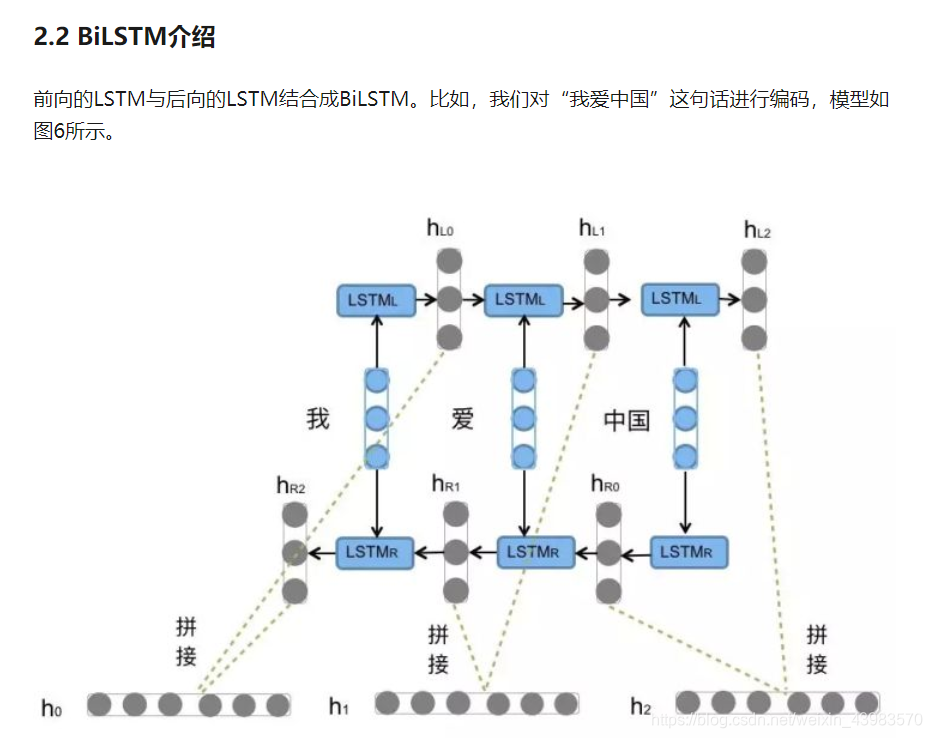
LSTM的全称是Long Short-Term Memory,它是RNN(Recurrent Neural Network)的一种。LSTM由于其设计的特点,非常适合用于对时序数据的建模,如文本数据。BiLSTM是Bi-directional Long Short-Term Memory的缩写,是由前向LSTM与后向LSTM组合而成。两者在自然语言处理任务中都常被用来建模上下文信息。
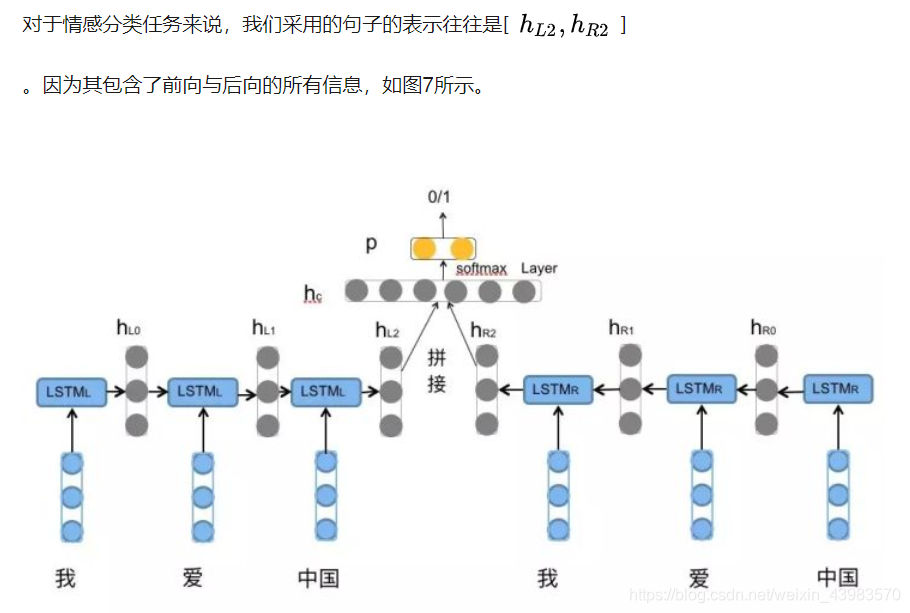
自然语言处理中情感分类任务是对给定文本进行情感倾向分类的任务,粗略来看可以认为其是分类任务中的一类。对于情感分类任务,目前通常的做法是先对词或者短语进行表示,再通过某种组合方式把句子中词的表示组合成句子的表示。最后,利用句子的表示对句子进行情感分类。
举一个对句子进行褒贬二分类的例子。
句子:我爱中国 (输入) 句子:我不喜欢你(输入)
情感标签:褒义 (输出) 贬义(输出)
根据前后文的意义不同,句子的褒贬也不同。
但是利用LSTM对句子进行建模还存在一个问题:无法编码从后到前的信息。在更细粒度的分类时,如对于强程度的褒义、弱程度的褒义、中性、弱程度的贬义、强程度的贬义的五分类任务需要注意情感词、程度词、否定词之间的交互。举一个例子,“这个餐厅脏得不行,没有隔壁好”,这里的“不行”是对“脏”的程度的一种修饰,通过BiLSTM可以更好的捕捉双向的语义依赖。
如果能像访问过去的上下文信息一样,访问未来的上下文,这样对于许多序列标注任务是非常有益的。例如,在最特殊字符分类的时候,如果能像知道这个字母之前的字母一样,知道将要来的字母,这将非常有帮助。同样,对于句子中的音素分类也是如此。
然而,由于标准的循环神经网络(RNN)在时序上处理序列,他们往往忽略了未来的上下文信息。一种很显而易见的解决办法是在输入和目标之间添加延迟,进而可以给网络一些时步来加入未来的上下文信息,也就是加入M时间帧的未来信息来一起预测输出。理论上,M可以非常大来捕获所有未来的可用信息,但事实上发现如果M过大,预测结果将会变差。这是因为网路把精力都集中记忆大量的输入信息,而导致将不同输入向量的预测知识联合的建模能力下降。因此,M的大小需要手动来调节。
双向循环神经网络(BRNN)的基本思想是提出每一个训练序列向前和向后分别是两个循环神经网络(RNN),而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。下图展示的是一个沿着时间展开的双向循环神经网络。六个独特的权值在每一个时步被重复的利用,六个权值分别对应:输入到向前和向后隐含层(w1, w3),隐含层到隐含层自己(w2, w5),向前和向后隐含层到输出层(w4, w6)。值得注意的是:向前和向后隐含层之间没有信息流,这保证了展开图是非循环的。
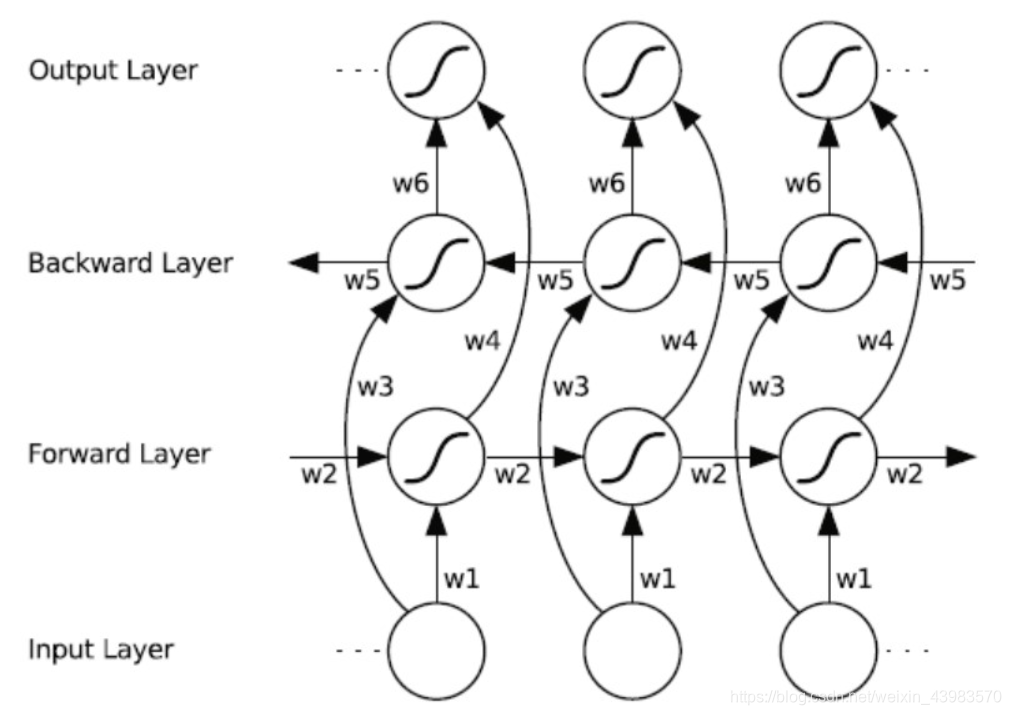
上图为将bilstm分解,综合来说就是将每个分词正向和反向信息相接,也就是每个step的数据向接就可以得到数据的输出,并且每一个的权重参数都是独特的。
向前推算(Forward pass):
对于双向循环神经网络(BRNN)的隐含层,向前推算跟单向的循环神经网络(RNN)一样,除了输入序列对于两个隐含层是相反方向的,输出层直到两个隐含层处理完所有的全部输入序列才更新
向后推算(Backward pass):
双向循环神经网络(BRNN)的向后推算与标准的循环神经网络(RNN)通过时间反向传播相似,除了所有的输出层δ项首先被计算,然后返回给两个不同方向的隐含层
BILSTM在tensorflow中对应的函数是
def bidirectional_dynamic_rnn(
cell_fw, # 前向RNN
cell_bw, # 后向RNN
inputs, # 输入
sequence_length=None,# 输入序列的实际长度(可选,默认为输入序列的最大长度)
initial_state_fw=None, # 前向的初始化状态(可选)
initial_state_bw=None, # 后向的初始化状态(可选)
dtype=None, # 初始化和输出的数据类型(可选)
parallel_iterations=None,
swap_memory=False,
time_major=False,
# 决定了输入输出tensor的格式:如果为true, 向量的形状必须为 `[max_time, batch_size, depth]`.
# 如果为false, tensor的形状必须为`[batch_size, max_time, depth]`. 默认为false
scope=None
)
outputs为(output_fw, output_bw),是一个包含前向cell输出tensor和后向cell输出tensor组成的二元组。
假设 time_major=false, 而且tensor的shape为[batch_size, max_time, depth]。实验中使用tf.concat(outputs, 2)将其拼接。
output_states为(output_state_fw, output_state_bw),包含了前向和后向最后的隐藏状态的组成的二元组。
output_state_fw和output_state_bw的类型为LSTMStateTuple。
LSTMStateTuple由(c,h)组成,分别代表memory cell和hidden state。
import tensorflow as tf
#定义初始变量
class BILstm:
def __init__(self, step_nums, output_size, keep_prob,cellunit=20):
self.step_nums = step_nums#时间片
self.cellunit = cellunit#lstm隐层单元
self.keep_prob = keep_prob
self.W_out = tf.Variable(tf.random_normal([cellunit*2,1]),name='w_out')
self.B_out = tf.Variable(tf.random_normal([1]),name='B_out')
self.x_ = tf.placeholder(tf.float32,[None,step_nums,output_size])
self.y_ = tf.placeholder(tf.float32, [None,step_nums])
self.cost = tf.reduce_mean(tf.square(self.model() - self.y_)) # 损失方程,均方差
# self.cost = tf.nn.sigmoid_cross_entropy_with_logits(labels=self.y_,logits=self.model())
self.train_op = tf.train.AdamOptimizer().minimize(self.cost) # adam优化器
self.saver = tf.train.Saver()
def model(self):
with tf.variable_scope('bilstm'):
#定义双层lstm
lstm_forward_cell = tf.nn.rnn_cell.BasicLSTMCell(self.cellunit, forget_bias=1.0, state_is_tuple=True)
lstm_backward_cell = tf.nn.rnn_cell.BasicLSTMCell(self.cellunit, forget_bias=1.0, state_is_tuple=True)
#dropout
lstm_forward_cell = tf.nn.rnn_cell.DropoutWrapper(cell=lstm_forward_cell, input_keep_prob=1.0 ,
)
lstm_backward_cell = tf.nn.rnn_cell.DropoutWrapper(cell=lstm_backward_cell, input_keep_prob=1.0,
)
outputs,states = tf.nn.bidirectional_dynamic_rnn(lstm_forward_cell, lstm_backward_cell , self.x_ , dtype=tf.float32)
output = tf.reshape(outputs,[-1,self.cellunit*2])
out = tf.matmul(output, self.W_out) + self.B_out # 实现全连接层
out = tf.reshape(out,[-1,self.step_nums])
return out
def train(self, train_x, train_y): # 训练函数
with tf.Session() as sess: # 建立会话
tf.get_variable_scope().reuse_variables() # 设置变量共享
sess.run(tf.global_variables_initializer()) # 会话执行变量初始化
# 迭代次数
for i in range(2000):
_, mse = sess.run([self.train_op, self.cost], feed_dict={self.x_: train_x, self.y_: train_y})
if i % 100 == 0:
print(i, mse)
save_path = self.saver.save(sess, './model')
print('Model saved to {}'.format(save_path))
def test(self, test_x): # 取出模型对数据进行匹配
with tf.Session() as sess:
tf.get_variable_scope().reuse_variables() # 变量共享
self.saver.restore(sess, './model') # 存储模型
output = sess.run(self.model(), feed_dict={self.x_: test_x})
return output
if __name__ == '__main__':
predictor = BILstm(output_size=1, step_nums=4, cellunit=10, keep_prob=1.0)
train_x = [[[1], [2], [4], [5]],
[[5], [7], [7], [8]],
[[3], [4], [5], [7]]]
train_y = [[2, 5, 7, 4],
[7, 12, 15, 7],
[4, 8, 11, 5]]
predictor.train(train_x, train_y)
test_x = [[[1], [2], [3], [4]], # 模型训练结果为train[0] = label[1] train[1] = train[0]+ train[2]
[[4], [5], [6], [7]]]
actual_y = [[2, 4, 6, 3],
[5, 10, 12, 6]]
pred_y = predictor.test(test_x)
print("\nlets run some tests!\n")
for i, x in enumerate(test_x):
print('when the inputs is {}'.format(x))
print('the ground truth output should be {}'.format(actual_y[i]))
print('and the model thinks it is {}\n'.format(pred_y[i]))
