scrapy架构、中间件、动态ip代理池
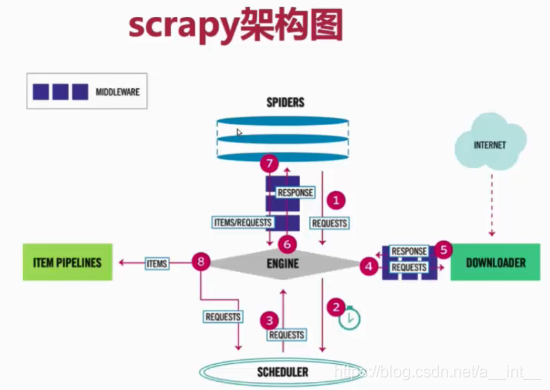
1、scrapy架构
2、中间件
中间件详解
https://www.cnblogs.com/fengf233/p/11453375.html
process_request

process_response

process_exception
process_exception(self, request, exception) 函数有两个参数,exception 是视图函数异常产生的 Exception 对象
process_exception 函数的执行顺序是按照 settings.py 中设置的中间件的顺序的倒序执行
process_exception 函数只在视图函数中出现异常的时候才执行,它返回的值可以是 None,也可以是一个 HttpResponse 对象
如果返回 None,则继续由下一个中间件的 process_exception 方法来处理异常
如果返回 HttpResponse,将调用中间件中的 process_response 方法
3、动态ip代理池
我们自己写一个中间件实现动态ip代理池,动态ip代理池可以让请求的网站无法捕捉我们固定的ip
3.1、先测试一下我们的代理能用不
关于代理ip不知道怎么开的可以参考这里:
https://blog.csdn.net/a__int__/article/details/104635535 标题3、代理服务器
这里我们在虚拟环境里面测试
虚拟环境没有安装requests的先安装:>pip install requests
虚拟环境没有安装ipython的先安装:>pip install ipython
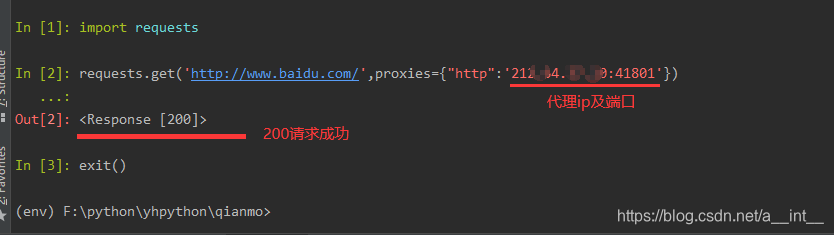
测试请求成功后开始一下操作
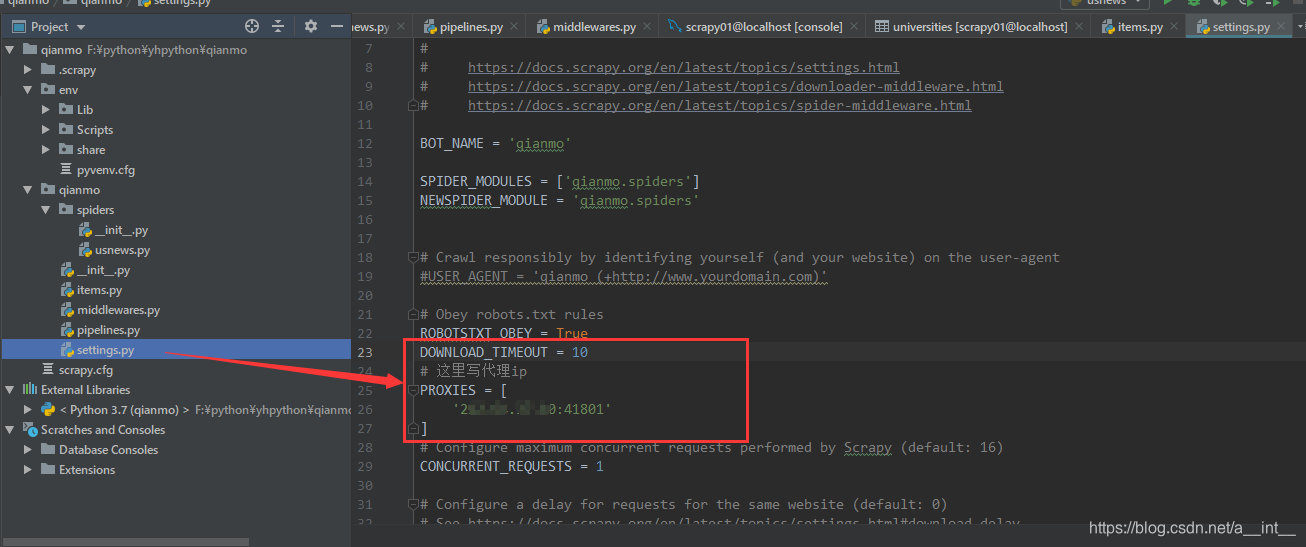
3.2、开始写代码
在setting里面写好我们自己的代理ip
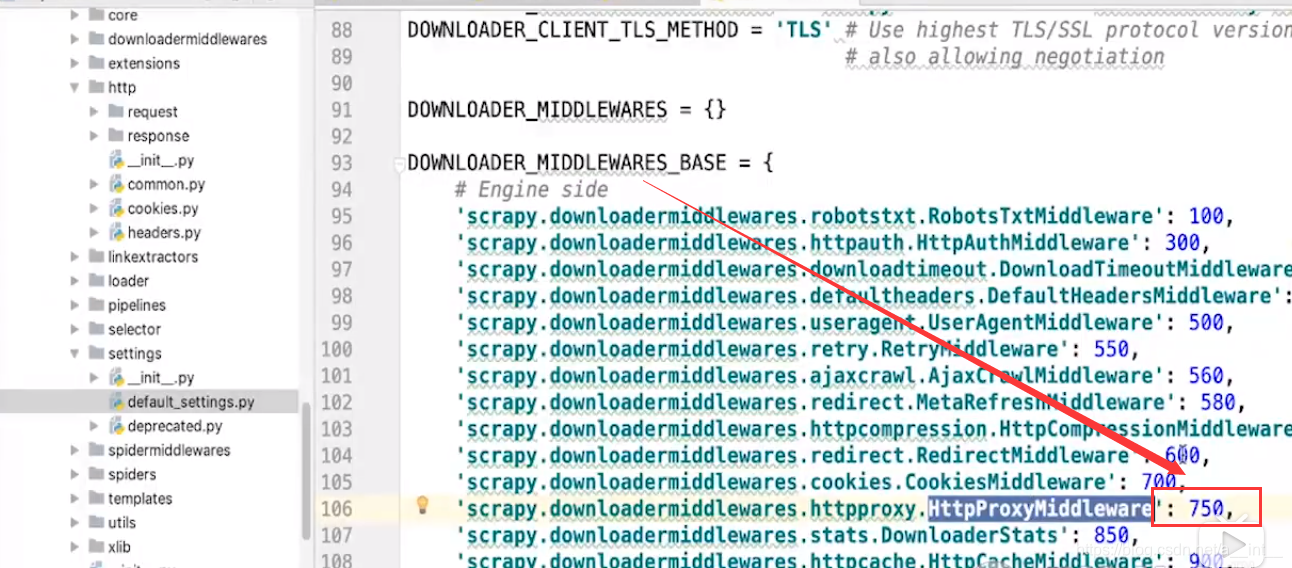
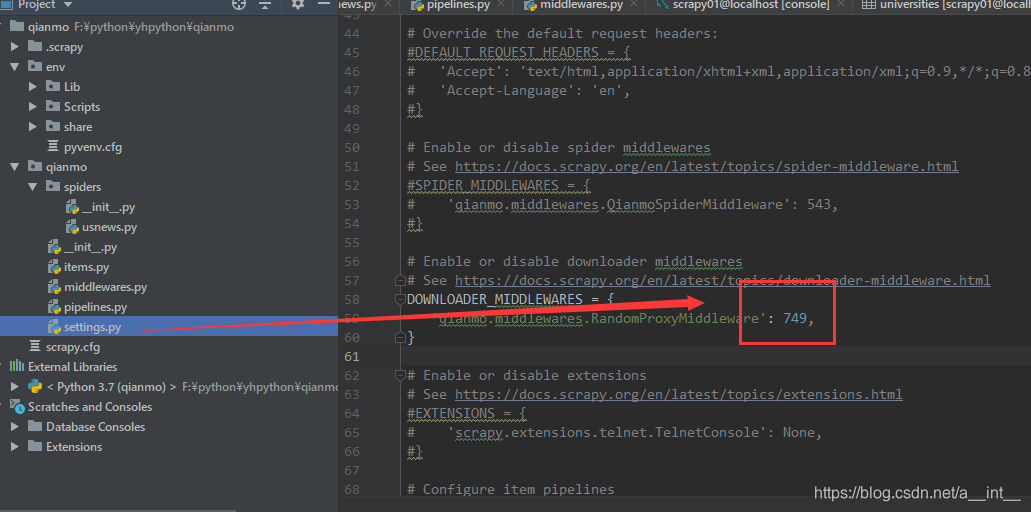
在setting里面找到DOWNLOADER_MIDDLEWARES,改成我们自己的
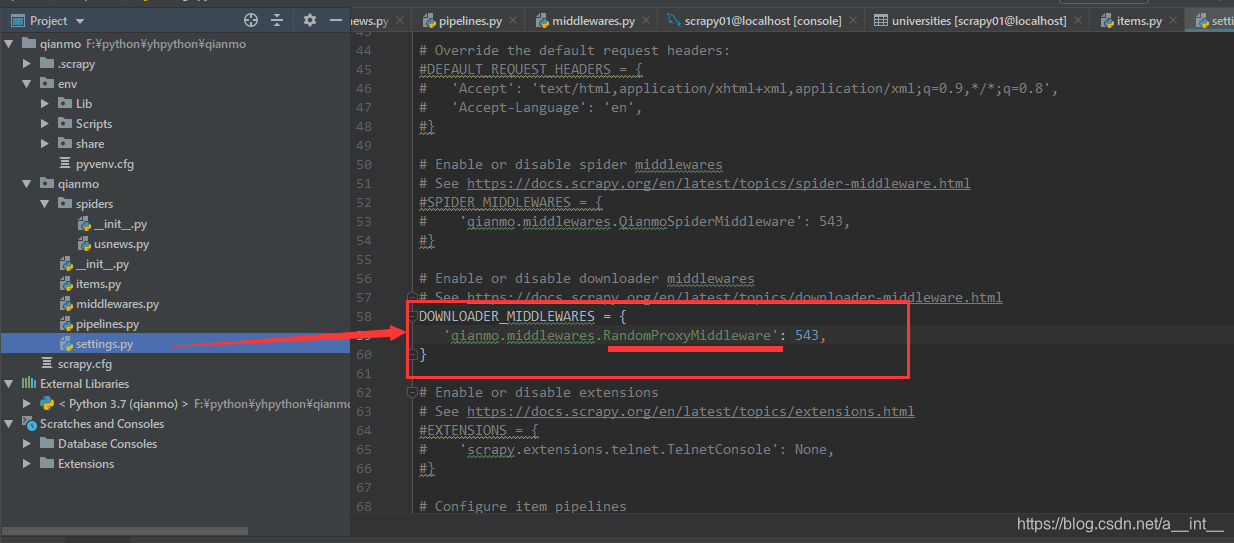
把优先级改到源码的Proxy之前
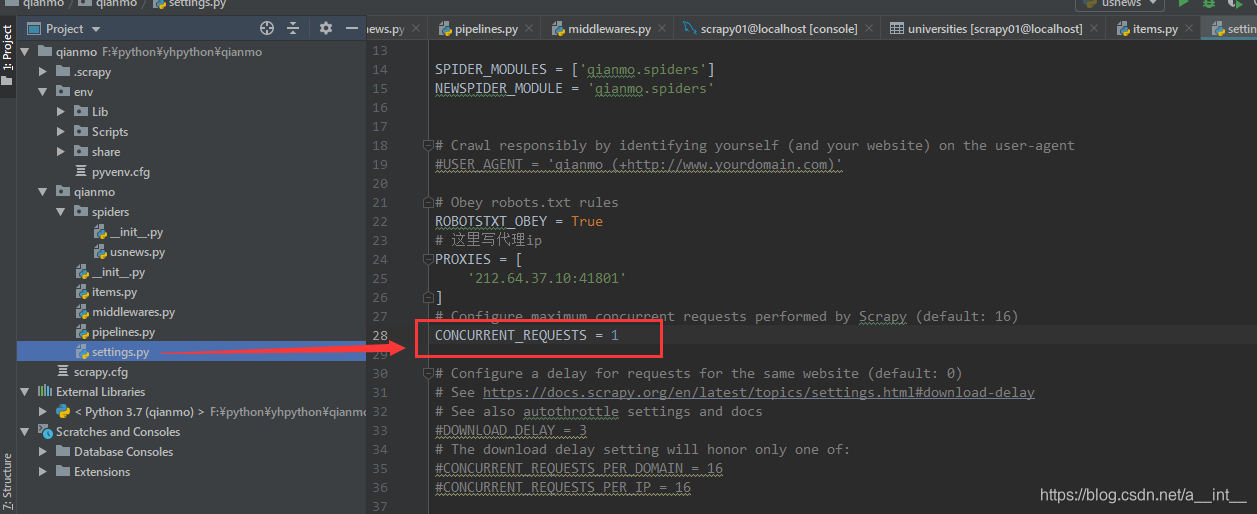
打开setting里面的并发,把数字改小一点
在Middlewares.py最后面添加代码
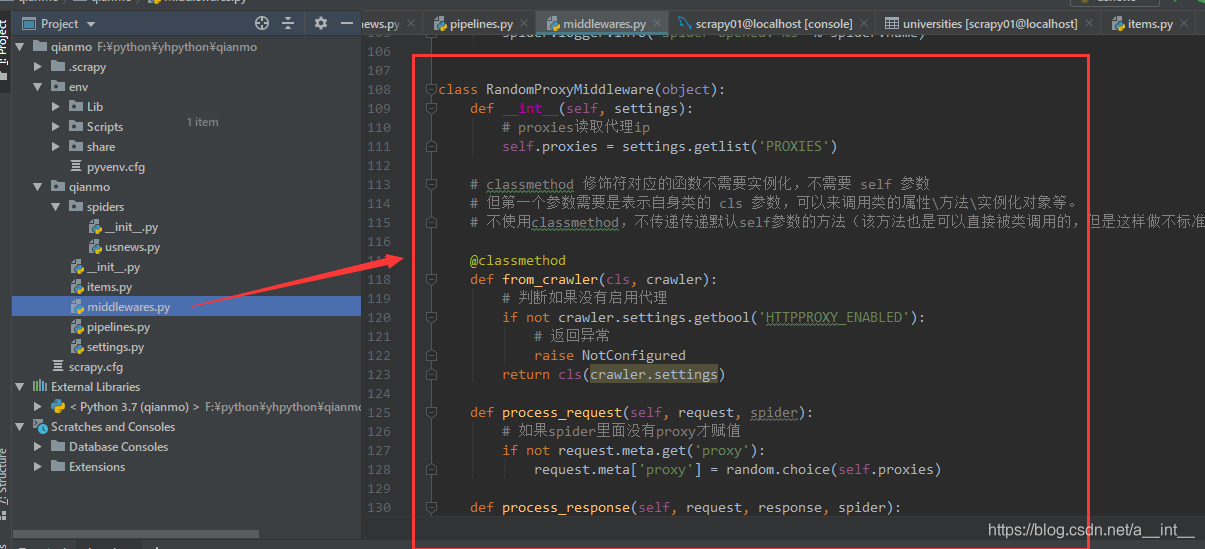
class RandomProxyMiddleware(object):
def __int__(self, settings):
# proxies读取代理ip
self.proxies = settings.getlist('PROXIES')
# classmethod 修饰符对应的函数不需要实例化,不需要 self 参数
# 但第一个参数需要是表示自身类的 cls 参数,可以来调用类的属性\方法\实例化对象等。
# 不使用classmethod,不传递传递默认self参数的方法(该方法也是可以直接被类调用的,但是这样做不标准)
@classmethod
def from_crawler(cls, crawler):
# 判断如果没有启用代理
if not crawler.settings.getbool('HTTPPROXY_ENABLED'):
# 返回异常
raise NotConfigured
return cls(crawler.settings)
def process_request(self, request, spider):
# 如果spider里面没有proxy才赋值
if not request.meta.get('proxy'):
request.meta['proxy'] = random.choice(self.proxies)
def process_response(self, request, response, spider):
pass
def process_exception(self, request, exception, spider):
pass
处理异常后的代码
class RandomProxyMiddleware(object):
def __int__(self, settings):
# 2、初始化配置及相关变量
# proxies读取代理ip
self.proxies = settings.getlist('PROXIES')
self.stats = defaultdict(int)
self.max_failed = 3
# classmethod 修饰符对应的函数不需要实例化,不需要 self 参数
# 但第一个参数需要是表示自身类的 cls 参数,可以来调用类的属性\方法\实例化对象等。
# 不使用classmethod,不传递传递默认self参数的方法(该方法也是可以直接被类调用的,但是这样做不标准)
@classmethod
def from_crawler(cls, crawler):
# 1、创建中间件对象
# 判断如果没有启用代理
if not crawler.settings.getbool('HTTPPROXY_ENABLED'):
# 返回异常
raise NotConfigured
return cls(crawler.settings)
def process_request(self, request, spider):
# 3、为每个reyuest对象分配一个随机IP代理
# 如果spider里面没有proxy才赋值
if not request.meta.get('proxy') and request.url not in spider.start_urls:
request.meta['proxy'] = random.choice(self.proxies)
def process_response(self, request, response, spider):
# 4、请求成功则调用
c = request.meta.get("proxy")
if response.status in (400, 401, 403):
self.stats[c] += 1
if self.stats[c] >= self.max_failed:
print("报错")
if c in self.proxies:
self.proxies.remove(c)
print("已从列表里删除%s" % c)
del request.meta["proxy"]
return request
return response
def process_exception(self, request, exception, spider):
# 4、请求失败则调用
c = request.meta.get("proxy")
from twisted.internet.error import ConnectionRefusedError, TimeoutError
if c and isinstance(exception, (ConnectionRefusedError, TimeoutError)):
print("执行代理%s发现错误:%s" % (c, exception))
if c in self.proxies:
self.proxies.remove(c)
print("已从列表里删除%s" % c)
del request.meta["proxy"]
return request
4、telnet
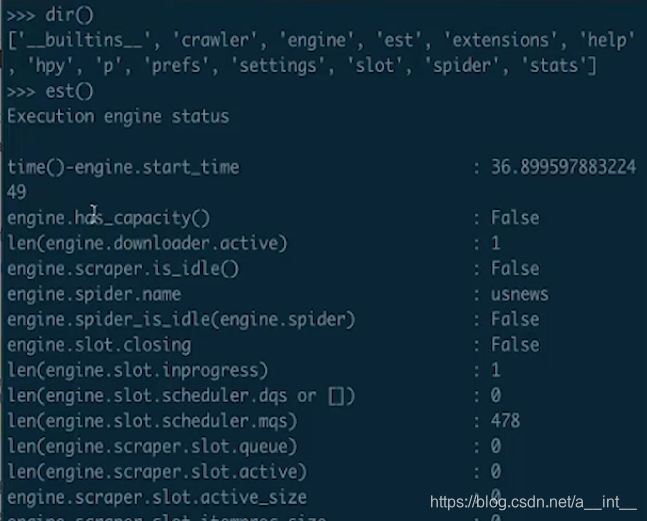
telnet可以查看爬虫当前状态
Telnet协议是TCP/IP协议家族中的一员,是Internet远程登陆服务的标准协议和主要方式。
windows环境下telnet服务是开启的
使用:telnet 地址 端口
我们先启动爬虫:找到scrapy生成的telnet 密码

爬虫不要关,用telnet访问

回车:账号是scrapy,密码是刚刚爬虫自动生成的

之后会自动进入到python的控制台,所有的python函数都能用
一般我们爬虫上线使用的时候都会把telnet关掉

