首先导入所需要的模块
import pandas as pd
from pandas import DataFrame,Series
import numpy as np
创建Series
obj_1=Series([1,2,3,4])
print(obj_1)
# Series数据 :索引在左,值在右
# 没有指定索引,Series数据会以0~len-1(len为数据的长度)作为索引
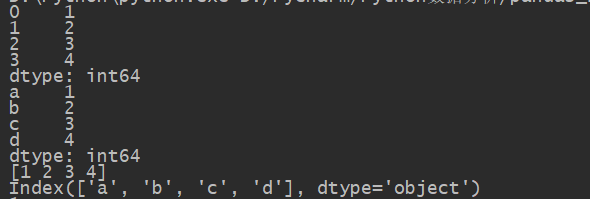
obj_2=Series([1,2,3,4],index=['a','b','c','d'])
print(obj_2)
# Series有values和index属性
print(obj_2.values)
print(obj_2.index)
Series的索引
print(obj_2['a'])
obj_2['a']=100
print(obj_2[['a','c']])

Series的运算
obj_3=Series([-1,78,-90,60],index=['a','b','c','r'])
print(obj_3**2)
print(np.abs(obj_3))
print(obj_3[obj_3>60])
# Series对象和索引都有name属性
obj_3.name='name'
obj_3.index.name='score'
print(obj_3)


创建DataFrame数据
datas={
'name':['刘邦','李渊','朱元璋','孙中山'],
'adress':['江苏','陕西','安徽','广东'],
'age':[56,40,30,45],
'year':[206,618,1368,1912]
}
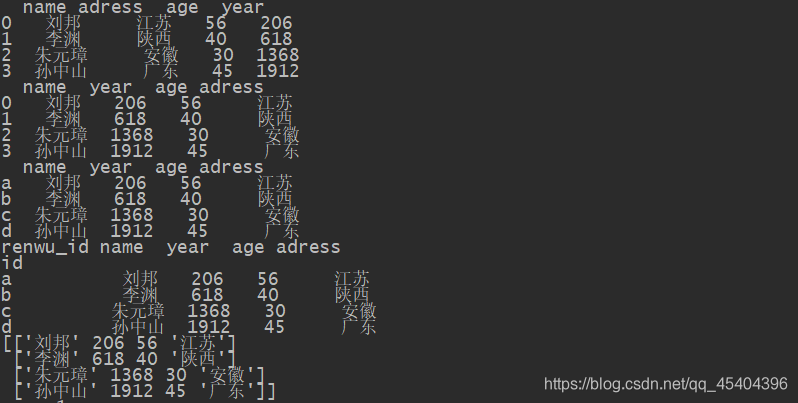
df_1=DataFrame(data=datas)
print(df_1)
# 可以通过columns指定列索引的排序顺序
df_2=DataFrame(data=datas,columns=['name','year','age','adress'])
print(df_2)
# 在没有指定索引的情况下,默认以0~len-1(len为数据的长度)作为索引
# 也可以指定索引
df_3=DataFrame(data=datas,columns=['name','year','age','adress'],index=['a','b','c','d'])
print(df_3)
#DataFrame的index和columns也有name属性
df_3.index.name='id'
df_3.columns.name='renwu_id'
print(df_3)
# 通过values属性可以将DataFrame数据转换为二维数组
print(df_3.values)
pandas索引操作
重新索引
# pandas索引操作
# 重新索引
# 所说的索引并不是给索引重新起名,而是重新进行排序,如果某个索引值不存在,会出现缺失值
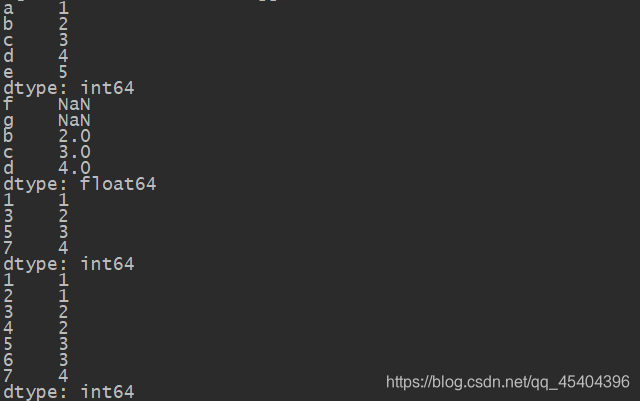
obj_4=Series([1,2,3,4,5],['a','b','c','d','e'])
print(obj_4)
obj_4=obj_4.reindex(['f','g','b','c','d'])
print(obj_4)
# 如果需要对缺失值进行填充,可以通过method参数来实现,参数值可以为ffill或pad
# 参数值为bfill或backfill时为向后填充
obj_5=Series([1,2,3,4],index=[1,3,5,7])
print(obj_5)
print(obj_5.reindex(range(1,8),method='ffill'))
print(obj_5.reindex(range(1,8),method='bfill'))
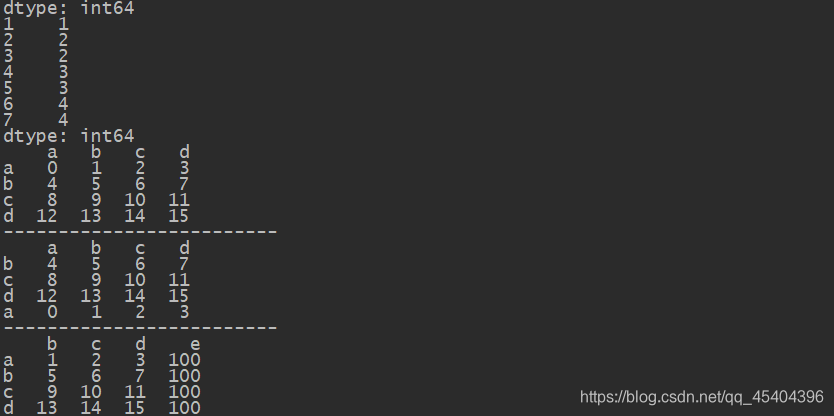
# 对于DataFrame数据来说
df_4=DataFrame(np.arange(16).reshape(4,4),index=['a','b','c','d'],columns=['a','b','c','d'])
print(df_4)
df_4_1=df_4.reindex(['b','c','d','a'])
df_4_2=df_4.reindex(columns=['b','c','d','e'],fill_value=100)
print('-'*25)
print(df_4_1)
print('-'*25)
print(df_4_2)
更换索引
datas={
'name':['刘邦','李渊','朱元璋','孙中山'],
'adress':['江苏','陕西','安徽','广东'],
'age':[56,40,30,45],
'year':[206,618,1368,1912]
}
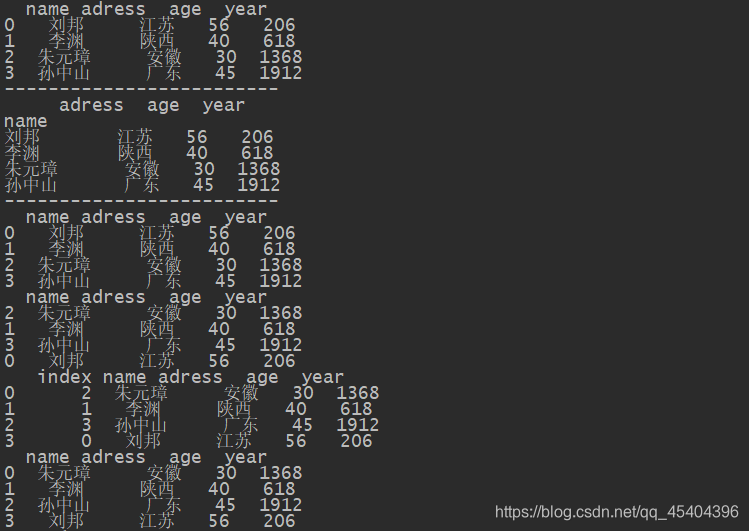
df_5=DataFrame(data=datas)
print(df_5)
print('-'*25)
df_5_1=df_5.set_index('name')
print(df_5_1)
print('-'*25)
df_5_2=df_5_1.reset_index()
print(df_5_2)
# 排序
df_5_3=df_5.sort_values(by='age')
print(df_5_3)
df_5_4=df_5_3.reset_index()
print(df_5_4)
# 原索引可以通过drop参数进行删除
df_5_5=df_5_3.reset_index(drop=True)
print(df_5_5)
索引和选取
obj_6=Series([1,2,3,4,5,6],index=['a','b','c','d','e','f'])
print(obj_6)
print(obj_6[0])
print(obj_6['a'])
print(obj_6[['c','a']])
# 切片操作与Python列表有所不同
print(obj_6[0:2])
print(obj_6['a':'c'])

选取列 、选取行
# 选取列
datas={
'name':['刘邦','李渊','朱元璋','孙中山'],
'adress':['江苏','陕西','安徽','广东'],
'age':[56,40,30,45],
'year':[206,618,1368,1912]
}
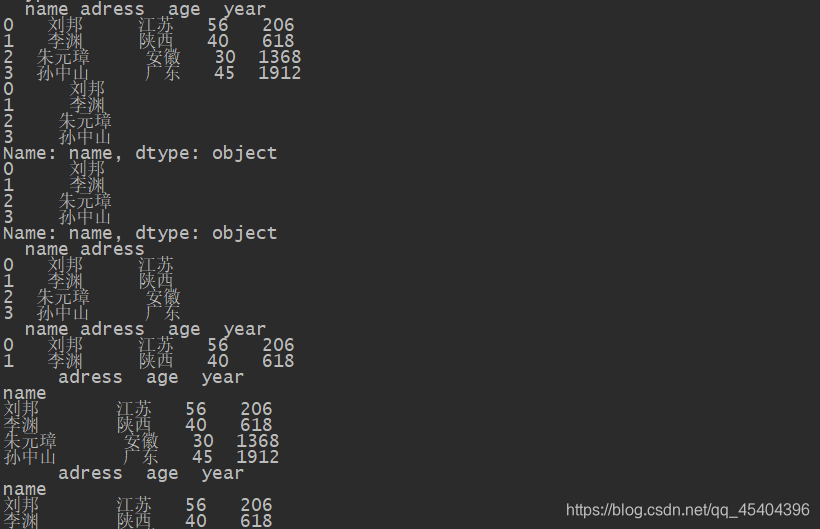
df_6=DataFrame(data=datas)
print(df_6)
print(df_6['name'])
print(df_6.name)
print(df_6[['name','adress']])
# 选取行
print(df_6[0:2])
df_6_1=df_6.set_index('name')
print(df_6_1)
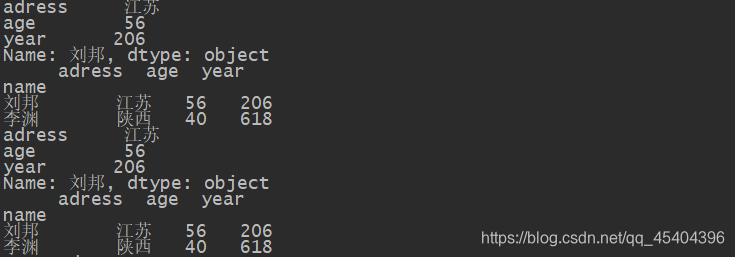
print(df_6_1['刘邦':'李渊'])
print(df_6_1.loc['刘邦'])
print(df_6_1.loc[['刘邦','李渊']])
print(df_6_1.iloc[0])
print(df_6_1.iloc[[0,1]])
布尔选择
df_7=DataFrame(data=datas)
df_7_1=df_7.set_index('name')
print(df_7_1)
print(df_7_1['year']==206)
print(df_7_1[df_7_1['year']==206])
print(df_7_1[(df_7_1['year']==206) |(df_7_1['adress']=='陕西')])
# '|' 或、'&'和、
增加
# 增加
new_data={
'name':'杨坚',
'adress':'陕西',
'age':50,
'year':581
}
df_7_1=df_7_1.reset_index()
df_7_2=df_7_1.append(new_data,ignore_index=True) # 忽略索引值
print(df_7_2)
# 增加一个新列
df_7_2['type']='historical_figures'
print(df_7_2)
df_7_2['post']=['汉高帝','唐高祖','明太祖','中华民国临时大总统','隋文帝']
print(df_7_2)
删除和修改
# 删除
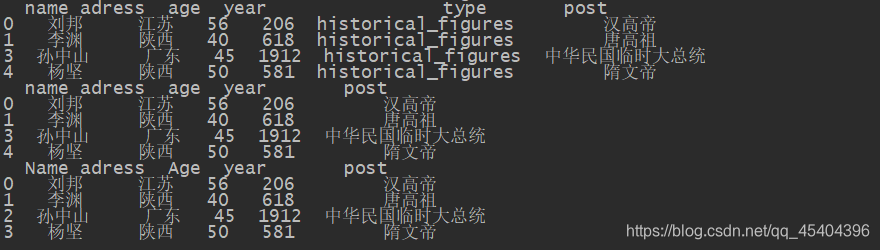
df_7_3=df_7_2.drop(2)
print(df_7_3)
df_7_4=df_7_3.drop('type',axis=1)
print(df_7_4)
# 修改
df_7_4.rename(index={3:2,4:3},columns={'name':'Name','age':'Age'},inplace=True)
print(df_7_4)