requests模块的返回对象是一个Response对象,可以从这个对象中获取需要的信息。下面 r 代表Response对象。
【r.text】:文本响应内容。
【r.context】:二进制响应内容。
【r.json()】:JSON响应内容 。
【r.raw】:原始相应内容。
(1)文本响应内容。
例子:
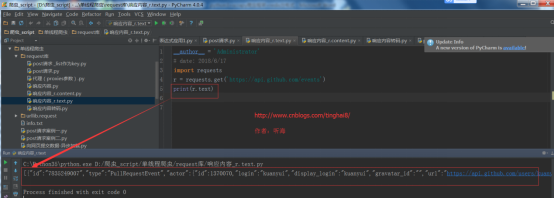
import requests
r = requests.get('https://api.github.com/events')
print(r.text)
运行结果:
对于非文本请求,你也能以字节的方式访问请求响应体。
(2)二进制响应内容。
对于非文本请求,你也能以字节的方式访问请求响应体。
例子1:
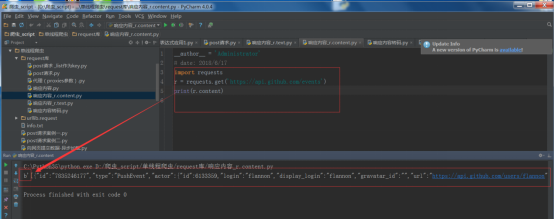
import requests
r = requests.get('https://api.github.com/events')
print(r.content)
运行结果:
Requests 会自动为你解码 gzip 和 deflate 传输编码的响应数据。
例子2,以请求返回的二进制数据创建一张图片。
from PIL import Image
from io import BytesIO
i = Image.open(BytesIO(r.content))
(3)JSON 响应内容。
Requests 中也有一个内置的 JSON 解码器,助你处理 JSON 数据。
例子:
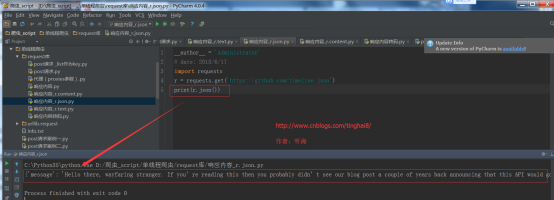
import requests
r = requests.get('https://github.com/timeline.json')
print(r.json())
运行结果:
如果 JSON 解码失败, r.json 就会抛出一个异常。例如,相应内容是 401 (Unauthorized),尝试访问 r.json 将会抛出 ValueError: No JSON object could be decoded 异常。
(4)Raw响应内容。
在罕见的情况下,你可能想获取来自服务器的原始套接字响应,那么你可以访问 r.raw。 如果你确实想这么干,那请你确保在初始请求中设置了 stream=True。具体你可以这么做。
例子:
import requests
r = requests.get('https://github.com/timeline.json', stream=True)
print(r.raw)
运行结果:
但一般情况下,你应该以下面的模式将文本流保存到文件。
with open(filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size):
fd.write(chunk)
使用 Response.iter_content 将会处理大量你直接使用 Response.raw 不得不处理的。 当流下载时,上面是优先推荐的获取内容方式。