前言
前段时间地统计的课设代码的确有点折磨人,但是还好算法过程比较简单,没有涉及到特别复杂的步骤,matlab在矩阵运算方面有大量的库函数以及其在索引方面的优势,使得我们真正能够实现向量化(矩阵化编程),希望大家看到这篇文章过后能够真正取思考,以前的哪些代码可以将for循环等若干繁琐步骤去掉,减少代码行数,掌握向量化编程的精髓。
1 变异函数
这里引用一下杨老师ppt上的一个简单定义,一维条件下,当空间点
在一维
轴上变化时,区域化变量
在点
和
处的值
与
差的方差一半定义为区域化变量Z(x)在x轴方向上的变异函数。
通常区域化变量
所描述的现象是二维和三维的,则变异函数可定义为在任一方向
,相距
的两个区域化变量值
与
的增量的方差。
其中
称为半变异函数,但有时为方便也称变异函数
变异函数计算公式
其中
为距离(滞后距)
为样点中符合该距离
的点对数量
和
为各点对位置
2随机样点的试验半方差
在很多情况下,样点并不是规则采集(机械采样)的,而是呈现不规则分布,这时,如何计算试验半方差?
一般地,在实际计算时,假设步长为
,当前滞后级别为
(
为正整数),则
,应该这样处理:
计算步骤
1.研究区所有点,找到点对
,其符合条件:
,它们之间的距离记为
2.计算
,记为
.
3.设找到
个这样的点对,计算平均距离
4.计算
为
滞后级别上的经验半方差值。
5.将各个级别的
,绘制在图上,形成经验半方差图
3代码实例
3.1数据集
本次数据来源于杨老师分享的沙洋县土壤样点数据集,如下图
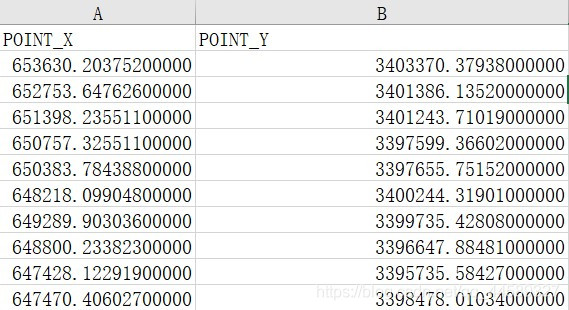
数据集前两列为
坐标,后面几列为属性数据
3.2 代码实例
这里以全氮数据为例计算经验半方差
由于数据为EXCEL形式,因此可调用xlsread函数读取文件将数据文件存储为矩阵,而将表中的文本类型忽略
数据预处理
data=xlsread('F:\geostatistical_test\test\data_and_materials\data.xls');
N=data(:,5);
[h,p,ks]=lillietest(N);%h==0,通过正态分布检验,p>0.05接受检验
figure;
histogram(N,10);
figure;
qqplot(N);
aveN=mean(N);
varN=var(N,1);%除以n的方差
stdN=sqrt(varN);
us=aveN+2*stdN;
ux=aveN-2*stdN;
logi=(N>us)+(N<ux);
logi=logical(logi);
N(logi)=[];
data(logi,:)=[];
[h1,p1,ks1]=lillietest(N);%h==0,通过正态分布检验,p>0.05接受检验
figure;
qqplot(N);
原始数据
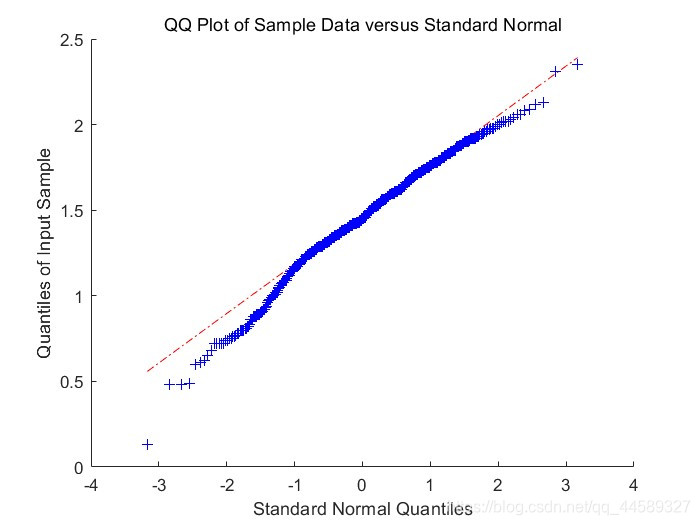
去除异常值后
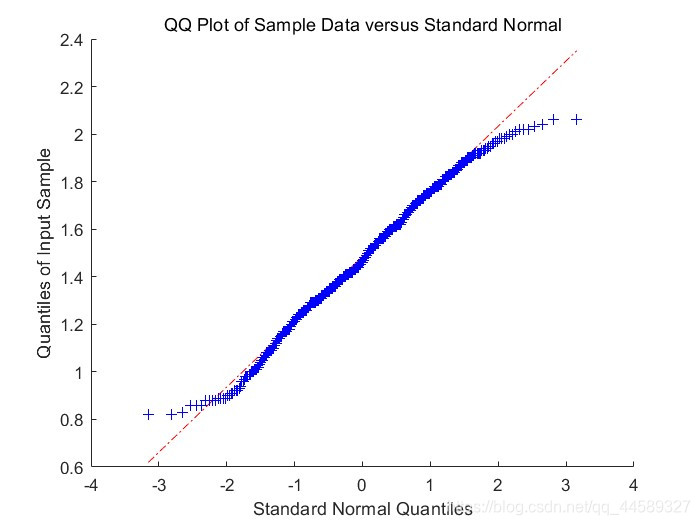
%计算出距离矩阵
D=pdist(data(:,1:2));
D1=squareform(D);%计算出距离矩阵
lag=500;
maxdist=max(max(D1));%计算最大距离
D2=triu(D1);%将距离矩阵转化成上三角,下三角为0,方便后面符合序号对提取
%下三角部分全部变为0
max_lagcount=round(maxdist/(2*lag))+1;%计算出最多可以求得的延迟阶数
将处理好的数据计算各个点对所对应的距离矩阵,其中D1就是一个
的距离矩阵,在对角线上为0;以500米为步长,找到最大距离(这里用max(max(D1)))是因为max函数是默认对矩阵每一列求最大值,通过计算可以得到最大能计算的步长max_lagcount
开始进行for循环计算组合的点对
循环代码如下:
result=[];%产生一个空矩阵,存储结果点对
for n=1:max_lagcount
lower=(n-1)*lag;
upper=n*lag;
logi=logical((D2>lower)+(D2<=upper)-1);%找到符合条件的点对逻辑矩阵
[tag1,tag2]=find(logi);%[tag1,tag2]表示点对序号
N1=N(tag1);
N2=N(tag2);
S=sum((N1-N2).^2);
Nh=length(tag1);
rh=S/(2*Nh);
havg=sum(D1((tag2-1).*size(D2,1)+tag1))/Nh;
%havg=trace(D1(tag1,tag2))/Nh;
temp=[havg,rh];
result=[result;temp];
end
其中lower,upper分别为距离限制条件,
其中logi=logical((D2>lower)+(D2<=upper)-1);%找到符合条件的点对逻辑矩阵,用的是D2上三角矩阵,若用原始距离矩阵(是对称矩阵),会将点对所有点对重复记录一次,因此选取上三角部分就可记录一次,因为下三角全为0
这里的tag1,tag2均为一列矩阵,其中
就表示着对应的点对序号,因此可以直接通过序号来对N矩阵索引,求得
,其中每个值就对应的是
,然后后续调用sum函数求和,其中Nh=length(tag1),找到目标点对得数量,只需要调用length求矩阵长度得函数即可,因此求得
对应于rh
havg=sum(D1((tag2-1).*size(D2,1)+tag1))/Nh;这里为什么用
D1((tag2-1).*size(D2,1)+tag1)这么复杂的索引方式对D1距离矩阵进行索引呢,因为前面的
表示的是D1中第
行第
列的数据,但是如果用D1(tag1,tag2))索引方式的话会将其中每个元素来进行匹配,因此我们要将点对表示的索引转化为一个值即序号索引,因为matlab里面默认情况下是先对第一列索引完后再对第二列索引,
因此第一列第
行对应于序号为
,
第二列第
行对应于
因此第
行第
列对应于序号
讲的比较通俗一点就是
为矩阵
的行数,这里举一个简单的例子说明

如果硬要用D1(tag1,tag2)索引的方式也是可行的,
,其中D1(tag1,tag2),其中tag1,tag2是目标点对序号得矩阵,但是matlab里面两个索引均为矢量时,会将矢量中每个元素都进行匹配来进行索引,进而返回索引得到得值,这里举一个简单例子说明:
a=[1,2,3;4,5,6;7,8,9]
a([1;2],[2;3])
返回结果分别为

但是我们只想要(1,2),(2,3)(第一行第二列,第二行第三列)处的值,发现其对应的值均会在对角线上,因此对角线上就是序号一一对应处的矩阵索引值,因此这里将调用矩阵的迹trace函数,即对角线元素之和,将这些点对对应的距离相加,最后得到
。
现在问题来了,哪种索引方式更快消耗的内存更小,因此我在代码快的前后加上了计时函数tic,toc根据最终的运行效果对比,基于
havg=sum(D1((tag2-1).*size(D2,1)+tag1))/Nh
索引方式所消耗计算时间为
1.1038s
基于trace点对索引的方式消耗计算时间为
2.9563s
最后将这些点对进行记录
temp=[havg,rh];result=[result;temp];
最终会返回一个两列的result矩阵,第一列为
,第二列为
在这里并没有考虑
的情况,假设N(h)=0,那么对应的
,
,因此
,
均为0/0,在matlab里面计算得到的结果为NaN
结果为空
因此我们只需将最终得到的矩阵中将其中为NaN的一行去掉即可
调用isnan函数,
result(isnan(result))=[];
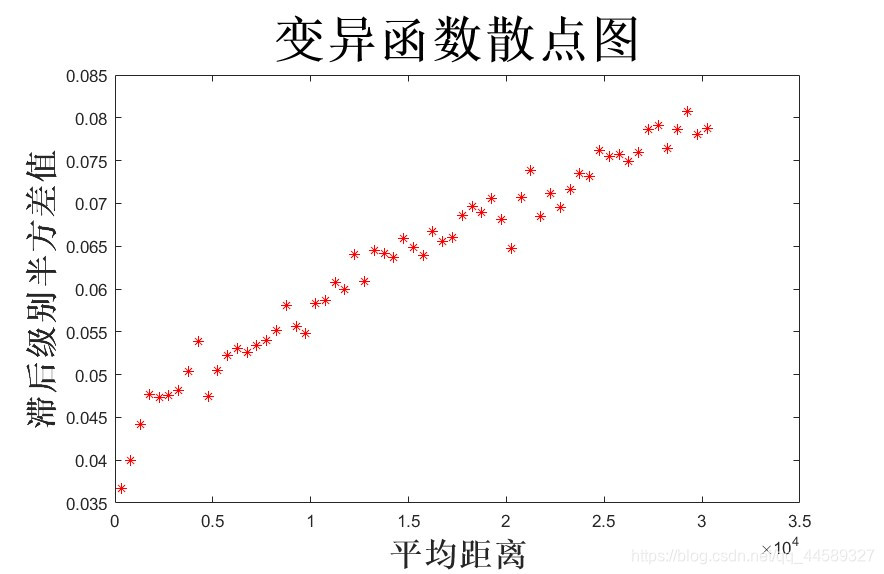
绘图表示:
plot(result(:,1),result(:,2),’*r’)
title(‘变异函数散点图’);
xlabel(‘平均距离’);
ylabel(‘滞后级别半方差值’);
完整代码如下:
tic;
data=xlsread('F:\geostatistical_test\test\data_and_materials\data.xls');
N=data(:,5);
[h,p,ks]=lillietest(N);%h==0,通过正态分布检验,p>0.05接受检验
figure;
histogram(N,10);
figure;
qqplot(N);
aveN=mean(N);
varN=var(N,1);%除以n的方差
stdN=sqrt(varN);
us=aveN+2*stdN;
ux=aveN-2*stdN;
logi=(N>us)+(N<ux);
logi=logical(logi);
N(logi)=[];
data(logi,:)=[];
[h1,p1,ks1]=lillietest(N);%h==0,通过正态分布检验,p>0.05接受检验
figure;
qqplot(N);
%计算出距离矩阵
D=pdist(data(:,1:2));
D1=squareform(D);%计算出距离矩阵
lag=500;
maxdist=max(max(D1));%计算最大距离
D2=triu(D1);%将距离矩阵转化成上三角,下三角为0,方便后面符合序号对提取
%下三角部分全部变为0
max_lagcount=round(maxdist/(2*lag))+1;%计算出最多可以求得的延迟阶数
result=[];
for n=1:max_lagcount
lower=(n-1)*lag;
upper=n*lag;
logi=logical((D2>lower)+(D2<=upper)-1);%找到符合条件的点对逻辑
[tag1,tag2]=find(logi);%[tag1,tag2]表示点对序号
N1=N(tag1);
N2=N(tag2);
S=sum((N1-N2).^2);
Nh=length(tag1);
rh=S/(2*Nh);
%havg=trace(D1(tag1,tag2))/Nh;
havg=sum(D1((tag2-1).*size(D2,1)+tag1))/Nh;
temp=[havg,rh];
result=[result;temp];
end
result(isnan(result))=[];
figure;
plot(result(:,1),result(:,2),'*r')
title('变异函数散点图');
xlabel('平均距离');
ylabel('滞后级别半方差值');
t1=toc
4总结
matlab的向量化编程是非常方便的,因为matlab针对矩阵索引支持逻辑索引以及位置索引,在筛出异常值与对特定条件的值进行索引时是非常有效的,其次调用matlab的内置函数一般计算速度要比自己写for循环的最终代码要快得多,如果不相信的话,同学们可以把矩阵化编程的那些语句以及函数改写成for循环试一试比较最终的计算时间,希望大家在今后矩阵运算的编程过程中尽量少用for循环,尽量理解如下代码的含义,方便今后套用:
logi=(N>us)+(N<ux);
logi=logical(logi);
N(logi)=[];
data(logi,:)=[];
logi=logical((D2>lower)+(D2<=upper)-1);%找到符合条件的点对逻辑
[tag1,tag2]=find(logi);%[tag1,tag2]表示点对序号
havg=trace(D1(tag1,tag2))/Nh;
havg=sum(D1((tag2-1).*size(D2,1)+tag1))/Nh;
本次代码全为潘老师自主编写,若要引用,注意引用规范
撰写本次博客也掌握了对markdown编写数学公式的技巧,也是对自己一个方面的提升,在地统计实验课程结束后会将遗传算法以及克里格插值部分的源代码分享出来造福大家!敬请期待!
