最优化算法与matlab应用5:遗传算法
本文节选于王正林《精通MATLAB_科学计算》第2版
遗传算法GA是一种直接的随机搜索方法,它是在适者生存的自然进化过程中逐步建立的。算法原理类似于模拟退火,适用于寻找具有多个极值的目标函数的全局最小解。
算法步骤


交叉:交叉操作是遗传算法中最主要的遗传操作。通过交叉操作可以得到新一代个体,新个体组合了其父辈个体的特性。交叉体现了信息交换的思想。
变异:变异首先在群体中随机选择一个个体,对于选中的个体以一定的概率随机地改变串结构数据中某个串的值。变异发生的概率很低,通常取0.001-0.01之间。
Matlab调用函数
function [xo,fo] = genetic(f,x0,l,u,Np,Nb,Pc,Pm,eta,kmax)
%f为待求函数,x0初值,l,u上下限,Np群体大小,Nb每一个变量的基因值(二进制数)
%Pc交叉概率,Pm变异概率,eta学习率,kmax最大迭代次数
主程序文件:
function [xo,fo] = genetic(f,x0,l,u,Np,Nb,Pc,Pm,eta,kmax)
% 基因算法求f(x)最小值 s.t. l <= x <= u
%f为待求函数,x0初值,l,u上下限,Np群体大小,Nb每一个变量的基因值(二进制数)
%Pc交叉概率,Pm变异概率,eta学习率,kmax最大迭代次数
N = length(x0);
%%%%%确定各变量缺省值
if nargin < 10
kmax = 100; %最大迭代次数缺省为100
end
if nargin < 9|eta > 1|eta <= 0
eta = 1; %学习率eta,(0 < eta < 1)
end
if nargin < 8
Pm = 0.01; %变异概率缺省0.01
end
if nargin < 7
Pc = 0.5; %交叉概率缺省0.5
end
if nargin < 6
Nb = 8*ones(1,N);%每一变量的基因值(二进制数)
end
if nargin < 5
Np = 10; %群体大小(染色体数)
end
%%%%%生成初始群体
NNb = sum(Nb);
xo = x0(:)'; l = l(:)'; u = u(:)';
fo = feval(f,xo);
X(1,:) = xo;
for n = 2:Np
X(n,:) = l + rand(size(x0)).*(u - l); %初始群体随机数组
end
P = gen_encode(X,Nb,l,u); %编码为2进制字串
for k = 1:kmax
X = gen_decode(P,Nb,l,u); %解码为10进制数
for n = 1:Np
fX(n) = feval(f,X(n,:));
end
[fxb,nb] = min(fX); %选择最适合的,函数值最小的
if fxb < fo
fo = fxb;
xo = X(nb,:);
end
fX1 = max(fxb) - fX; %将函数值转化为非负的适合度值
fXm = fX1(nb);
if fXm < eps %如果所有的染色体值相同,终止程序
return;
end
%%%%%复制下一代
for n = 1:Np
X(n,:) = X(n,:) + eta*(fXm - fX1(n))/fXm*(X(nb,:) - X(n,:));%复制准则
end
P = gen_encode(X,Nb,l,u); %对下一代染色体编码
%%%%%%随机配对/交叉得新的染色体数组
is = shuffle([1:Np]);
for n = 1:2:Np - 1
if rand < Pc
P(is(n:n + 1),:) = crossover(P(is(n:n + 1),:),Nb);
end
end
%%%%%%变异
P = mutation(P,Nb,Pm);
end
function P = gen_encode(X,Nb,l,u)
%将群体X的状态编码为二进制数组P
Np=size(X,1); %群体大小
N = length(Nb); %变量(状态)维数
for n = 1:Np
b2 = 0;
for m = 1:N
b1 = b2+1;
b2 = b2 + Nb(m);
Xnm =(2^Nb(m)- 1)*(X(n,m) - l(m))/(u(m) - l(m)); %编码方程
P(n,b1:b2) = dec2bin(Xnm,Nb(m)); %10进制转换为2进制
end
end
function X = gen_decode(P,Nb,l,u)
% 将二进制数组P解码为群体X的状态矩阵
Np = size(P,1); %群体大小
N = length(Nb); %变量维数
for n = 1:Np
b2 = 0;
for m = 1:N
b1 = b2 + 1;
b2 = b1 + Nb(m) - 1;
X(n,m) = bin2dec(P(n,b1:b2))*(u(m) - l(m))/(2^Nb(m) - 1) + l(m); %解码方程
end
end
function chrms2 = crossover(chrms2,Nb)
%两个染色体间的交叉
Nbb = length(Nb);
b2 = 0;
for m = 1:Nbb
b1 = b2 + 1;
bi = b1 + mod(floor(rand*Nb(m)),Nb(m));
b2 = b2 + Nb(m);
tmp = chrms2(1,bi:b2);
chrms2(1,bi:b2) = chrms2(2,bi:b2);
chrms2(2,bi:b2) = tmp;
end
function P = mutation(P,Nb,Pm)
%变异
Nbb = length(Nb);
for n = 1:size(P,1)
b2 = 0;
for m = 1:Nbb
if rand < Pm
b1 = b2 + 1;
bi = b1 + mod(floor(rand*Nb(m)),Nb(m));
b2 = b2 + Nb(m);
P(n,bi) = ~P(n,bi);
end
end
end
function is = shuffle(is)
%打乱染色体次序
N = length(is);
for n = N:-1:2
in = ceil(rand*(n - 1));
tmp = is(in);is(in) = is(n); is(n) = tmp; %将第n个元素与第in个元素交换
end
实例:
求解无约束最优化问题。
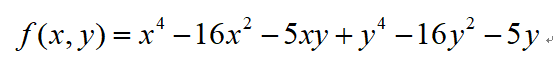
f = inline('x(1)^4-16*x(1)^2-5*x(1)*x(2)+x(2)^4-16*x(2)^2-5*x(2)','x');
l = [-5 -5]; %下限
u = [5 5]; %上限
x0 = [0 0];
Np = 30; %群体大小
Nb = [12 12]; %代表每个变量的二进制位数
Pc = 0.5; %交叉概率
Pm = 0.01; %变异概率
eta = 0.8; %学习率
kmax = 200; %最大迭代次数
[xos,fos]=fminsearch(f,x0)
[xo_gen,fo_gen] = genetic(f,x0,l,u,Np,Nb,Pc,Pm,eta,kmax)
