就是检验这两张脸是否是同一个人。这是一个 1:1 的问题。人脸签到、刷脸登录就是人脸验证的典型应用。
- 人脸识别:给定一张人脸图,要去判断这个人脸对应的是谁。判断的方法是:将输入的人脸与数据库里已经存在的 n 张人脸分别进行相似度的计算,找出相似度最高的那个人脸,如果计算出来的这个最高的相似度还没有达到可以确定两张脸为同一个人的最低阈值,那么就可以确定输入的这张脸不是数据库里的人。如果这个最高的相似度超过了阈值,那么就可以认为这个相似度最高的脸就是与输入的人脸匹配的那个人的脸。显然,人脸识别是一个 1:n 的问题。
- 人脸检索:本质与人脸识别相似,只不过人脸检索只需要返回数据库里与输入人脸前 n 个相似度最高的人脸,再对这前n个人脸按照相似度从高到低进行排序即可。排序之后的n张人脸图像组成一个Rank人脸数据集,人脸识别返回的结果( 注意 :这个结果可能是对的,也可能是错的)就是Rank里排名第一的那个人脸(即Rank1)。
2.人脸匹配算法性能评价指标
2.1 人脸验证性能评估
对于人脸验证问题,即判断输入人脸是否是所要求的人脸的问题,其结果无非分为“是”和“否”两种情况。这本质上是一个二分类问题。
评价一个人脸验证算法性能的好坏时,一般采用ROC曲线和PR曲线进行验证。
2.2 人脸识别性能评估
对于人脸识别问题,通常采用CMC曲线进行描述。对于排序和度量的问题可以用CMC曲线进行评价。
CMC曲线全称是Cumulative Match Characteristic (CMC) curve,也就是累积匹配曲线,同ROC曲线Receiver Operating Characteristic (ROC) curve一样,是模式识别系统,如人脸,指纹,虹膜等的重要评价指标,尤其是在生物特征识别系统中,一般同ROC曲线一起给出,能够综合评价出算法的好坏。如下图所示:
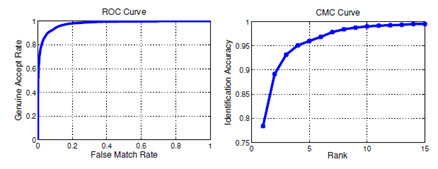
CMC曲线综合反映了分类器的性能,它的评价指标与现在深度学习中常用的top1 err或top5 err评价指标是一样的意思,不同的是这里Rank1 recognition rate表示的是正确率而不是错误率,两者的关系是:
Rank1识别率 = 1-top1 err
Rank5识别率 = 1-top5 err
它们表示的是什么意思呢?下面给出一段通俗的说法加深各位的理解:
给你一道选择题,有10个选项,但是只有一个选项是正确的,现在让你从中选出正确答案。如果让你猜一次,正确的概率为1/10,你感觉自己状态不好,想重新猜一次,现在给你机会,让你再猜一次,现在你总共猜两次,选两个答案,正确率一下子提高到1/5,你又说了,猜两次反映不出你的水平,你要猜五次,也就是从10个选项中选5个选项,这5个选项中包括正确选项的概率大大增加,变为1/2,如果让你猜10次,那蒙对的概率肯定为1了。也有人蒙的能力比较强,可能猜3次就能猜到正确答案,也就是提前收敛到1。
CMC曲线Rank1识别率就是表示按照某种相似度匹配规则匹配后,第一次就能判断出正确的标签的数目与总的测试样本数目之比,Rank5识别率就是指前五项(按照匹配程度从大到小排列后)有正确匹配。如果一个样本按照匹配程度从大到小排列后,到最后一项,才匹配到正确标签,这就说明分类器不太好,把最应匹配的判别成最不应匹配的。这样的分类器就需要我们进行优化。下面的示意图模拟了一个分类器对5张人脸进行识别的结果。

我们可以看到,每一张人脸n(n = 1,2,3,4,5)都分别对应一个标签mk(k = 1,2,3,4,5),每一张人脸对应一个输出结果,每一个输出结果都列出分类器经过计算后认为的与输入人脸相似度最高的前五张人脸所对应的标签。五个结果中,第一张图片就返回正确识别结果的有人脸1、2和5,即Rank-1的正确率为60%;前两张图片包含正确结果的有人脸1、2、3、5,即Rank-2的正确率为80%。以此类推,Rank-3、Rank-4、Rank-5的正确率分别为80%、100%、100%。由此我们就可以绘制出CMC曲线如下:

显然,CMC曲线是非递减的曲线。
对人脸检索算法性能的评价与人脸识别是几乎一样的,唯一的差别是人脸识别只返回一个结果,而人脸检索可以返回多个结果。
3.人脸匹配方法介绍
人脸匹配方法主要分为两个。一个是特征表示,一个是相似性度量。它们都是传统的机器学习方法。
3.1 特征表示
图像的特征表示是一种寻找图像中的最有效信息的方法,这种最有效信息,就称为特征。从开始的简单像素表示,到后来由像素特征组成的特征描述子(sift,surf,hog等),如何将这些特征进行加工和处理得到更加深入层次的表示,是特征表示的研究重点。
3.1.1 低层次特征
低层次特征是指颜色特征、纹理特征和形状特征等在数字图像所对应的颜色矩阵上人为设计出来的可解释的特征(即人眼可以直观观察到的特征)。下面举了几个浅显的例子。
一张数字图片中有很多个像素点,这些像素点构成了一个数字矩阵,这个矩阵称为颜色矩阵,它描述了当前图片中的颜色信息。对于彩色图像,每一个像素点都有R、G、B三个通道,故可将每一个像素点抽象成一个三维向量,进而提取出图像的颜色直方图等颜色特征。为什么要这样做呢?我们来看一个简单的例子。

上图中,左图为原始图像,右图为经过旋转变换后的图像。它们只有一个颜色通道,均为灰度图像。这两张图像对应像素点位置的像素值显然是不一样的,所以它们很容易被误认为是两张无关的图片。但是,如果我们对各图像中每个像素点对应的像素值进行数字统计,并将结果绘制成两个直方图,则这两个直方图的统计特征是完全相同的。通过对比颜色直方图,我们就能“透过表象看本质”,得知这其实是两种相同的图片,只不过是经过了一些简单的位置变换。
我们还可以这样可以通过对颜色矩阵进行运算提取更多的特征。例如,通过对矩阵进行差分运算,我们可以得到图像的纹理特征。提取纹理特征可以减少光照等外在环境因素对图像颜色信息的影响,增加特征的鲁棒性。举个例子:

左边的图像受到光照的影响,其所有像素点的像素值均提升了1。这个时候两张图像提取出来的颜色直方图是完全不同的。但是,如果对这两幅图像分别做差分运算,运算结果如下:

会发现这两幅图像差分运算的结果是完全一致的,说明这两幅图像具有相同的纹理,由此判断它们是同一幅图像,只是受到了外在扰动的影响导致像素值发生了改变。除了对光照变化具有比较好的适应性,纹理特征跟颜色直方图特征一样,对旋转也会有比较好的适应性。
形状特性提取是对纹理特征提取的深化,是对图像中的结构信息进行分析。数字图像所获取到的图像内容往往是一些物体或者一些场景,同一类物体或场景往往会有一些共同的结构性质,比如,不同的人基本的结构外形是相似的,也就是说,“人”这一类“物体”所具有的结构特性是较为固定的。利用人的结构特性,我们就可以大体上把人和其他物体及场景区分出来。
3.1.2 中层次特征
颜色特征、纹理特征和形状特征都是在数字图像所对应的颜色矩阵上人为设计出来的可解释的特征(即人眼可以直观观察到的特征),是低层次的特征。除了这三种特征以外,我们还有一种特征提取的方法:可以将一张HWC(高度宽度颜色通道数)的图像进行特征提取后转化为一个1*n的向量,对这个向量加入监督信息(如所属类别)后,利用监督信息对当前提取出来的特征再度进行优化学习,在此基础上再进一步进行特征的抽取。这一过程是一个学习的过程,提取出来的特征是中层次的特征,相比颜色、纹理和形状等人为提取的低层次特征会更加鲁棒。
进行特征表示优化学习的方法有很多种,常见的有PCA、LDA、迁移学习、稀疏表示、低秩学习、哈希学习等。
3.2 相似性度量
在做分类任务的时候,经常需要估算不同样本之间的相似性度量(Similarity Measurement),这时通常采用的方法就是计算样本间的“距离”(Distance)。计算样本之间的距离时,常用的距离有欧氏距离、 曼哈顿距离 、马氏距离 、信息熵等。
4 利用深度学习进行特征提取
上文所提到的低层次和中层次特征的提取均属于特征工程的范畴。
特征工程,是指先前的机器学习技术(浅层学习)仅包含将输入数据变换到一两个连续的表示空间,通常使用简单的变换,比如高维非线性投影(SVM)或决策树。但这些技术通常无法得到复杂问题所需要的精确表示。因此,人们必须竭尽全力让初始输入数据更适合用这些方法处理,也必须手动为数据设计好的表示层。因此,特征工程是一个非常具体的领域,需要大量的人力投入,费事费力,并且严重依赖相关领域的专家。
与此相反,深度学习完全将这个步骤自动化:
利用深度学习,我们可以一次性学习所有特征,而无须自己手动设计。这极大地简化了机器学习工作流程,通常将复杂的多阶段流程替换为一个简单的、端到端的深度学习模型。深度学习算法以自动化的方式进行特征提取,这也使得研究者用最少的领域知识和人力去提取有区别的特征成为了现实。
相比传统机器学习,深度学习还具有如下的优势:
深度学习利用神经元间转换的图形技术来开发多层次的学习模型。这样的工作机制实际上是模仿了人类大脑的工作方式:人脑可以从不同的场景中自动提取数据表示,输入是眼睛接收到的场景信息,输出是分类对象。深度学习在处理图像方面与人脑的高度相似性正是它相比传统机器学习算法的主要优势。
下图是深度学习提取图像特征的简单示意图:
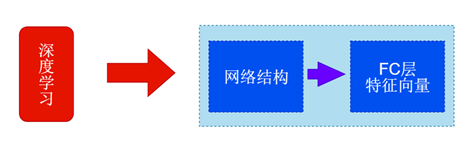
目前,利用深度学习对图像进行特征提取是主流的方法。
