什么是Scrapy
简介
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改,它也提供了多种类型爬虫的基类。
Scrapy 架构
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,去重,入队,当引擎需要时,交还给引擎。
- Downloader(下载器): 负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
- Spider(爬虫): 它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Item Pipeline(管道): 它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件): 一个可以自定义扩展下载功能的组件。
- Spider Middlewares(爬虫中间件): 一个可以自定扩展和操作引擎和Spider中间通信的功能组件。

这里有个大佬写的趣味小故事,帮助理解
1.引擎:Hi!Spider, 你要处理哪一个网站?
2.Spider:老大要我处理xxxx.com。 (老大就是我们吖)
3.引擎:你把第一个需要处理的URL给我吧。
4.Spider:给你,第一个URL是xxxxxxx.com。
5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6.调度器:好的,正在处理你等一下。
7.引擎:Hi!调度器,把你处理好的request请求给我。
8.调度器:给你,这是我处理好的request
9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14.管道“调度器:好的,现在就做
使用Scrapy
首先要安装
windows 上面就 Scrapy pip install Scrapy 以防万一再安装一个 pip install pupiwin32 否则有的电脑运行会报错,如果没有报错就没有必要安装 了
Linux 可以参考 Scrapy 官网 或者 Scrapy中文文档 安装
打开cmd 输入 scrapy 出现下图就是安装好了,有兴趣 的可以试试 Scrapy 的命令。

下面开始使用吧
我们要创建一个项目,还记的刚才那个图里的 startproject 命令吗
首先找一个喜欢的位置打开开cmd,在cmd中运行 scrapy startproject [项目名称]比如我这里是 scrapy startproject ITcast (因为一会实例是 ITcast 就用这个做名字了
运行完后,会在 刚才你喜欢的位置 里创建用项目名称命名的一个文件夹,里面有一个scrapy 配置文件scrapy.cfg ,还有一个用项目名称命名的文夹
我们看看整体结构,看图图

- items.py 存储爬取数据的模型
- middlewares.py 中间键
- pipelines.py 处理爬取的数据
- settings.py 配置爬虫,是不是延迟,cookie,请求等
- spiders 放我们的爬虫文件
下面 我们就来使用一下Scrapy 吧
爬取 ITcast
这个就是我们爬取的网站ITcas
首先在 spiders 文件夹里创建好我们的爬虫文件,当然不是我们手动创建
进入spiders 这个文件夹,执行scrapy genspider [爬虫名字] "域名" 这就创建了我们的爬虫。
例如:我这里
D:\ITcast\ITcast>cd spiders
D:\ITcast\ITcast\spiders>scrapy genspider itcast “itcast.cn”
域名表示的是以后爬取的数据都是 itcast 这个主机下面的页面,如果又其他的就不管,就是域名的范围
注意,爬虫的名字不能和项目的名字相同
执行完后spiders 里就会有对应的 .py 文件
打开它我们会看到和下面这个图差不多的东东,我加了注释。这是自动生成的类

在开始写爬虫之前,我们还需要修改一下爬虫的配置文件 setting.py 找到图中的两个地方进行修改


这里 robot协议 我们是不去遵守的,如果遵守可能许多数据都爬取不到,所以我们改为False
请求头部我们之前的接触过,这里我们取消注释,添加 User-Agent 字段来伪装自己
我用的是这个,不同的浏览器不一样
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
好了,下面我们就可以写爬虫了,
我们把要爬取的地址 放在 start_urls 那个列表里,在解析的部分先改动一下,打印 response 看看

在现在的项目 目录下 再次 执行 Scrapy 我们看到了和第一次执行 Scrapy不同的命令,

所以我们执行这个crawl命令 来运行我们的爬虫 格式是scrapy crawl [爬虫名字] 例如:这里爬虫叫 itcast 所以我们执行 scrapy crawl itcast 注意是爬虫名字,不是 itcost.py

我们发现,我们什么都没有写,就已经得到了这个页面,所以接下来我们要做的就是解析这个页面
Scrapy 里 xpath 还是蛮好用的,所以这里我就用xpath 解析了,在之前的入门博文里已经 讲解过xpath 的使用,如果之前没有看过我博客的小伙伴或者忘了的朋友可以戳 爬虫入门之xapth 来回忆一下,这里就不多说了。直接看图:
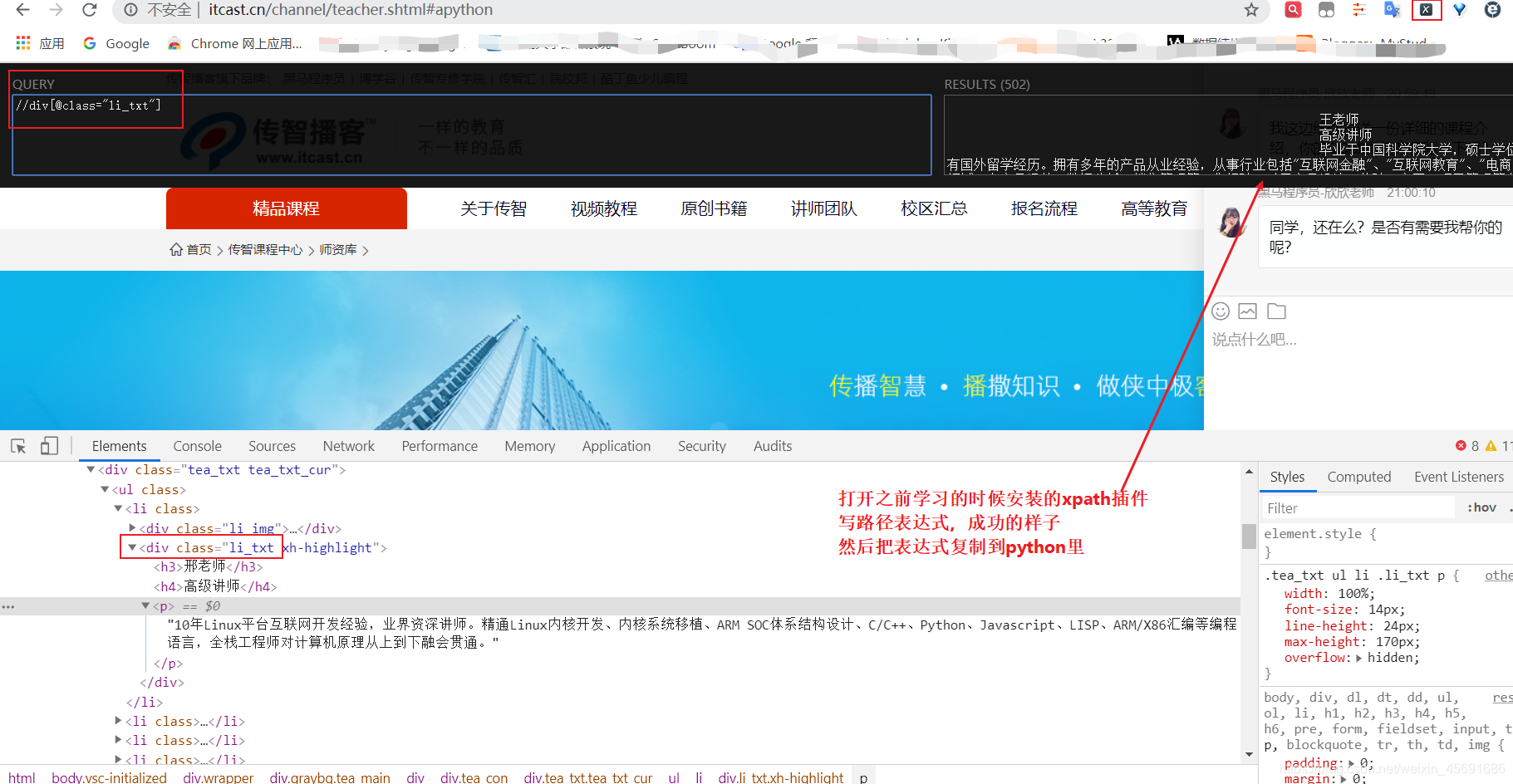 我们分别解析每个老师的信息,然后存入字典中,并把所有老师的信息放在列表里,最后写入csv中。
我们分别解析每个老师的信息,然后存入字典中,并把所有老师的信息放在列表里,最后写入csv中。
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn'] # 这个里面没有http这些东西,直接写后面的主机
# 爬虫的第一个请求就是这里面的
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#apython']
def parse(self, response): # 这个是解析的部分,默认执行这个解析
# 保存老师信息的列表
Items = []
teacherlist = response.xpath("//div[@class='li_txt']")
# 用xpath 解析到 每个老师的div 再遍历解析 得到每个老师的具体信息
for t in teacherlist:
item = {}
# extract 返回的是一个unicode 字符串,如果不用这个方法,返回的还是一个xpath类,里面有个data是数据.
name = t.xpath("./h3/text()").extract()
title = t.xpath("./h4/text()").extract()
info = t.xpath("./p/text()").extract()
# 放入字典中
item["name"] = name
item["title"] = title
item["info"] = info
# 放入列表
Items.append(item)
print("1111111111111111111111111111111111111111111111111111111111111111111111111111111") # 为了方便看打印个分隔线 哈哈哈哈
#print(Items) # 打印出来看看
return Items
在这个爬虫里return后,就相当于返回给了引擎,然后引擎会给下载器
所以下一步我们只需要在项目位置打开cmd 执行 scrapy crawl itcast -o teacher.csv 就可以保存在 csv文件中。
打开看看

如果出现了乱码,那是因为windows 默认的是gbk 编码,我们只要打开之前的setting.py 来设置一下写入的编码,把这句话加在setting文件中 FEED_EXPORT_ENCODING = 'gb18030' 再次运行就好了。
当然这只是其中的一种简单,粗糙的方法,会看到表格也不整齐,所以下次我们还会继续学习有关Scrapy 的内容
我又来要赞了,还是希望各位路过的朋友,如果觉得可以学到些什么的话,点个赞再走吧,欢迎各位路过的大佬评论,指正错误,也欢迎有问题的小伙伴评论留言,私信。每个小伙伴的关注都是我更博的动力》》》》奥里给
