Synonyms
Chinese Synonyms for Natural Language Processing and Understanding.
最近需要做一个基于知识图谱的检索,但是因为知识图谱中存储的都是标准关键词,所以需要对用户的输入进行标准关键词的匹配。
于是采用了基于同义词库的方式,将《非标准表述》 映射到 《标准表述》,这就是Synonyms的起源。
下面我们来仔细聊聊Synonyms。
首先需要语料,我们采用了开放的大规模中文语料——维基百科中文语料。
(1)下载维基百科中文语料。
(2)繁简转换。
(3)分词。具体操作访问wikidata-corpus
使用gensim自带的word2vec包进行词向量的训练。
(1)下载gensim。
(2)输入分词之后的维基语料进行词向量训练。
(3)测试训练好的词的近义词。最后进行同义词库测试。
import synonyms
print("人脸: %s" % (synonyms.nearby("人脸")))
print("识别: %s" % (synonyms.nearby("识别")))
print("NOT_EXIST: %s" % (synonyms.nearby("NOT_EXIST")))人脸: [['图片', '图像', '通过观察', '数字图像', '几何图形', '脸部', '图象', '放大镜', '面孔', 'Mii'], [0.597284, 0.580373, 0.568486, 0.535674, 0.531835, 0.530095, 0.525344, 0.524009, 0.523101, 0.516046]]
识别: [['辨识', '辨别', '辨认', '标识', '鉴别', '标记', '识别系统', '分辨', '检测', '区分'], [0.872249, 0.764099, 0.725761, 0.702918, 0.68861, 0.678132, 0.663829, 0.661863, 0.639442, 0.611004]]使用:
pip install -U synonyms更多的结果:
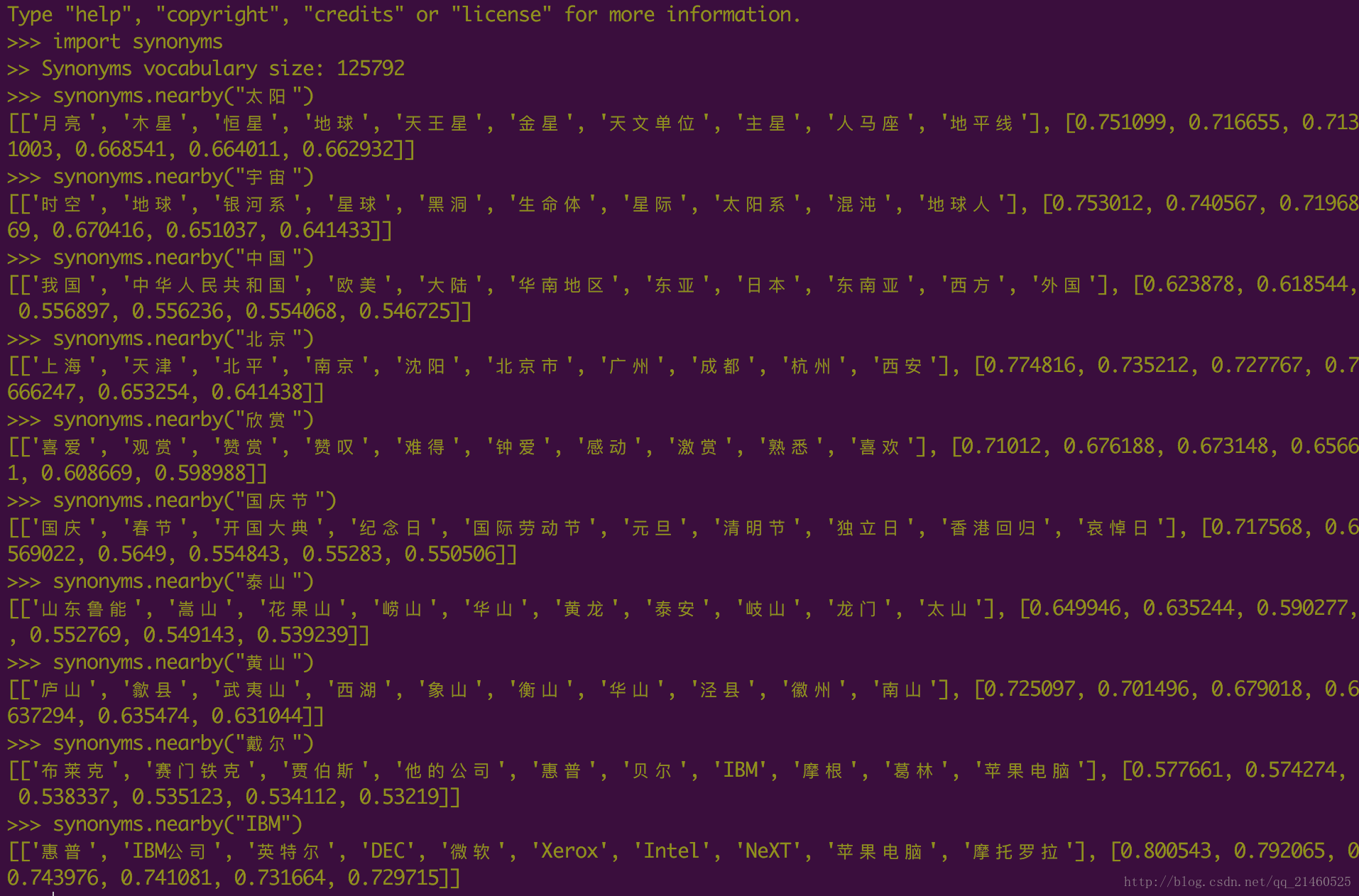
场景:
- 推荐。将用户输入进行近义词分析,可以推荐给用户相关的关键词。
- 搜索。将用户非标准化输入转换为标准化输入,进而进行数据库/知识库检索。
- 相似度计算。解决在自然语言处理任务中常见的词语语义相似度计算问题。
- 。。。。。。
Why Synonyms
1、准确率高。
从上面的示例可以看到synonyms作为开放领域的同义词库,已经有较优的表现。
2、快速使用。
即安即用,方便开发者直接调用。
3、方便搭建。