1. HMM模型
1.1 模型
隐马尔可夫模型(Hidden Markov Model, HMM)是可用于标注问题(属于监督学习)的统计学习模型,描述由隐藏的马尔可夫链随机生成观测序列的过程,属于生成模型。HMM模型是关于时序的概率模型,由隐藏的状态随机序列生成可观测的观测随机序列,在语音识别、自然语言处理、生物信息、模式识别、安全领域中的网络安全领域等有广泛的应用。
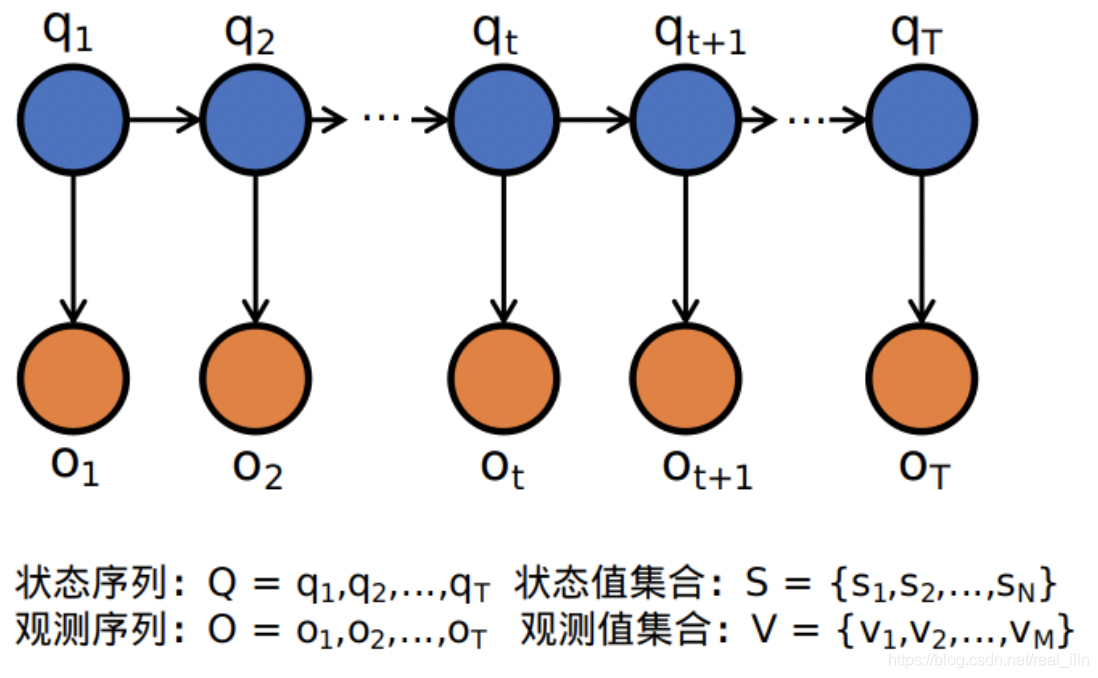
HMM属于概念图模型中的有向图模型。上图中一个结点代表一个随机变量,有向边代表依赖关系。比如
依赖于
。这里注意:观测序列是依赖于隐状态的!
1.2 HMM参数
A为状态转移矩阵:各个隐状态之间转化的概率,矩阵 代表隐状态 转化为 状态的概率。比如第 行表示隐状态 转化为每一个状态的概率。本质上是一个条件概率:
B为发射矩阵或者叫做观测概率矩阵:在某个隐状态下观测到不同的预测值的概率,
。其中
是在t时刻处于状态
的条件下生成观测
的概率。
为初始化概率:初始状态下各个隐状态发生的概率
1.3 两个假设
- 齐次马尔可夫假设:隐状态
发生只依赖于上一个隐状态
- 观测独立性假设:观测值
的出现只依赖于此时的状态,与其它的隐状态无关
1.4 三个问题
-
概率计算问题(Evaluating),给定模型 和观测序列 ,计算在模型 下观测序列 出现的概率 。使用的方法:向前或向后算法。
-
学习问题(Learning),已知观测序列 ,估计模型的参数 ,使得在该模型下观测序列的概率 最大。有监督(已经观测序列和标注序列)的训练方法:极大似然估计的方法估计参数,无监督(只知道观测序列,不知道标注序列)的训练方法:BW/EM算法进行参数估计。
-
预测问题,也称为解码(Decoding)问题。已知模型 和观测序列 ,求对给定观测序列条件概率 最大的状态序列 ,即给定观测序列求最有可能的对应的状态序列,使用动态规则求解,即Viterbi算法。注意Viterbi算法不是HMM的专属,在CRF中也有使用。
2. HMM用于分词
HMM模型代码:
import pickle
import json
# 定义模型的四个状态 B代表词的第一个字,M代表中间的字,
# E代表词的结尾,S表示单独的一个字
STATES = {'B', 'M', 'E', 'S'}
EPS = 0.0001
# 定义停顿标点
seg_stop_words = {" ", ",", "。", "“", "”", '“', "?", "!", ":", "《", "》", "、", ";", "·", "‘ ", "’", "──", ",", ".", "?",
"!", "`", "~", "@", "#", "$", "%", "^", "&", "*", "(", ")", "-", "_", "+", "=", "[", "]", "{", "}",
'"', "'", "<", ">", "\\", "|" "\r", "\n", "\t"}
class HmmModel:
def __init__(self):
"""
类中维护的模型参数均为频数而非频率, 这样的设计使得模型可以进行在线训练,
使得模型随时都可以接受新的训练数据继续训练,不会丢失前次训练的结果
"""
# 转移矩阵,二维:trans_mat[stat1][stat2]表示训练集中由stat1转化为stat2的次数
self.trans_mat = {}
# 发射矩阵,二维:emit_mat[stat1][char]表示训练集中单字char被标注为状态stat1的次数
self.emit_mat = {}
# 初始矩阵,一维:init_vec:表示状态stat在训练集中出现的次数
self.init_vec = {}
# 统计四个状态出现的次数 二维用来计算初始概率
self.state_count = {}
# 状态 四个状态
self.states = STATES
self.inited = False
# 初始化hmm模型的参数矩阵
def setup(self):
for state in self.states:
self.trans_mat[state] = {}
# 转移矩阵初始化完成,trans_mat[i][j]是指状态i转化为状态j的概率
for target in self.states:
self.trans_mat[state][target] = 0.0
# 发射矩阵每一行是一个状态,每一列是一个字
self.emit_mat[state] = {}
# 初始状态为0
self.init_vec[state] = 0.0
self.state_count[state] = 0
self.inited = True
# 模型保存, 支持两种类型的数据格式,json和pickle
def save(self, filename='hmm.json', code='json'):
with open(filename, 'w', encoding='utf-8') as f:
data = {
'trans_mat': self.trans_mat,
'emit_mat': self.emit_mat,
'init_vec': self.init_vec,
'state_count': self.state_count,
}
if code == 'json':
txt = json.dumps(data)
txt = txt.encode('utf-8').decode('unicode-escape')
f.write(data)
elif code == 'pickle':
pickle.dump(data, f)
# 模型加载
def load(self, filename='hmm.json', code='json'):
with open(filename, 'r', encoding='utf-8') as f:
if code == 'json':
model = json.load(f)
elif code == 'pickle':
model = pickle.load(f)
# 这里加载模型是把参数初始化了,并没有返回文件
self.trans_mat = model['trans_mat']
self.emit_mat = model['emit_mat']
self.init_vec = model['init_vec']
self.state_count = model['state_count']
self.inited = True
# 模型训练 参数是观测序列与状态序列
def do_train(self, observes, states):
if not self.inited:
self.setup()
for i in range(len(states)):
if i == 0:
# 把一条序列的第一个状态作为初始状态
self.init_vec[states[0]] += 1
# 所有的状态计数
self.state_count[states[0]] += 1
else:
# states[i-1][i] 第i-1个状态转化为第i个状态的次数
self.trans_mat[states[i - 1]][states[i]] += 1
self.state_count[states[i]] += 1
# 处理emit_mat
# 如果观测值在之前没有出现过,计为1,否则+1
if observes[i] not in self.emit_mat[states[i]]:
self.emit_mat[states[i]][observes[i]] = 1
else:
self.emit_mat[states[i]][observes[i]] += 1
# 在进行预测前,将各个矩阵中的频数转换为频率
def get_prob(self):
init_vec = {}
trans_mat = {}
emit_mat = {}
# default是一个非零的数
defalut = max(self.state_count.values())
# 以B开头的个数除以B出现的总个数,如果是零的话就为0
for key in self.init_vec:
if self.state_count[key] != 0:
init_vec[key] = float(self.init_vec[key] / self.state_count[key])
else:
init_vec[key] = float(self.init_vec[key] / defalut)
# B转化为M的概率为B转化为M的次数除以B出现的总次数
for key1 in self.trans_mat:
trans_mat[key1] = {}
for key2 in self.trans_mat[key1]:
if self.state_count[key1] != 0:
trans_mat[key1][key2] = float(self.trans_mat[key1][key2] / self.state_count[key1])
else:
trans_mat[key1][key2] = float(self.trans_mat[key1][key2] / defalut)
# B状态下“我”出现的概率为B状态下“我”出现的次数除以B状态出现的总次数
for key1 in self.emit_mat:
emit_mat[key1] = {}
for key2 in self.emit_mat[key1]:
if self.state_count[key1] != 0:
emit_mat[key1][key2] = float(self.emit_mat[key1][key2] / self.state_count[key1])
else:
emit_mat[key1][key2] = float(self.emit_mat[key1][key2] / defalut)
return init_vec, trans_mat, emit_mat
# 模型预测,使用viterbi算法
def do_predict(self, sequence):
tab = [{}]
path = {}
init_vec, trans_mat, emit_mat = self.get_prob()
for state in self.states:
tab[0][state] = init_vec[state] * emit_mat[state].get(sequence[0], EPS)
path[state] = [state]
# 创建动态搜索表
for t in range(1, len(sequence)):
tab.append({})
new_path = {}
for state1 in self.states:
items = []
for state2 in self.states:
if tab[t - 1][state2] == 0:
continue
prob = tab[t - 1][state2] * trans_mat[state2].get(state1, EPS) * emit_mat[state2].get(sequence[t],
EPS)
items.append((prob, state2))
# max()函数,默认是list中所有tuple的第一个值的最大值
best = max(items)
tab[t][state1] = best[0]
new_path[state1] = path[best[1]] + [state1]
path = new_path
# 搜索最优路径
prob, state = max([(tab[len(sequence) - 1][state], state) for state in self.states])
return path[state]
# 打标签的工具函数
def get_tags(word):
tag = []
if len(word) == 1:
return ['S']
elif len(word) == 2:
return ['B', 'E']
else:
num_mid = len(word) - 2
tag.append('B')
tag.extend(['M'] * num_mid)
tag.append('E')
return tag
# 根据预测得到的标注序列将输入的句子分割为词语列表,也就是预测得到的状态序列,
# 解析成一个 list 列表进行返回,具体实现如下:
def cut_sent(src, tags):
word_list = []
start = -1
started = False
if len(tags) != len(src):
return None
if tags[-1] not in {'S', 'E'}:
if tags[-2] in {'S', 'E'}:
tags[-1] = 'S'
else:
tags[-1] = 'E'
for i in range(len(tags)):
if tags[i] == 'S':
if started:
started = False
word_list.append(src[start:i])
word_list.append(src[i])
elif tags[i] == 'B':
if started:
word_list.append(src[start:i])
start = i
started = True
elif tags[i] == 'E':
started = False
word = src[start:i + 1]
word_list.append(word)
elif tags[i] == 'M':
continue
return word_list
class HMMKnife(HmmModel):
def __init__(self, *args, **kwargs):
super(HMMKnife, self).__init__(*args, **kwargs)
self.state = STATES
self.data = None
# 加载训练数据
def read_text(self, filename):
self.data = open(filename, 'r', encoding='utf-8')
# 训练模型
def train(self):
if not self.inited:
self.setup()
for line in self.data:
line = line.strip()
if not line:
continue
# 观测序列
observe = []
for i in range(len(line)):
if line[i] == ' ':
continue
else:
observe.append(line[i])
# 状态序列
words = line.split(' ')
states = []
for word in words:
if word in seg_stop_words:
continue
states.extend(get_tags(word))
# 开始训练数据
if len(observe) >= len(states):
self.do_train(observe, states)
else:
pass
# 对给定的句子分词
def lcut(self, sentense):
tags = self.do_predict(sentense)
return cut_sent(sentense, tags)
参考 :
https://www.jianshu.com/p/59490ffe7f7c
3. jieba的使用
保存预训练好的参数,直接使用并预测。
jieba对句子分词的核心代码在finalseg模块中:
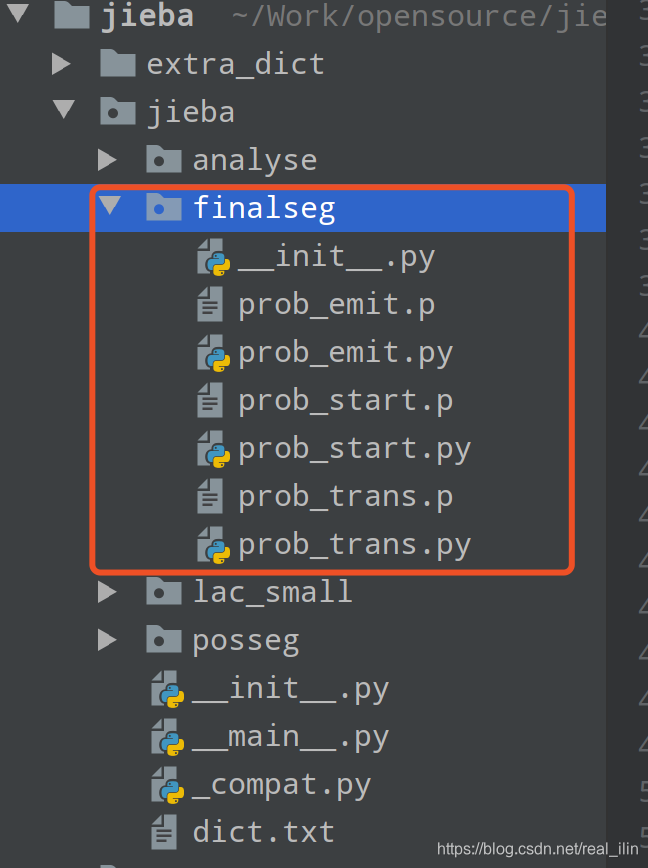
从模型信息中可以看出来,HMM模型最核心的三个矩阵emit,start,trans矩阵都是训练好的数据存在模块中的。
加载模型时会加载矩阵,直接使用viterbi算法根据句子计算最优的隐状态(BMES)的序列。

