网络骨架 backbone
物体检测算法流程:
- 利用卷积神经网络处理输入图像
- 生成特征图
- 利用算法完成区域生成和损失计算

卷积层
提取图像特征
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
- in_channels:输入特征图的通道数,一般处理RGB图像时为3
- out_channels:输出特征图的通道数
- kernel_size:卷积核的尺寸,常见的有1,3,5,7的正方形
- stride:卷积核计算滑动步长,一般为1,若大于1,则输出特征图的尺寸会变小
- padding:填充,常见的有零填充,边缘填充,默认为零填充
- dilation:空洞卷积,大于1可以在保证特征图尺寸的同时增大感受野,默认为1
- groups:可实现组卷积,达到降低计算量的目的
- bias:是否需要偏置,默认为True
激活函数层
与TensorFlow不一样的是PyTorch的激活函数层是独立于卷积层的
池化层
第一个参数是池化区域的大小,第二个参数表示步长
nn.MaxPool2d(2, stride=2)
nn.AvePool2d(2, stride=2)
Dropout层
参数过多,训练样本较少时容易出现过拟合现象:训练集预测准确率高,测试集低。
第一个参数是元素置零的概率p,第二个参数为是否原地操作
nn.Dropout(0.5, inplace=False)
Dropout有效缓解过拟合原理:
每个神经元以概率p保留,1-p的概率停止工作,每次前向传递的神经元都不同,使得不会过度依赖局部特征。测试时为了保证相同的期望值,每个参数都要乘上p,也可以在训练时将保留下来的神经元乘以1/p使得测试时不用改变权重。
BN层
便于训练收敛和调参,解决浅层参数前向传播会存在过度放大的问题
BN层实现过程
以batch为单位,对每个batch进行操作
- 白化操作,计算输入数据的均值方差,进行正太标准化
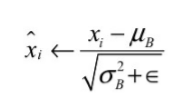
- 线性变换,引进两个可学习参数输出线性变换后的值
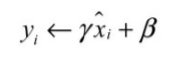
nn.BatchNorm2d(64)
使用时只需要传入一个参数,为特征的通道数
其他参数为默认值
白化中的伊普西隆默认为1e-05
momentum为均值方差的动量,默认为0.1
affine为是否添加可学习参数,默认为True
全连接层
nn.Linear(输入维度,输出维度)
感受野
感受野是指特征图上某一点可以看到的输入图像的区域
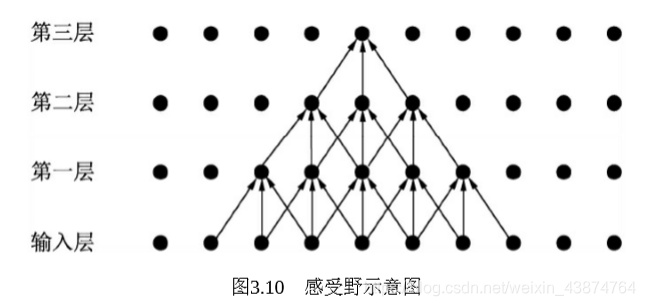
假设卷积核是33,则第一层的感受野为33,第二层的感受野为55,第三层的感受野为77.但是实际上边缘点的使用次数明显比中间点要少。
