Chapter08 | 使用Python库抽取
一、基础知识点
1、Xpath
- XML路径语言(XML Path Language,XPath)是一种用来确定XML文档中某部分位置的语言
- 基于XML的树形结构,提供在数据结构树中找寻节点的能力
- Xpath可以用来标记XML和HTML语言的某一部分
xml格式示例:


与正则表达式相同,Xpath拥有自己的语法规则


在Xpath语言中,XML/HTML文档被称为节点数
- HTML语言的标签可以看作树的节点

Xpath表达式可以用来检索标签内容:
获取标签的所有class属性: //div/@class
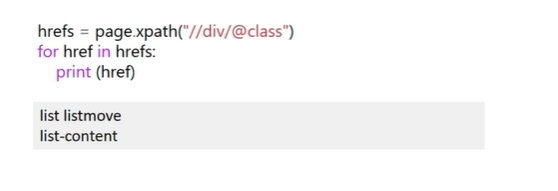
2、DOM树
- 基于DOM,会载入整个HTML文档,并解析整个DOM树
- HTML是分层的,由标签、属性、数据组成,这些元素整体构成一颗DOM树,如下图:

- DOM树中每个节点都是一个元素,一个元素可以有自己的属性,也可以包含若干个子元素
二、信息抽取
基于Xpath和Dom树两个基础知识,可以使用python库进行针对性的信息抽取 Python语言中处理XML和HTML的第三方库:
- Lxml
- Beautifulsoup4
1、lxml
lxml是Python语言中处理XML和HTML的第三方库
- 底层封装C语言编写的libxml2和libxslt包
- 提供简单有效的Python API
- 官方文档:https://lxml.de/
从网络爬虫的角度来看,我们关注的是lxml的文本解析功能
在iPython环境中,使用lxml:from lxml import etree

根据目标文本的类型,lxml提供不同的函数来去解析:
- fromstring():解析字符串
- HTML():解析HTML类型对象
- XML():解析XML类型对象
- parse():解析文件类型对象
1.1、使用HTML()函数进行文本读取
from lxml import etree
data = """
<!DOCTYPE html>
<html>
<head>
<meta charset = "UTF-8">
<meta http-equiv="X-UA-Compatible"content="IE = edge">
...
<script src = "/static/js/pageJs/courses-list.js"></script>
</body>
</html>
"""
page = etree.HTML(data.encode("utf-8"))
- lxml中使用Xpath来去匹配内容
- Xpath的功能与正则表达式类似
- Xpath是一种查看XML文档内容的路径语言,定位文档中的节点位置
获取网页标题中a标签的内容:
//div//li//a/text()
hrefs = page.xpath("//div//li//a/text()")
print()
for href in hrefs:
print(href)
1、获取网页中的所有链接(绝对链接和相对链接)
以百度百科为例:
import requests
from lxml import etree
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB').content.decode("utf-8")
html = etree.HTML(page)
hrefs = html.xpath("//a/@href")
for href in hrefs:
print(href)

上面取出了百度百科中的所有链接。
得出的链接包括绝对链接和相对链接。
2、获取网页内部所指向的链接
import requests
from lxml import etree
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB').content.decode("utf-8")
html = etree.HTML(page)
hrefs = html.xpath("//div[@class=\"para\"]/a/@href")
for href in hrefs:
print(href)

3、获取网页内的文字
import requests
from lxml import etree
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB').content.decode("utf-8")
html = etree.HTML(page)
hrefs = html.xpath("//div[@class=\"para\"]/text()")
for href in hrefs:
print(href)

2、BeautifulSoup
BeautifulSoup是Python语言中另一种解析XML/HTML的第三方解析库:
- 处理不规范标记并生成分析树(parse tree)
- 提供简单常用的导航,搜索以及修改分析树的操作功能
从网页中提取内容的方法:
正则表达式:
- 缺点:编写困难,难以调试,无法体现网页结构
BeautifulSoup:
- 优点:使用简单,调试方便,结构清晰
2.1、BeautifulSoup的好处
- 提供python式的函数用来处理导航、搜索、修改分析树等功能
- 自动将输入编码转换为Unicode,输出编码转换为utf-8
- 为用户提供不同的解析策略或强劲的速度
- 相比正则解析,降低学习成本
- 相比Xpath解析,节约时间成本
2.2、解析器
BeautifulSoup支持不同的解析器:
- HTMLParser:这是Python内置的HTML解析器,纯Python实现,效率较低
- lxml:用C语言实现的HTML和XML解析器,速度很快,容错能力强(强烈安利)
- html5lib:以浏览器的方式解析文档,生成HTML5格式的文档,容错性很好,但速度较慢
lxml作为bs4的一部分,是BeautifulSoup官方推荐的解析库
给BeautifulSoup的构造函数传递一个字符串或文件句柄,就可以解析HTML:

2.3、节点类型
BeautifulSoup将DOM树中每个节点都表示成一个对象
这些节点对象可以归纳为以下几种:
- Tag:HTML中的标签。一个Tag可以包含其他Tag或NavigableString
- NavigableString:BeautifulSoup用NavigableString类来包装Tag中的字符串,是一个特殊的节点,没有子节点
- Comment:NavigableString的子类,表示HTML文件中的注释
- BeautifulSoup:整个DOM树的类型
BeautifulSoup的关键是学习操作不同的节点对象
下面的代码展示不同的节点类型:

还是以百度百科为例:
1、获取类型
import requests
from bs4 import BeautifulSoup as bs
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB').content.decode("utf-8")
html = bs(page)
print(type(html))
print(type(html.html))
print(type(html.title.string))

2、获取网页
import requests
from bs4 import BeautifulSoup as bs
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB').content.decode("utf-8")
html = bs(page)
paras = html.find_all(class_="para")
for para in paras:
print(para)

3、获取网页相对链接
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB').content.decode("utf-8")
html = bs(page)
paras = html.find_all(class_="para")
for para in paras:
for a in para("a"):
if a.has_attr('href'):
print(a["href"])

2.4、标签定位
- 使用"soup."+标签名字定位标签的方法,只能选择第一个满足条件的节点
- Find_all()方法能返回所有满足条件的标签的列表
find_all(name,attrs,recursive,text,**kwargs)
标签定位的依据
- 按标签名称定位
- 按属性定位
- 按文本内容定位
- 用正则表达式和自定义函数定位
1、按标签名称定位
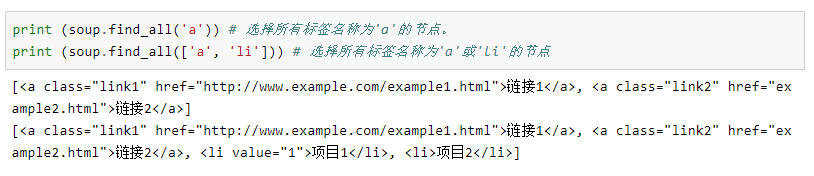
2、按属性定位

3、按文本内容定位
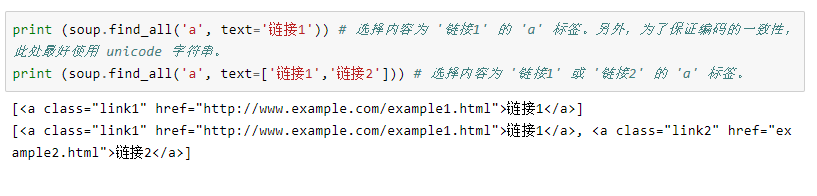
4、用正则表达式和自定义函数定位

2.5、数据提取
1、获取标签中的属性值

2、获取标签中的文本

eg:
import requests
from bs4 import BeautifulSoup as bs
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB').content.decode("utf-8")
html = bs(page)
paras = html.find_all(class_="para")
for para in paras:
print(para.text)

- 使用find(0函数来缩小匹配目标文本的范围,定位标签
- 使用find_all()函数来搜索div标签下所有li标签的内容
