pandas读取函数
pandas内置10多种数据源读取函数,常见的csv和excel
直接读取返回的就是数据框
可以保存为csv和exel格式
读取csv注意编码,常用编码utf-8和gbk2312
使用DataFrame的函数(下面对象简写为df)
df.head(),参数为整数,查看表格前几行
df.tail(),查看表格末尾几行
df.dtypes,返回每一列的数据类型
但是在读取文件规定某一列的数据类型时,属性是dtype,没有s,如下面例子
df.read_csv()读取文件函数中的参数含义
该函数默认的将数据第一行作为表头
1.encoding=’’
文件编码方式:常用utf-8,gbk(中文)
2.dtype = {‘列名’= 数据类型 ,}
规定某一列数据的读取类型。int64,object,str…
3.nrows=
单个数值,读取前几行,
4.sep=’, ’
读取文件的分割符设置,默认为逗号,平常不改
5.na_values =
缺失值,将和这个值相等的数值内容删除,这个值必须是数值,不是字符串
6.header=
将第几行作为表头,自动默认为0
a=pd.read_csv(r'read_csv.csv',encoding='gbk')
print(a);print('a读取后的dtype数据为---');
print(a.dtypes);print('b读取后的dtype数据为---')
b=pd.read_csv(r'read_csv.csv',encoding='gbk',\
dtype={'年龄':object})
print(b.dtypes);print('c读取后的nrow数据为----')
c=pd.read_csv(r'read_csv.csv',encoding='gbk',\
dtype={'年龄':object},nrows=2)
print(c);print('d读取后的na_values数据为----')
d=pd.read_csv(r'read_csv.csv',encoding='gbk',\
na_values=5)
print(d)
f=pd.read_csv(r'read_csv.csv',encoding='gbk',header=1)
print('添加了header的f====');print(f)
'''
姓名 年龄 性别
0 小五 5 男
1 李四 6 男
2 小红 4 女
a读取后的dtype数据为---
姓名 object
年龄 int64
性别 object
dtype: object
b读取后的dtype数据为---
姓名 object
年龄 object
性别 object
dtype: object
c读取后的nrow数据为----
姓名 年龄 性别
0 小五 5 男
1 李四 6 男
d读取后的na_values数据为----
姓名 年龄 性别
0 小五 NaN 男
1 李四 6.0 男
2 小红 4.0 女
'''
df.read_excel()
和read_csv()基本相同,多了一个sheet_name=’ ',用于说明读取那个工作页
sheet_name的参数可以时自己命名的表名,也可以是索引的整数值
f=pd.read_excel(r'read_excel.xlsx',encoding='gbk')
print('添加了的f====');print(f)
e=pd.read_excel(r'read_excel.xlsx',sheet_name='Sheet2',encoding='gbk')
print(e)
'''
添加了的f====
姓名 年龄 性别 #默认读取了第一个
0 小五 5 男
1 李四 6 男
2 小红 4 女
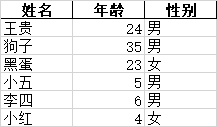
姓名 年龄 性别 #Sheet2中内容
0 王贵 24 男
1 狗子 35 男
2 黑蛋 23 女
'''
pandas保存数据
to_csv()和to_excel()
常用参数
index=
False:表示不保存索引号(平常会这样使用);True:保存索引号
encoding = ’ ’
编码方式设置,有中文时,csv保存时使用**’GBK‘**
而表格的保存可以使用utf-8
f=pd.read_excel(r'read_excel.xlsx',encoding='gbk')
print('添加了的f====');print(f)
e=pd.read_excel(r'read_excel.xlsx',sheet_name='Sheet2',encoding='gbk')
print(e)
d=pd.concat([e,f],ignore_index=False,)
d.to_excel('my_csv.xlsx',encoding='utf-8',index=False)
'''
添加了的f====
姓名 年龄 性别
0 小五 5 男
1 李四 6 男
2 小红 4 女
姓名 年龄 性别
0 王贵 24 男
1 狗子 35 男
2 黑蛋 23 女
'''
 |
|
|---|---|
