- 本教程来源:我学习MySQL语法时所做的笔记
- 补充:在cmd、PowerShell中进入MySQL命令行的一般命令是
mysql -u root -p,然后输入密码即可 - 今日,将笔记整理归纳后发出来供大家学习使用
相关文章推荐:
目录一:概述
数据库:
- 本质上是文件(为了让数据永久保存)
- 有很多写好的流程(可以帮我们操作文件:读、写…)
- 我们想要读取和保存的数据,给数据库发送指令,让它帮我们操作文件的读写(省去了我们操作I/O的过程)
数据库可以分为两类:
- 关系型数据库(以表格的形式记录数据和关系),用的指令是SQL(Structured Query Language,结构化查询语言)
- 非关系型数据库(以key-value形式只记录数据本身),用的指令是NOSQL(Not Only SQL)
SQL:
(Structured Query Language,结构化查询语言)
历经几乎20年,在1989年,由国际标准化组织(ISO)颁布SQL正式国际标准
现在很多的数据库厂商还在遵循沿用着这套规范(SQL89标准)
各家的数据库:
学习任何一家的数据库产品,其实都差不多一样(大同小异,学习了一个数据库后,再学习其它数据库就简单的多了)
- IBM
- DB2数据库
- Microsoft
- SQLServer(和windows系统融合的很好,但是在其他系统上兼容性就差了挺多)
- Access(Office办公软件中的很小的一个数据库,不多见)
- Oracle
- Oracle(商用的)
- MySQL(开源免费的,最早是一家瑞典的公司的,先被SUN并购,后SUN被Oracle并购,现在很流行)
MySQL:
- 操作数据库的语言规范:SQL(关键字不区分大小写,但是建议写大写,风格统一)
-
DDL(Data Definition Language,数据定义语言)
- 创建、删除、修改数据库中的对象(表格,用户,索引,视图,存储过程,触发器)
- 三个关键字:创建
create、删除drop、修改alter - 请看目录二
-
DML(Data Manipulation Language,数据操作语言)
- 操作数据库表格中的具体数据
- 写数据:新增
insert、删除delete、修改update - 读数据:查询
select - 请看目录三
-
DCL(Data Control Language,数据控制语言)
- 控制用户权限
- (赋予)grant 权限,权限 to 用户
- (回收)revoke 权限,权限 from 用户
- 请看目录四
-
TPL(Transaction Process Language,事务处理语言)
- 可以理解为多线程并发访问同一个文件资源,带来的安全问题
- begin Transaction
- 操作
- commit提交
- rollback回滚
- save point A 保存还原点
- 这部分内容,在使用编程语言操作数据库的时候用的非常频繁,而且用起来很简单,本文暂不讲
目录二: 数据库、表格的创建、修改和删除(DDL)
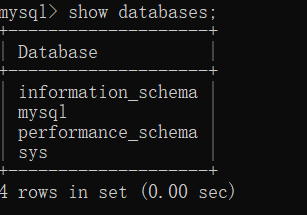
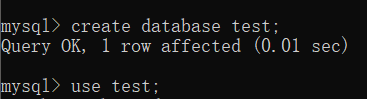
1. 先在MySQL数据库中创建一个database
create database 数据库名;
建议大家起名字最好遵循一定的规范----英文(要见名知义)
注意:在很多编程语言中(比如:Python、Java),英文字母区分大小写
而MySQL英文字母不区分大小写(关键字、表格名字、列名字…)
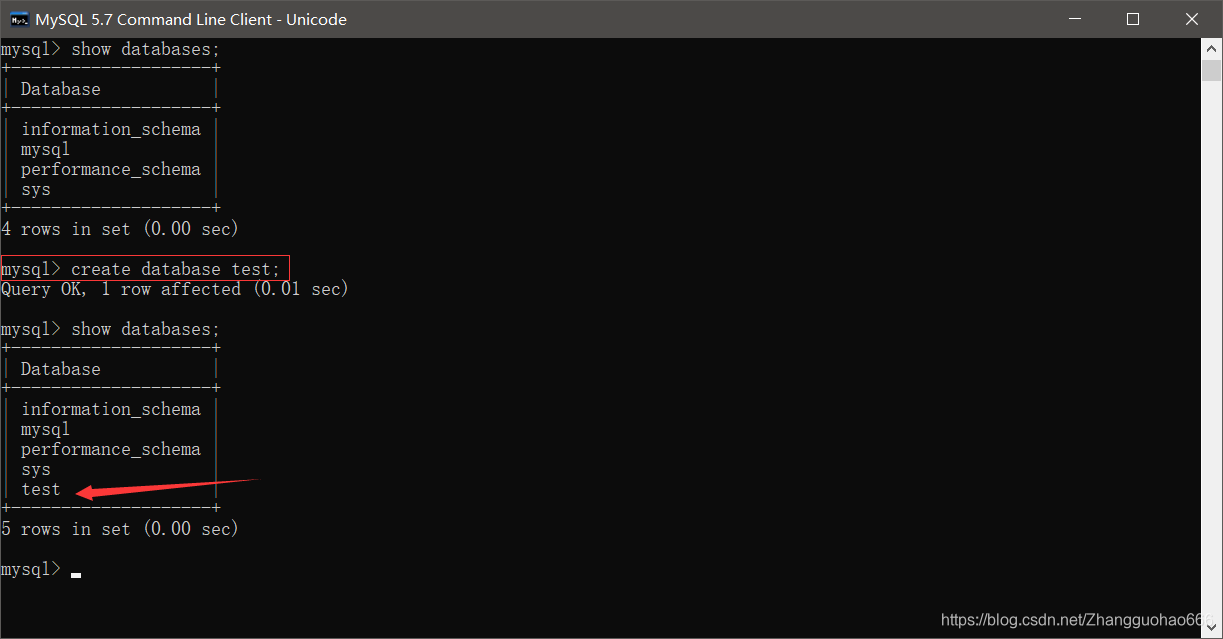
显然,test 数据库创建成功了
2. 在我们自己的database里面创建table的格式
(暂时,创建的表格中列的属性只有数据类型和长度)
create table(
列名 数据类型(长度),
列名 数据类型(长度),
列名 数据类型(长度)
)
这个写法其实和Java中domain实体类的写法非常相似
3. 数据库中的数据类型
按存储数据的方式来分类,分为三类:
- 数值型
- 整数:
tinyint1字节,smallint2字节,mediumint3字节,int或者integer4字节,bigint8字节 - 小数:
float4字节,double8字节;decimal,numeric(前两个的底层的计数方式更加精确,可以表示更多的数字;后两者和前两者差不多,但是则相对固定了些)
- 整数:
- 字符串
- (数据库里所有的字符串类型都是用单引号,不是双引号)
char字符串,定义之后长度是固定的varchar可变长字符串,定义之后长度是根据存储信息发生改变的,这个用的更多binary字符串形式存储二进制,varbinary是可变二进制blob二进制大文本,text正常字符大文本
- 日期/时间
date日期time时间datetime日期&时间- 日期和时间,在定义的时候都不需要长度,因为他们的格式是固定的
- 还有,
date只有年月日,time只有时分秒,datetime有年月日时分秒 timestamp时间戳:时间表示的信息比上面三个更加精细,显示的时间除了年月日时分秒外,还有毫秒、时区
4. 在自己的datebase中创建一个表格
[例] 先选择 test 数据库
use test;
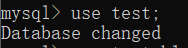
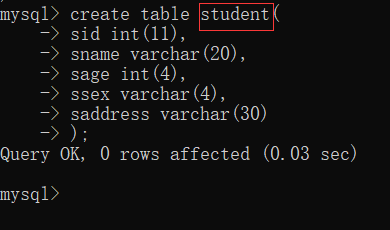
[例] 然后,在 test 数据库中创建一个 student 表格
create table student(
sid int(11),
sname varchar(20),
ssex varchar(4)
);
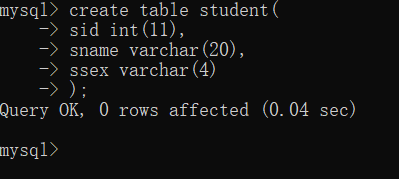
5. 通过DDL语句修改表格的结构
- 表格名字错误
- 修改原有的列(列名错误,列类型不对、列长度不够)
- 新增一个列
- 删除一个列
修改表名:
alter table 表名 rename [to] 新名字;
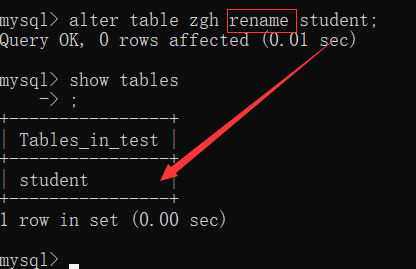
[例] 修改 student 的表名为 zgh
alter table student rename to zgh;
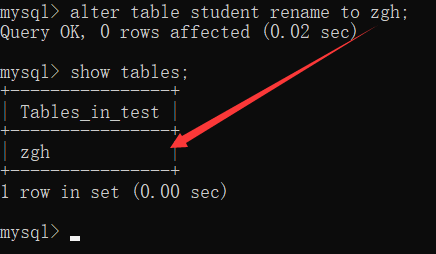
[例] to可以省略:
alter table zgh rename student;
修改原有的列(列名错误,列类型不对、列长度不够):
alter table 表名 change 原列名 新列名 新类型 新长度;
[例] 将 student 表的 sid 列 改名为 snum,并将类型改为 char(11)
alter table student change sid snum char(11);

新增一个列:
alter table 表名 add 新列名 新类型 新长度;
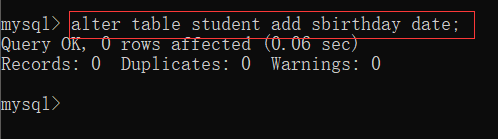
[例] 在 student 表中新增一个列,列名为 sbirthday,类型为 date
alter table student add sbirthday date;
删除原有的列:
alter table 表名 drop 原列名;
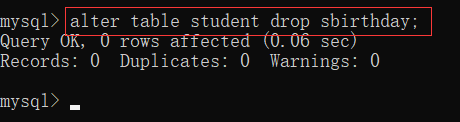
[例] 将 student 表的 sbirthday 列 删除
alter table student drop sbirthday;
6. 删除表格
drop table 表名;
[例] 删除 student 表
drop table student;

7. 删除数据库
drop database 数据库名;
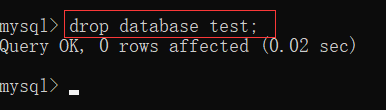
[例] 将 test 数据库删除
drop database test;
目录三:表格的增删改查(DML)
- 操作 的是 表格 中的 数据信息
- 表格:
行:记录
列:属性 - 写入信息(数据库中的信息发生了真实的改变)
新增insert,删除delete,修改update - 读取信息(数据库中的信息没有发生改变)
查询select
学习DDL语句之前,
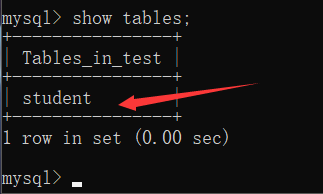
[例] 先创建一个数据库 test,选择这个数据库,再在这个 test 中创建一个表格 student
create database test;
use test;
create table student(
sid int(11),
sname varchar(20),
sage int(4),
ssex varchar(4),
saddress varchar(30)
);
然后,开始学习了:
1. 新增记录
insert into 表名(列名,列名,列名,...)values(值,值,值,...);
注意:列名和值是对应的(数据类型,数据的长度),还有列名可以根据需求,有不同的数量
[例]
insert into student(sid, sname) values(1, 'zgh');

2. 查询记录
select 列名,列名,列名,... from 表名
[例]
select sid, sname, sage, ssex, saddress from student;

可以看出,数据库的表中存储的元素都是引用类型的
如果是要查询的信息包含所有的属性(即:列)
还有一种写法更加的简单,不过它在底层方面上,比上面的的写法的查询速度要慢
select * from 表名;
[例]
select * from student;
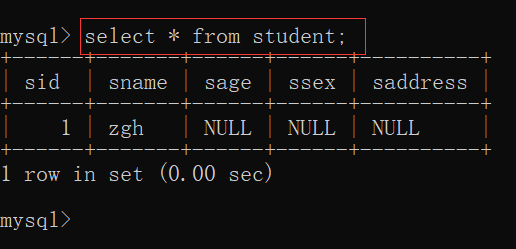
要在表中新增一行信息,包含所有的属性(即:列),有一个更加简单的写法
- 省略掉列名不写
- 不过values里面的值要和表格的属性的顺序对应好,类型,长度也要一一对应
insert into 表名 values(值,值,值,...);
[例]
insert into student values(2, 'hq', 18, 'male', 'whxyedu');
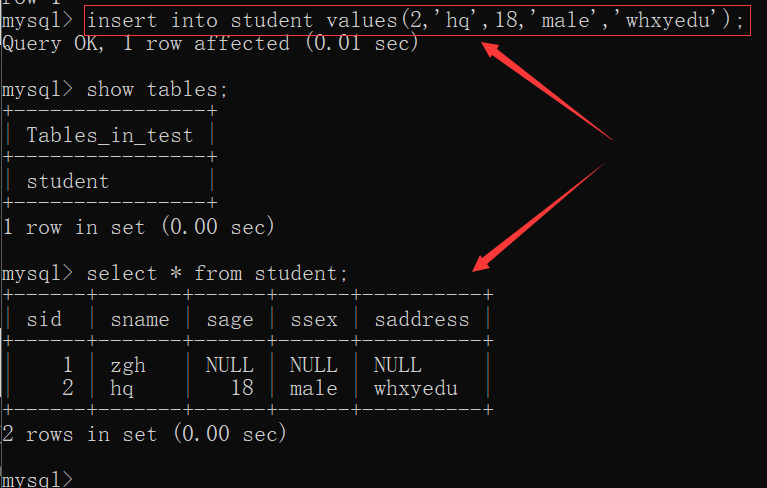
一次性增加多条记录:
insert into 表名 values(值,值,值,...),(值,值,值,...);
[例]
insert into student
values(3, 'licw', 3, 'male', 'whxyedu'),
(4, 'xy', 38, 'male', 'whxyedu');
不能存储中文的解决办法
3. 存储中文信息
此命令可以查询数据库的默认字符集:
select schema_name,default_character_set_name
from information_schema.schemata
where schema_name = 'test';
我记得MySQL5.7的默认默认字符集是不支持存储中文的,
前几天,我使用zip压缩包(免安装方式)重新安装了MySQL8.0,发现在命令行中可以直接存储中文,研究之后发现:
- 在MySQL5.7中,数据库的默认字符集是latinl(不支持中文)
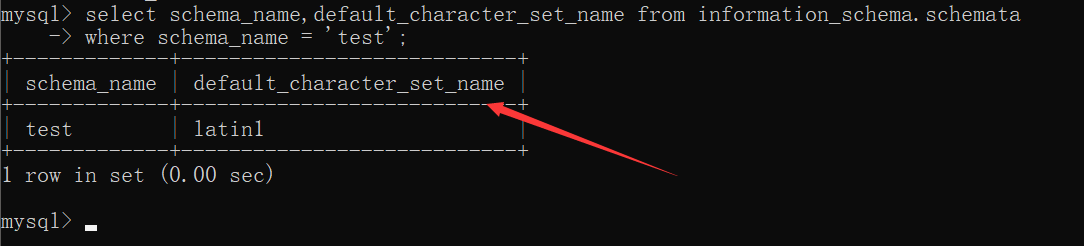
- 而在MySQL8.0中,数据库的默认字符集变为了utf8mb4(兼容utf8,是支持中文的)

3 - 扩展:字符集设置
- 如果你在使用MySQL的过程中,发现不能存储中文字符,可以看一下这部分的内容
这部分内容是我很久以前的笔记,当时是使用installer安装MySQL5.7,并且只选择安装MySQL Community Server,安装完成后有两个命令行客户端给我使用,然后我学习时的截图都是基于这两个客户端
其中一个客户端是Unicode字符,但是使用此命令行客户端直接输入中文字符是不可以的,还要进行一些设置
原因是,MySQL8.0之前的某些版本,数据库的默认字符集可能不支持存储中文,
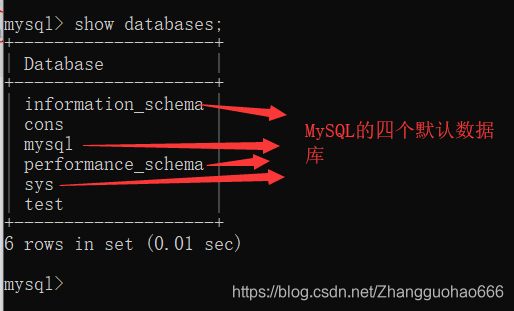
- MySQL有四个默认的database,
information_schema是其中一个:
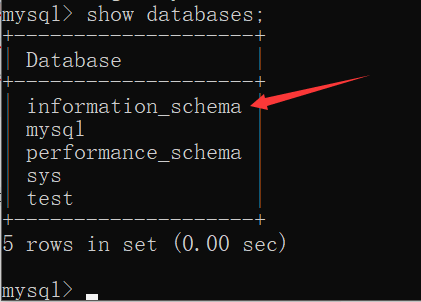
- 方法一:设置database的默认字符集为utf8,从此之后,使MySQL创建的新数据库支持存储中文
但是基于默认字符集创建的(原有的)数据库,其字符集不能修改了,若要使它存储中文,只能删掉咯 - 方法二:不修改MySQL的全局字符集,在创建数据库的时候可以单独设置这个数据库的字符
create database test default character set = 'utf8';

- 方法三:如果不想让创建的数据库中的所有表存储中文,只单纯的某一张表格需要中文,创建表格的时候设置字符集
create table 表名(
列名 类型 长度,
列名 类型 长度
)character set utf8;
还可以同时设置排序规则:
create table 表名(
列名 类型 长度,
列名 类型 长度
)character set utf8 collate utf8_general_ci;
排序规则有两个:
utf8_general_ci默认,性能比较高,可能不太精确utf8_unicode_ci性能比较低,扩展性好
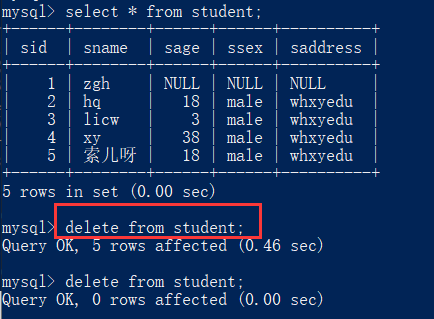
4. 删除记录
如果不写where,表中全部记录将被全部删掉:
delete from 表名
where 条件;
[例]
delete from student;
5. 修改记录
update 表名 set 列=值,列=值
[where 条件];
[例] 先在 student 表中增加两行数据,再进行修改操作
insert into student values(1, 'zgh', 18, 'male', '地府'),
(2, '索儿呀', 18, 'male', '冥府');
select * from student;
update student set sname = 'zhangguohao666', ssex = 'boy';
select * from student;
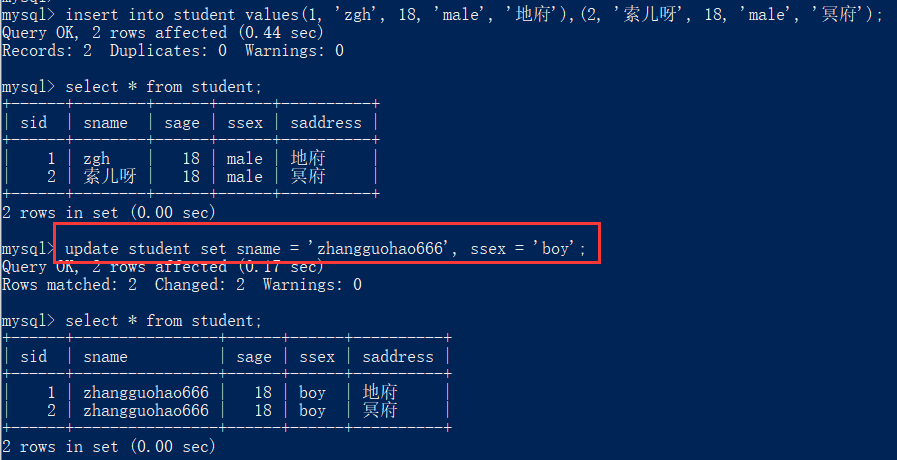
可以很明显的看到,由于没有对表中的值进行筛选,默认选择了 student 表中所有的内容,所有内容的 sname 和 ssex 都被改了
6. 显示表格的状态
显示student表格的状态:
show table status
from test
like 'student';

这就是命令行客户端的局限性了,因为查询的内容太多,就如上图这样重合了
目录四:用户的创建、删除与权限配置(DCL)
数据控制语言
- 控制用户的权限
grant赋予revoke回收
常用的MySQL权限
数据库/数据表/数据列权限:
Create建立新的数据库或数据表Alter修改已存在的数据表(例如增加/删除列)Drop删除数据库或数据表Insert增加表的记录Delete删除表的记录Update修改表中已存在的记录Select显示/搜索表的记录- ==================================
References允许创建外键Index建立或删除索引Create View允许创建视图Create Routine允许创建存储过程和包Execute允许执行存储过程和包Trigger允许操作触发器Create User允许更改、创建、删除、重命名用户和收回所有权限
全局管理MySQL用户权限:
Grant Option允许向其他用户授予或移除权限Show View允许执行show create view语句Show Databases允许账户执行show databases来查看数据库Lock Table允许执行lock tables来锁定表格File在MySQL上读写文件Process显示或杀死属于其它用户的服务线程Reload重载访问控制表,刷新日志等ShutDown关闭MySQl服务
特别的权限:
-
All允许做任何事(和root一样) -
Usage只允许登录,其它什么也不允许做 -
如果一开始是通过MySQL命令行客户端来学习MySQL,那么本目录内容需要在终端中进行,因为MySQL命令行客户端一打开就是以 root 身份登录
-
如果你会使用终端来玩MySQL,请自行跳过本目录中扩展一、扩展二的内容
扩展一:Windows中配置环境变量(如果配置过,请自行跳过)
使用 installer 安装MySQL5.7,并且只选择安装MySQL Community Server,安装完成后有两个命令行客户端给我使用,然后我学习时的截图都是基于这两个客户端
-
使用这两个客户端,打开时默认以 root 身份进入
-
如果要换身份登录,我们需要先进行MySQL的环境变量配置,再使用windows的终端(cmd、PowelShell)
-
MySQL的默认安装路径:
C:\Program Files\MySQL\MySQL Server 版本号 -
需要配置的环境变量(比如说我安装的是MySQL5.7):
C:\Program Files\MySQL\MySQL Server 5.7\bin
右键此电脑 > 属性 > 高级系统设置 > 高级 > 环境变量
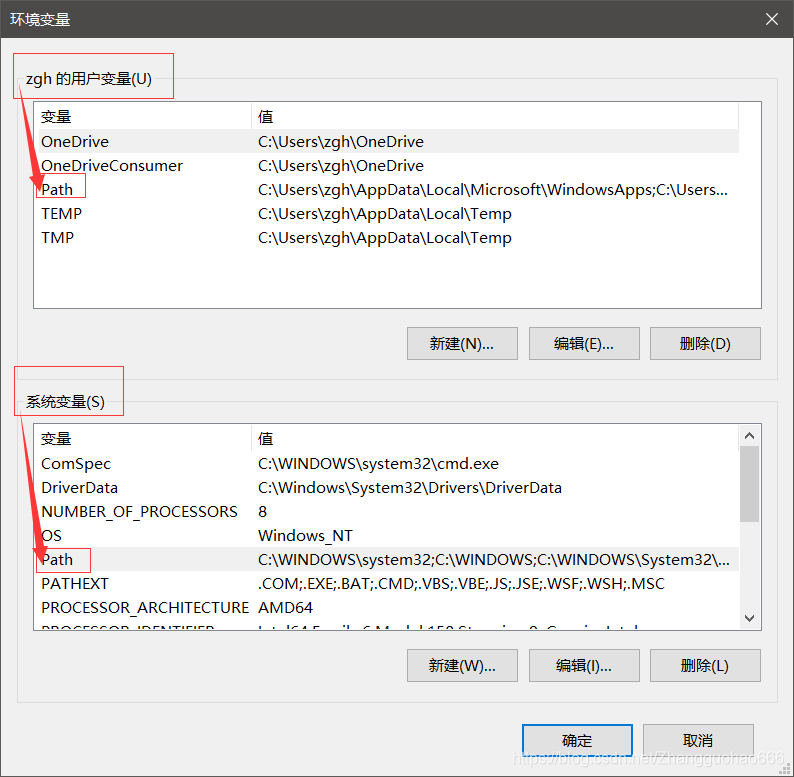
上面的和下面都有一个 path ,这就是需要设置的环境变量了
选中其中一个,点击编辑
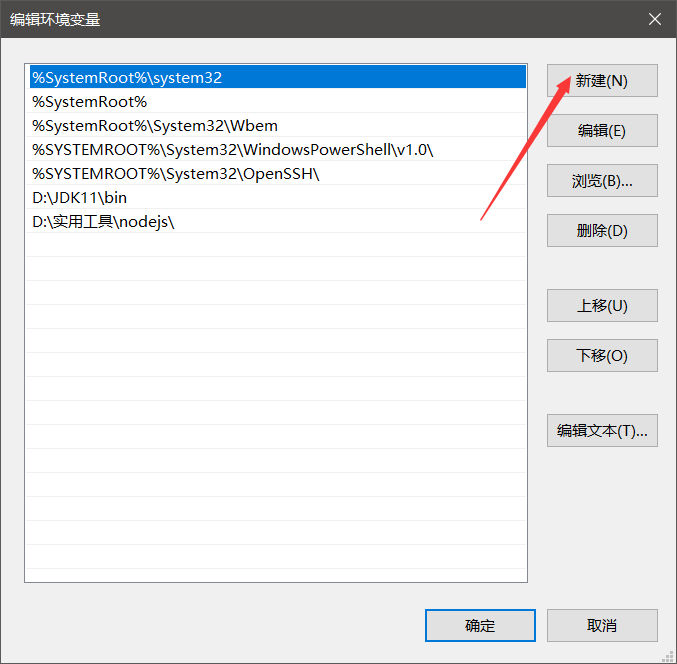
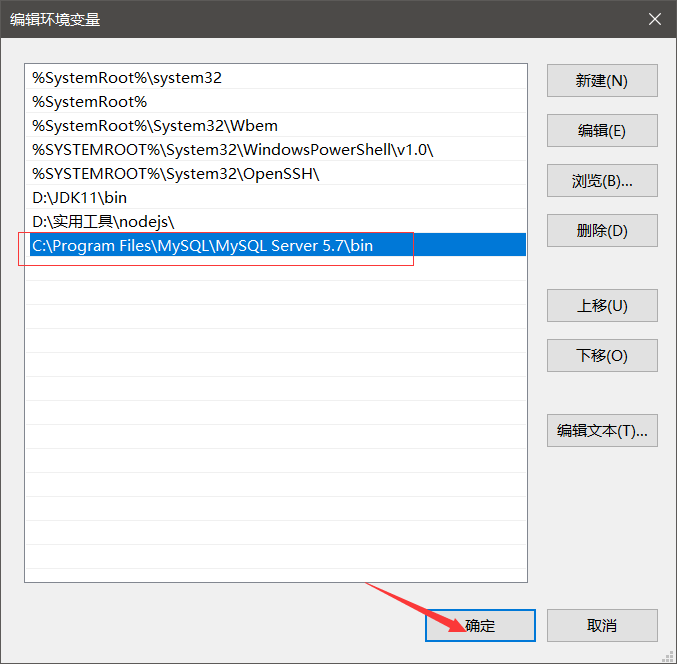
连续点击三次确定!!!直至所有打开的窗口都关闭了
好了,环境变量配置完成
扩展二:Windows中使用cmd或者PowerShell玩MySQL
键盘同时按下 win + r,打开运行窗口,在输入框中输入cmd 或者 PowerShell
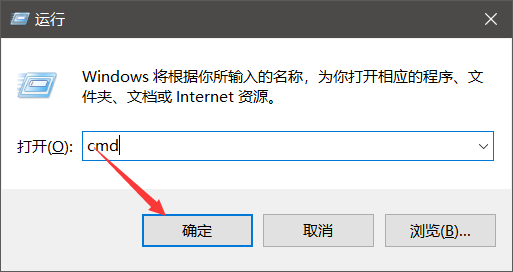
点击确定,windows的控制台就打开了
也是很熟悉的黑框框
在 终端中 进入MySQL
mysql -u 用户名 -p
回车后,发现这和我原来玩的MySQL命令行窗口一样了
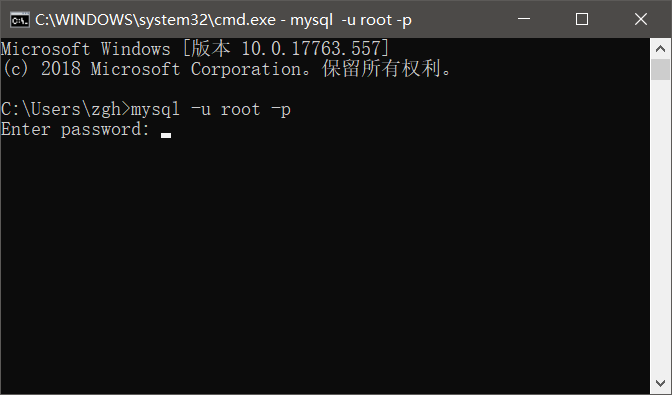
输入密码后,盘符变成了mysql
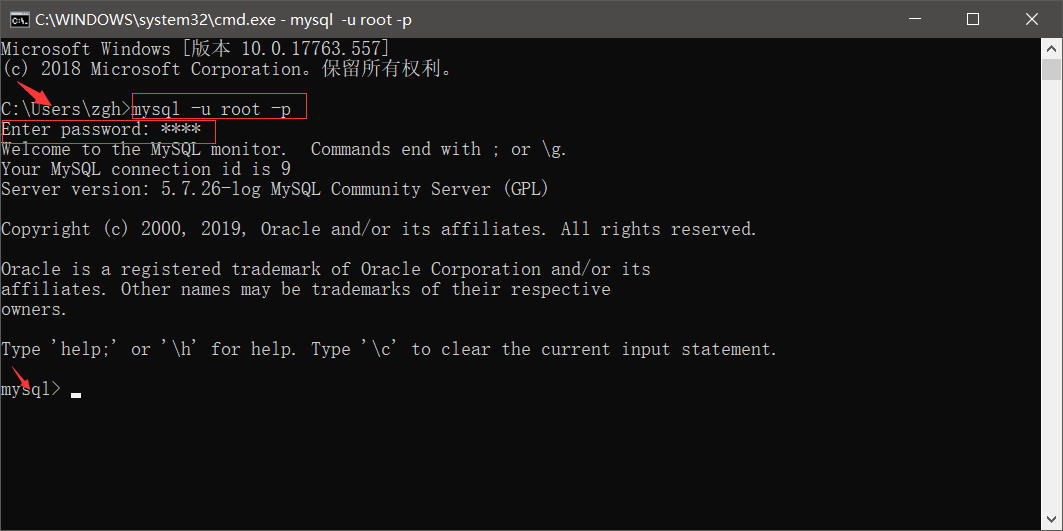
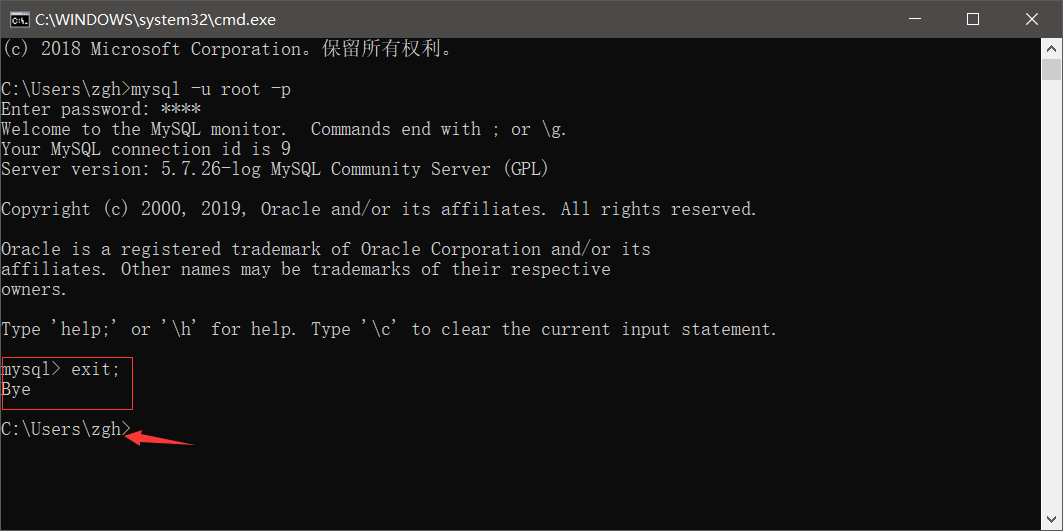
在 终端 中退出MySQL
输入 exit; 或者 键盘同时按下 Ctrl + z ,然后回车
我现在的身份是SYSDBA管理员(即MySQL中的root账号,管理员可以操作其他普通用户的权限)
查看用户信息
先用root账号看一下MySQL中四个默认database
其中mysql数据库中的user表格记录了MySQL的用户信息
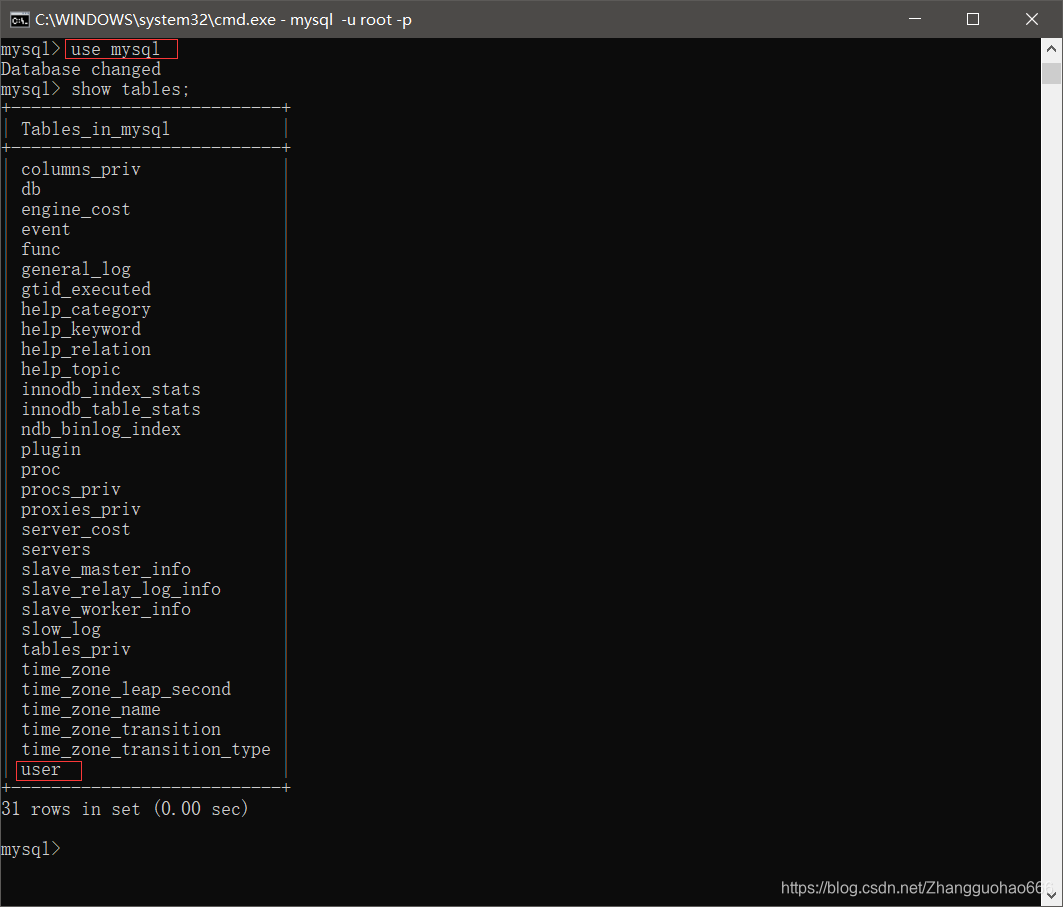
user表格中有很多属性
我们现在只需要查询三个属性
user用户名hostIP地址,默认是localhost,即本机- 在MySQL的5.5版本之前,密码是存储在
password列中;我的版本是5.7,用户密码被md5加密了,放在了另一个列authentication_string列
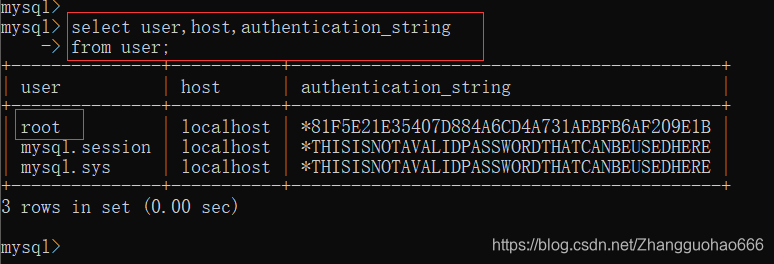
创建新用户
create user '用户名'@'IP' identified by '密码';
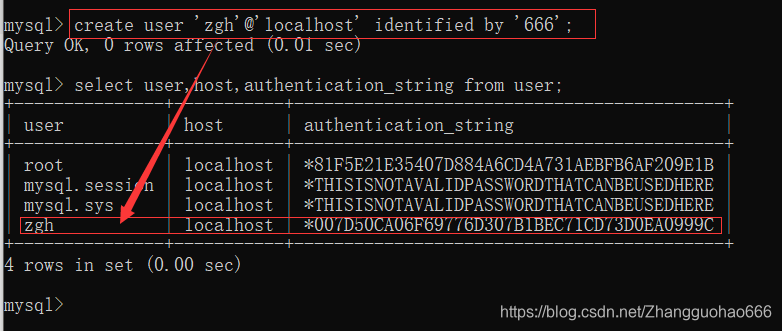
然而一个新创建的用户,只有一个默认的权限usage,只允许登录,不允许做其他事情
控制用户的权限
1. 给新的用户赋予权限
查看用户权限
可以通过一个语句查看用户的权限
show grants for '用户名'@'IP';
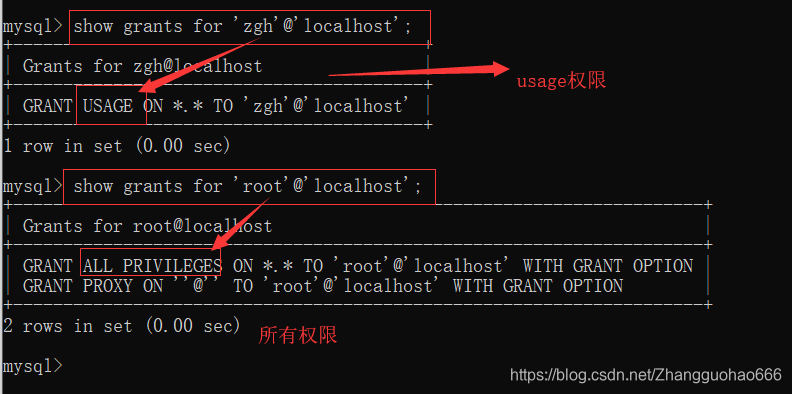
给用户赋予权限
grant 权限 on 数据库.表格 to '用户名'@'IP';

(补充*.*代表所有数据库的所有表格)
赋予权限之后,如果发现没起作用,最好做一个刷新
flush privileges;
2. 注销 用新用户登录
注销
exit;
然后
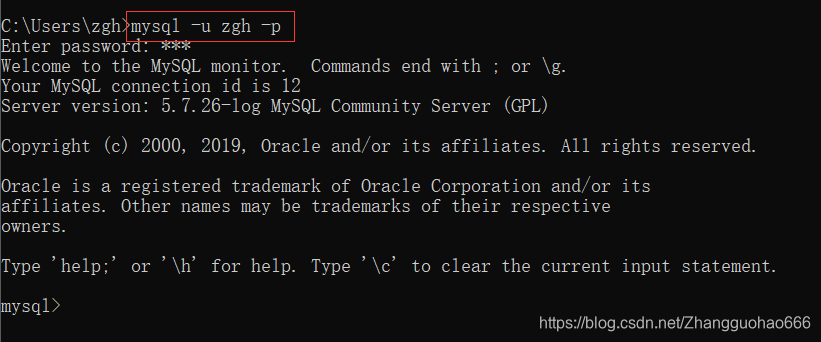
因为zgh用户的权限和root一样
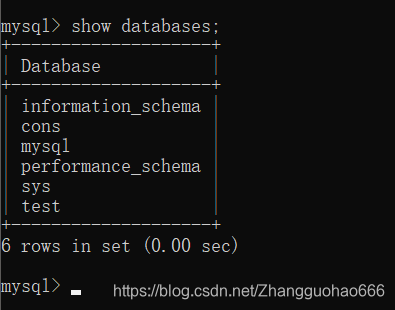
3. 回收用户的权限
revoke 权限 on 数据库.表格 from '用户名'@'IP';
重新用root账号登录,
然后
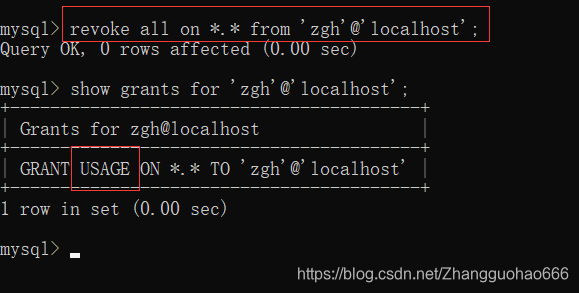
(补充,usage权限是一定会保留的)
再进入zgh账号看一下:
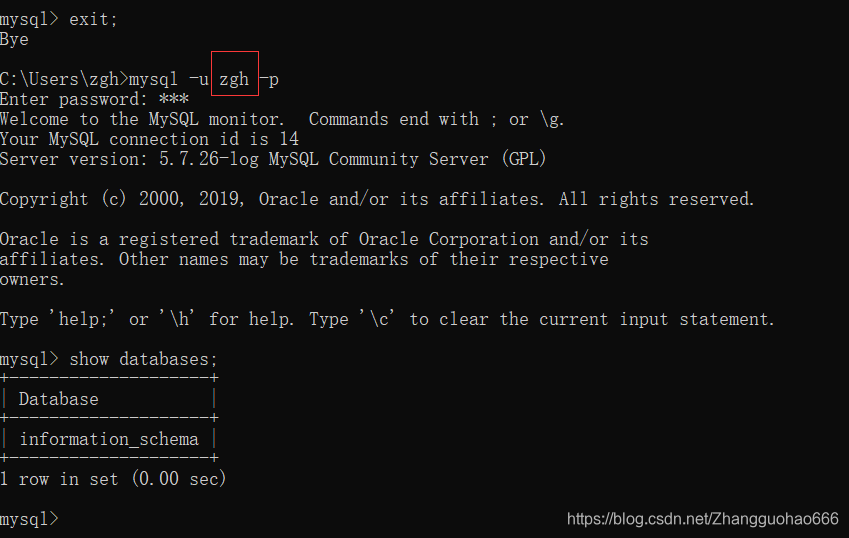
4. 修改用户密码(DML)
update user set authentication_string = password('密码')
where user = '用户名'@'IP';
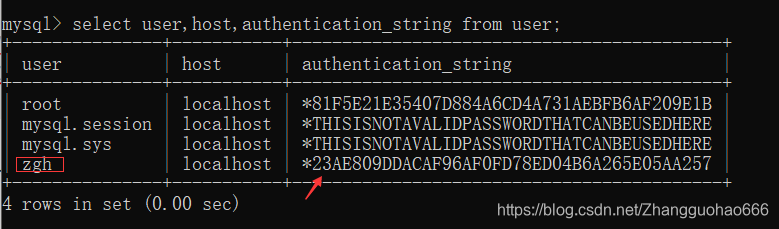
如果尝试重新登录改了密码的用户,发现改了的密码不好用
那就返回root账户刷新一下数据库
flush privileges;
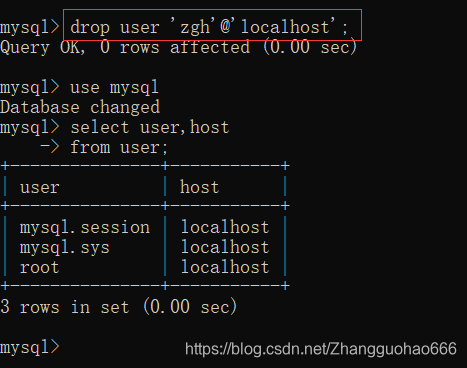
5. 删除创建的用户(DDL)
使用DDL语句删除用户是最好的,因为它删除的更加干净
drop user '用户名'@'IP';
目录五:列的约束
- 主键约束
- 外键约束
- 唯一约束
- 非空约束
- 检查约束
前情提要:
先创建一个数据库cons
(因为数据库名字长度有限制,cons是constraint的缩写)

然后在cons数据库中
创建一张表:
myclass表
create table myclass(
classid int(4),
cname varchar(20),
loc varchar(20)
);
然后设置一下myclass表的字符集
alter table myclass character set utf8;
我先在myclass表中添加一行元素
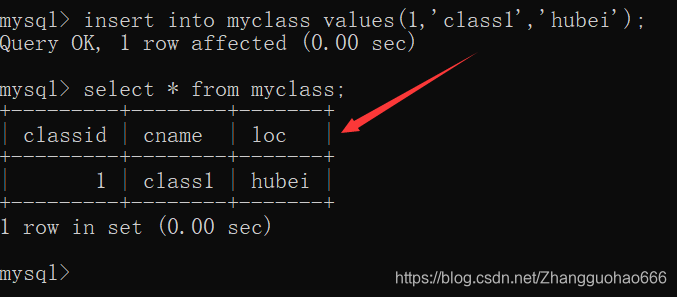
如果我在myclass表中添加一行相同的元素,会有冲突吗?

显然,相同的元素可以添加进去
但是,有时候对于存储的元素是不允许重复的
为了方便下面的学习,我把myclass的元素清空
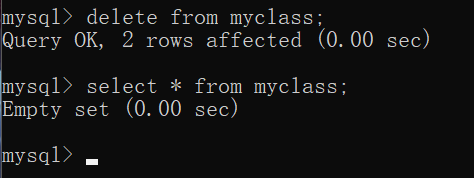
一:主键约束
primary key- 在每一个表格中,只能有一个列被设置为主键约束
- 主键通常用来标记表格中数据的唯一存在
- 主键约束要求当前的列,不能为null值
- 主键约束要求当前的列,值是唯一存在的,不能重复
添加约束,到底是改变表结构还是操作数据呢?
很显然,添加约束时,表中是没有元素的
所以要用DDL语句
添加主键约束的标准写法
alter table 表名 add constraint 约束名字 约束类型(列);

查看表的约束
然后,怎么查看表是否有约束呢?
有两个办法:
第一个办法:
desc 表名;
desc是description的缩写
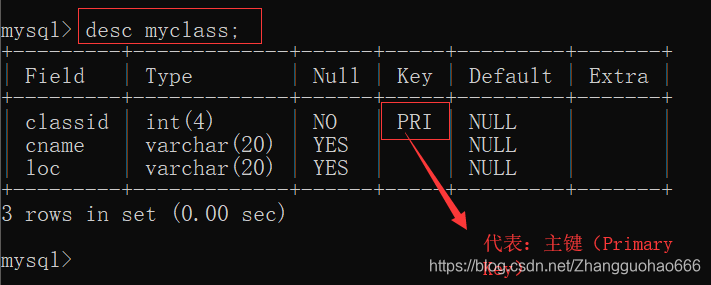
第二个办法:
show keys from 表名;

添加主键约束的简写
可以看出,两种查看约束的方式都与约束名无关
所以添加约束的语句可以简写为:
alter table 表名 add 约束类型(列);
主键的自增操作
添加主键之后,若想要主键自增,可以做相应的设计
alter table 表名 modify 列名 类型(长度) autu_increment;
或者
alter table 表名 change 原列名 新列名 类型(长度) autu_increment;
change和modify两个关键字的不同在于,change关键字还可以更改列名
这个语句,没有做起始值的说明,主键列会从1开始
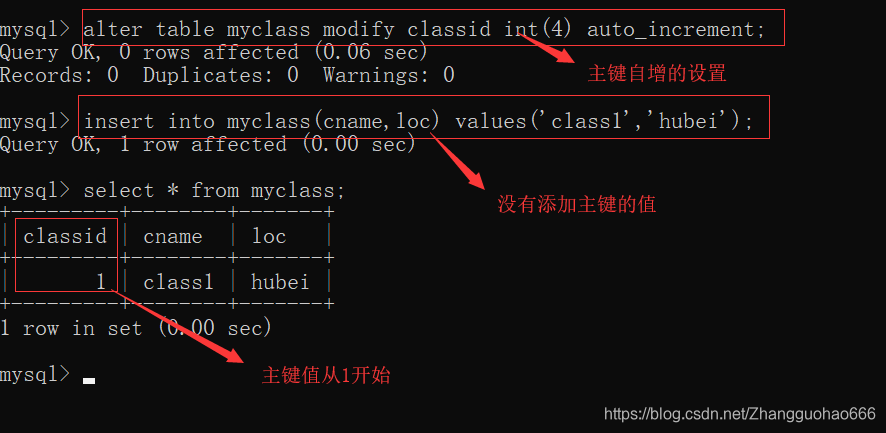
再加一条记录:
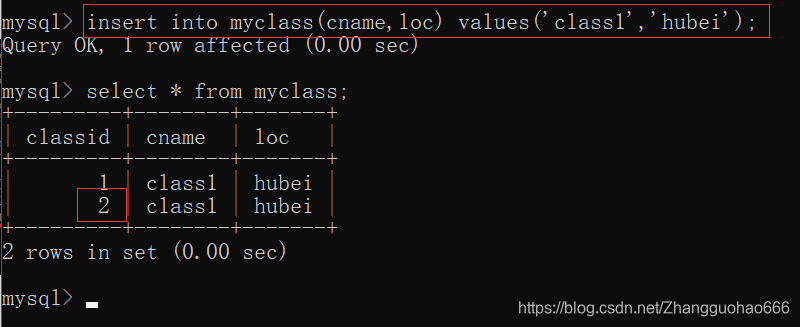
设置主键自增的起始值:
alter table 表名 auto_increment = 起始值;
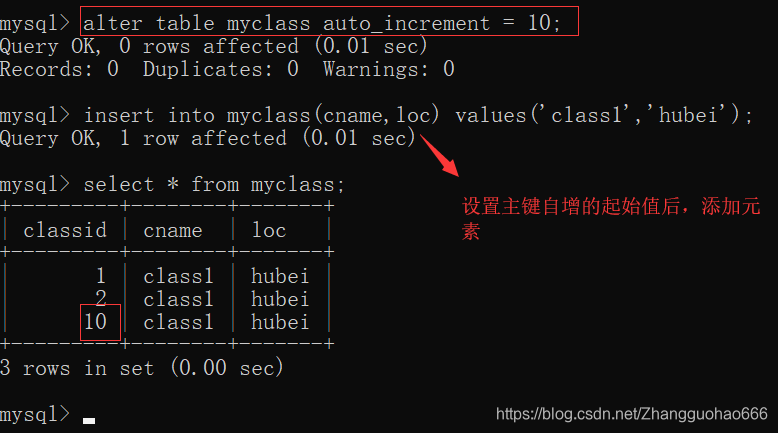
去掉主键自增:
重新设置一下列就好:
删除主键约束
删除主键:
alter table 表名 drop primary key;
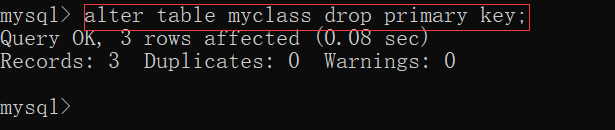
删除主键约束后,有一个小细节要注意一下:
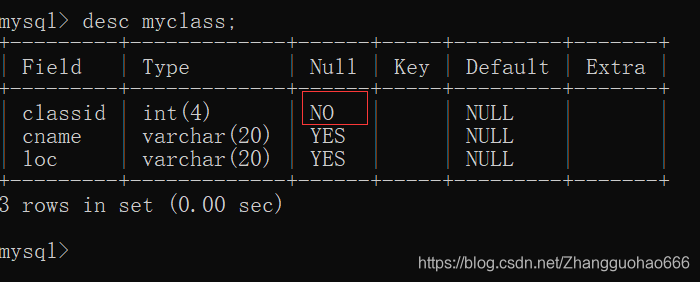
删除主键约束后,不重复的特性取消了,但是非空特性还在
所以,在删除主键约束后,还要非空特性改回去:
alter table 表名 modify 列名 类型(长度) null;
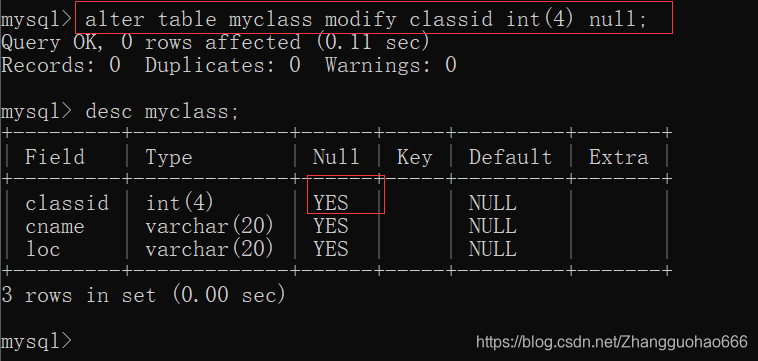
二:唯一约束
unique key,key可以不写- 可以为表格中的某一个列添加唯一约束
- 唯一约束表示的是列的值,不能重复,但是可以为空
- 在表格中可以有多个列存在唯一约束
先把myclass表清空
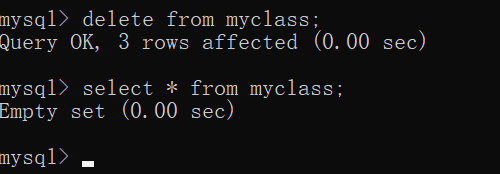
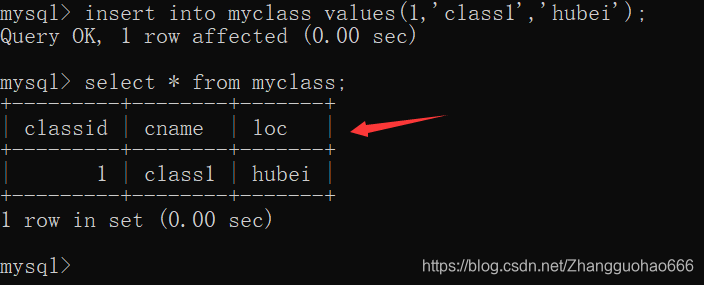
先在myclass表中添加一行元素
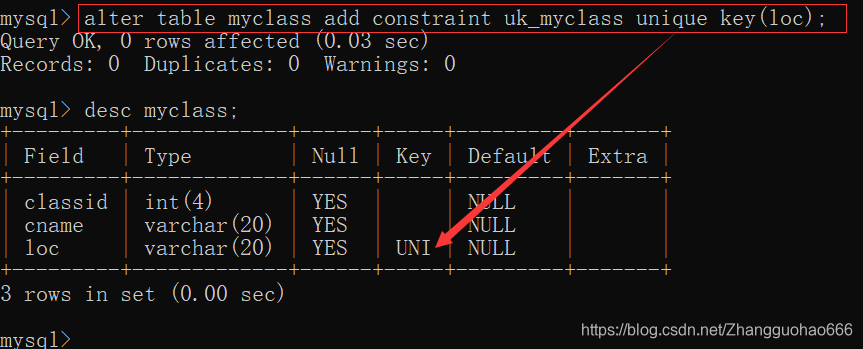
添加唯一约束的标准约束
然后给myclass表的loc属性添加唯一约束
例如:
标准的:
alter table myclass add constraint uk_myclass unique key(loc);
简写的:
alter table myclass add unique key(loc);
//约束名是默认的列名
唯一约束不止一个,需要起约束名,方便通过约束名删除唯一约束
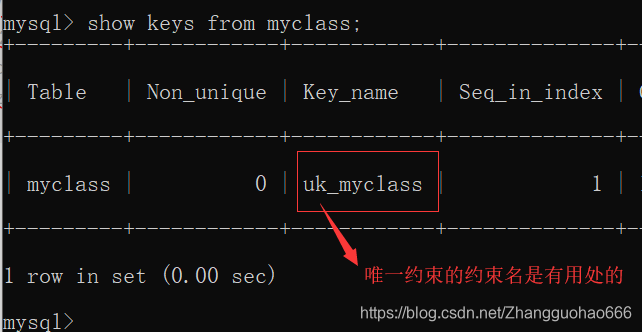
删除唯一约束
写法有一些特殊:
alter table myclass drop index 约束名;

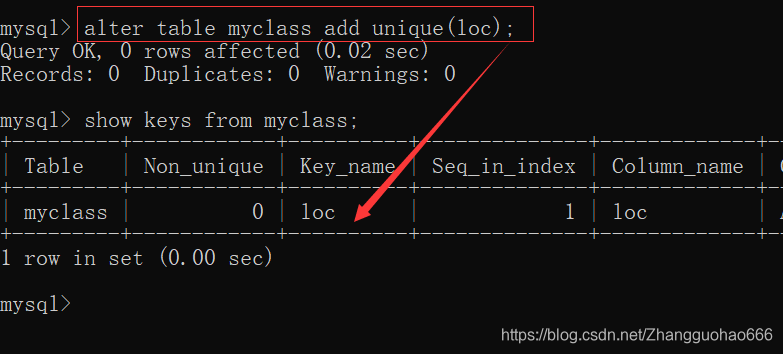
添加唯一约束的简写
alter table myclass add unique key(loc);
//约束名是默认的列名
三:非空约束
- 在表格的某一个列上添加非空元素
- 当前的列的值不能为null
先把myclass表中的唯一约束删掉
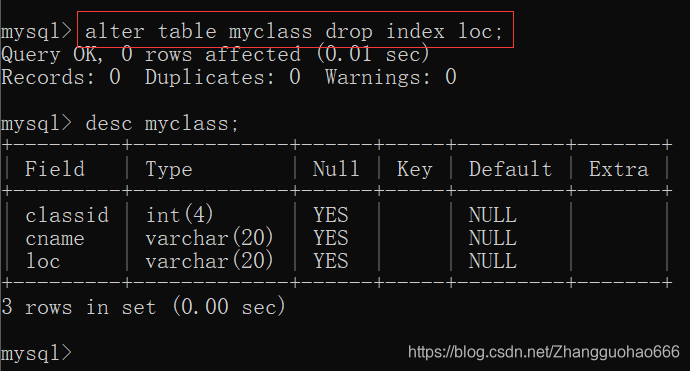
设置非空约束
非空约束,要通过modify或者change来改变表的结构
alter table 表名 modify 列名 类型(长度) not null;
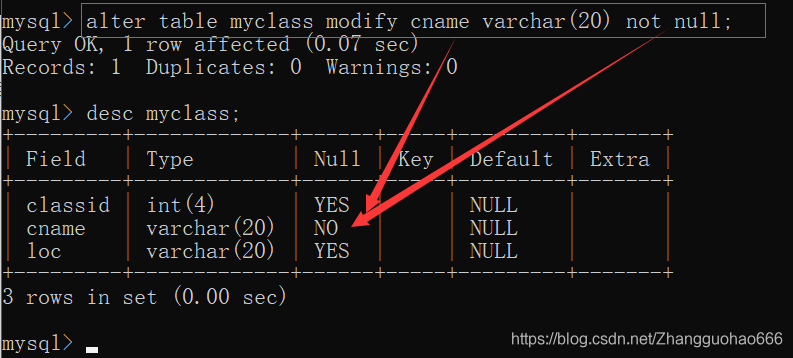
去掉非空约束
alter table 表名 modify 列名 类型(长度) null;
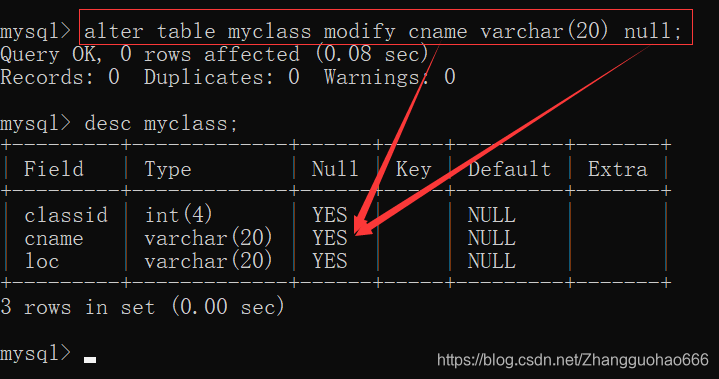
设置非空约束的另一种写法:
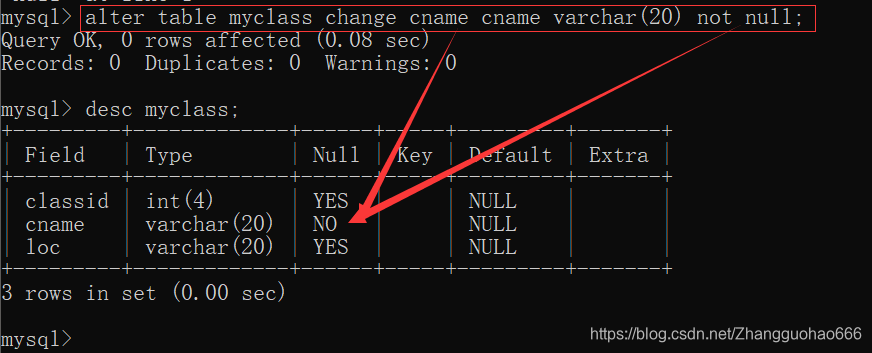
alter table 表名 change 原列名 新列名 类型(长度) not null;
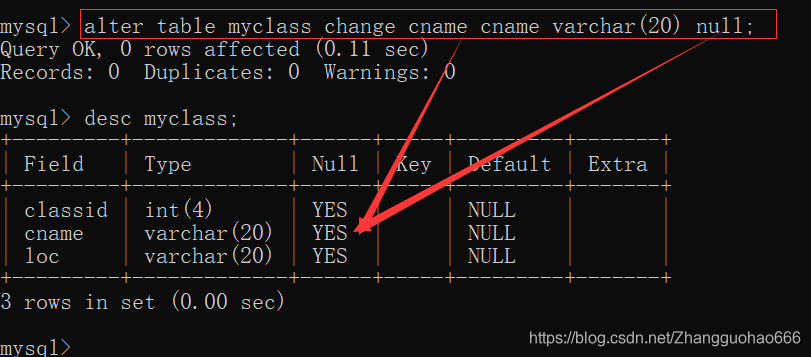
删除非空约束的另一种写法:
alter table 表名 change 原列名 新列名 类型(长度) null;
四:默认值
当myclass表的cname属性有非空约束,假如在开发中某一时间不知道填写什么
可以使用default关键字来避免这个问题
如果你不填写,就是这个默认值

然后我在myclass表中添加一行元素:
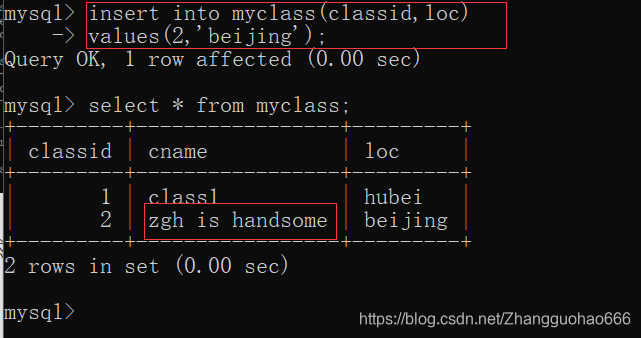
五:外键约束
foreign key- 表格中可以有多个列被设置为外键约束
- 当前列的值可以为空,可以重复
- 当前列的值不能随便填写,值要去另一张表格中寻找
- 外键是当前列的值受另外一张表格某一个列的影响
- 另外一张表的列的值是唯一的(唯一约束或主键约束)
表之间的关联,玩的就是外键约束
玩外键约束之前,先创建一个表格student
create table student(
sid int(4),
sname varchar(20),
ssex varchar(10),
classid int(4)
);
alter table student character set utf8;
然后在student表格中添加元素
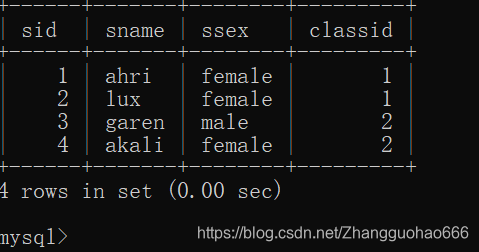
insert into student values(1,'ahri','female',1);
insert into student values(2,'lux','female',1);
insert into student values(3,'garen','male',2);
insert into student values(4,'akali','female',2);
student表:
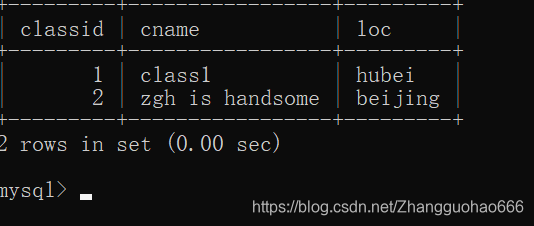
还要涉及另外一张表myclass:
添加外键约束的标准写法
alter table 表名字 add constraint fk_当前表_关联表 foreign key(列) references 另一个表(列);
不过在添加外键约束时,要先使另一张表的列的值是唯一的(非空约束,主键约束)
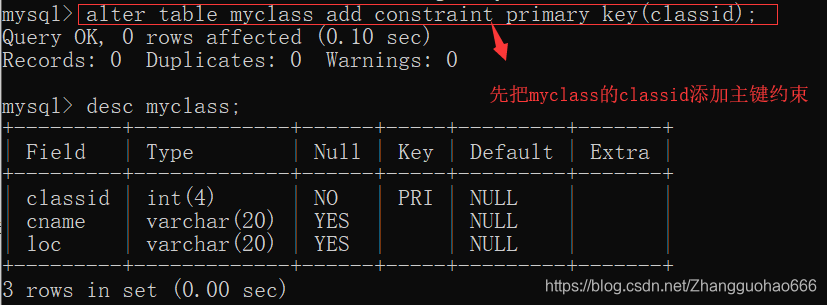
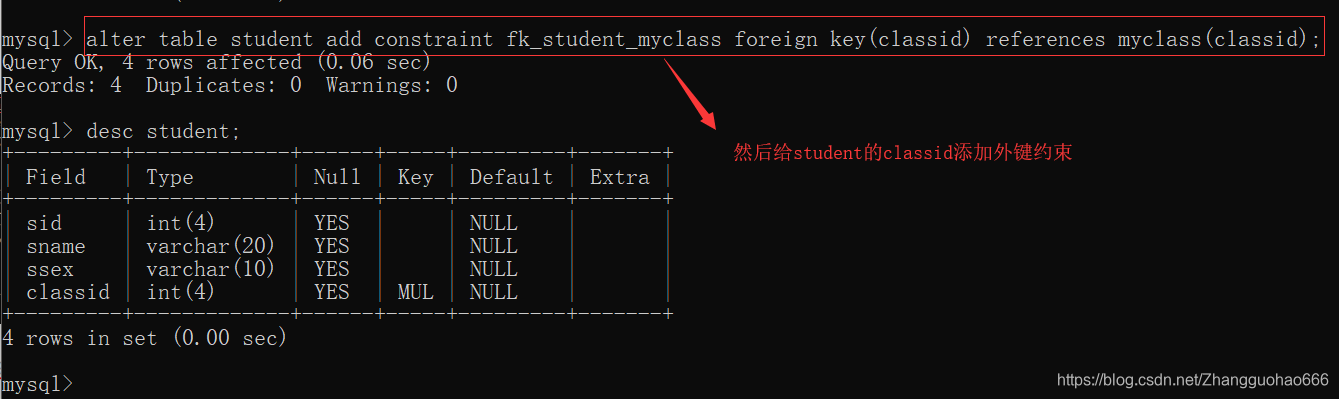
MUL指的是multiple(多样,并联)
删除外键约束
alter table 表名字 drop foreign key 约束名字;
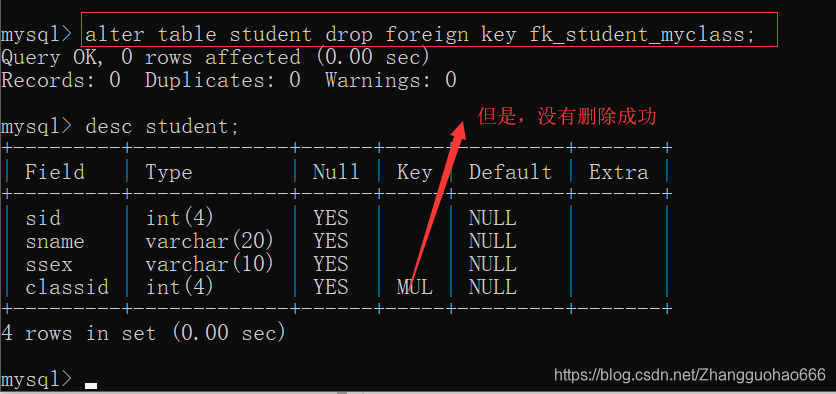
注意:通过上述语句其实已经将这张表格的外键约束删掉了
但是,外键约束涉及到两张表格,为了保证另外一张表的记录不丢失,会自动在当前的表格内添加一个新的key
show create table 表名;
//这个语句可以看key
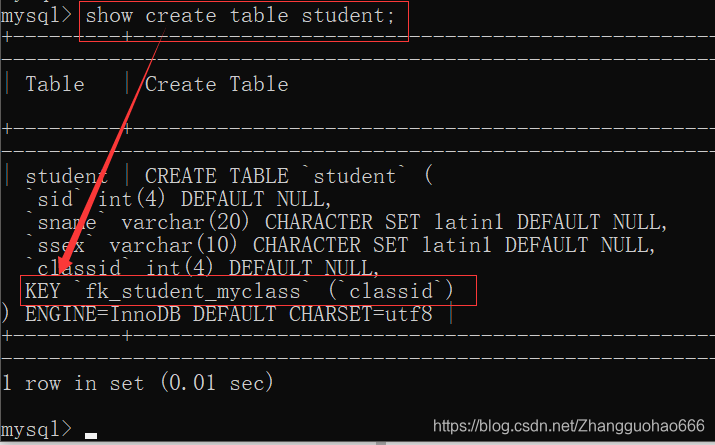
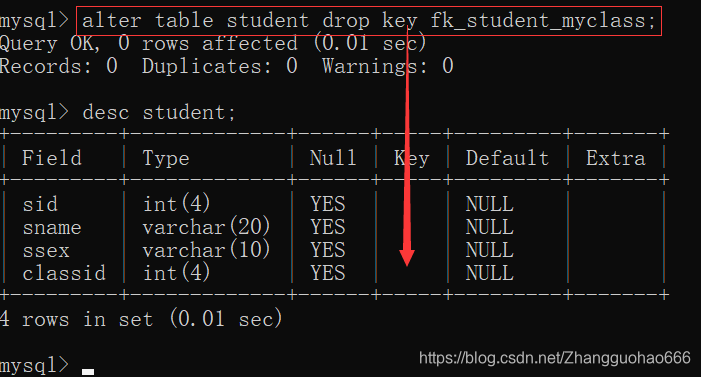
我们需要再次手动将这个生成的key删掉,外键约束才真的删干净
alter table 表名 drop key 外键约束名;
添加外键约束的简写
alter table 表名字 add foreign key(列) references 另一个表(列);
那么,外键约束名是什么呢?
只能以通过show create table 表名;查的外键约束名为准(不是默认的列名!)
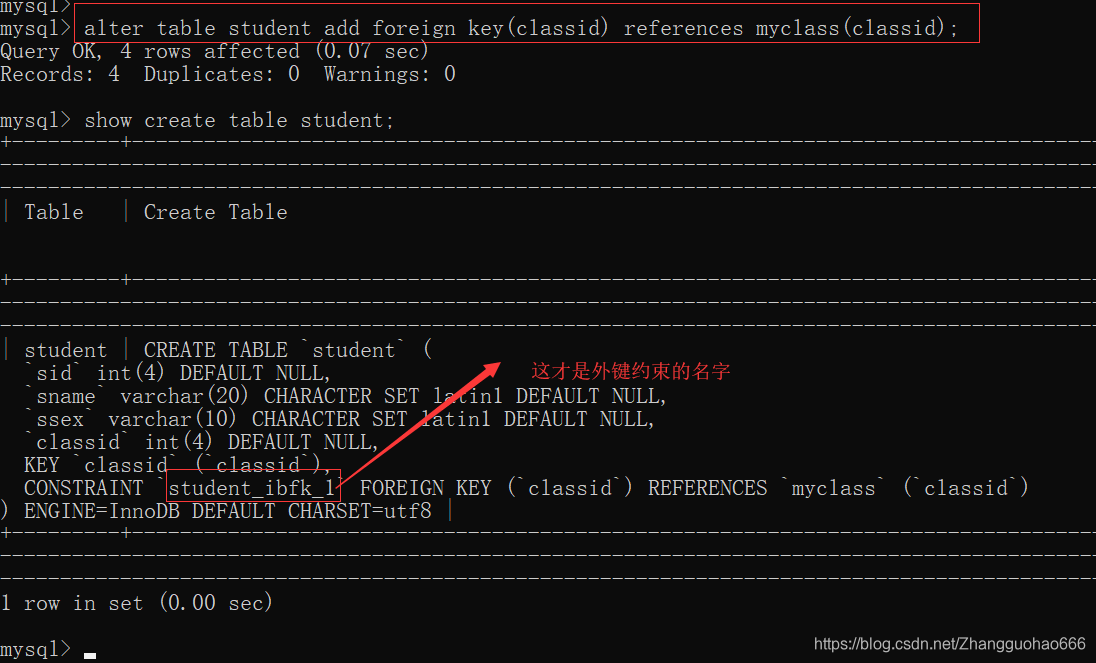
所以简写的方式,使删掉外键时挺麻烦的(尽量不要这么使用)

但是key的名字确是默认的列名

六:检查约束
- 列在存值的时候做一个细致的检查,值的范围是否合理
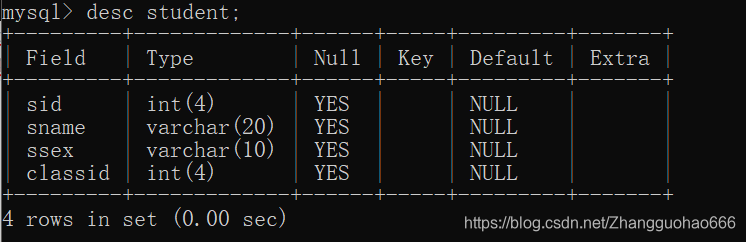
首先,看一下student表的结构:
然后,我添加一个属性
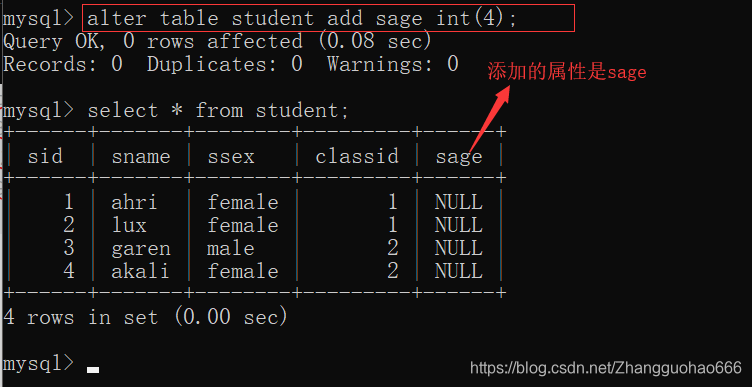
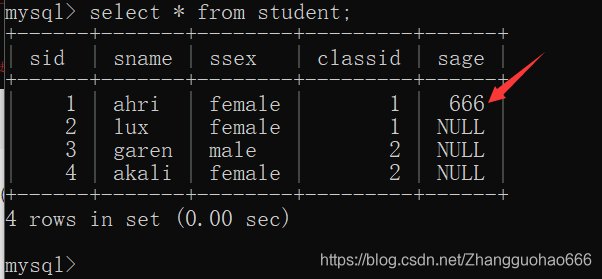
现在,我要对sage的值进行更新(但是更新的值要合理,就可以用检查约束来保证数据的合理性)
添加检查约束
alter table 表名 add constraint 约束名 check(值的范围);

然后发现检查约束的语句执行了,但是在MySQL中不好使(被MySQL的底层屏蔽了)
不过检查约束,在Oracle数据库中是好使的
目录六: 关键字:any,some ,all ,union,union all
学习这几个关键字之前的准备
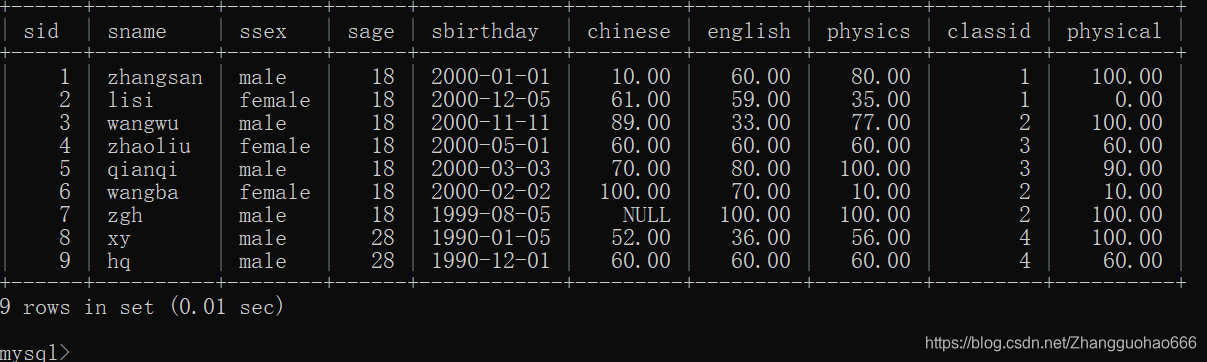
student表
再创建一个myclass表
create table myclass(
classid int(3),
classname varchar(20),
classloc varchar(20)
);
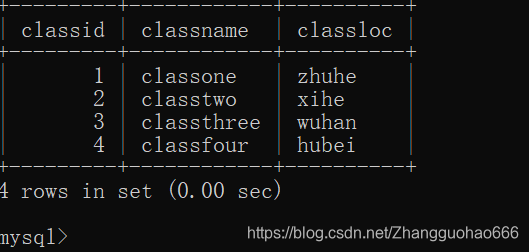
在myclass表中插入元素
insert into myclass values(1,'classone','zhuhe');
insert into myclass values(2,'classtwo','xihe');
insert into myclass values(3,'classthree','wuhan');
insert into myclass values(4,'classfour','hubei');
myclass表:
- 先说一下
in关键字
满足查询子集中的一个即可
in 后面跟的语句可以是常量固定值,也可以是嵌套查询 - 如下三个关键字
any,some,all使用起来与in类似,查询是否满足后面的子集中的条件
但是这三个关键字的后面只能跟嵌套查询,而且要配合运算符来使用
一:any,some
any和some的用法完全一样
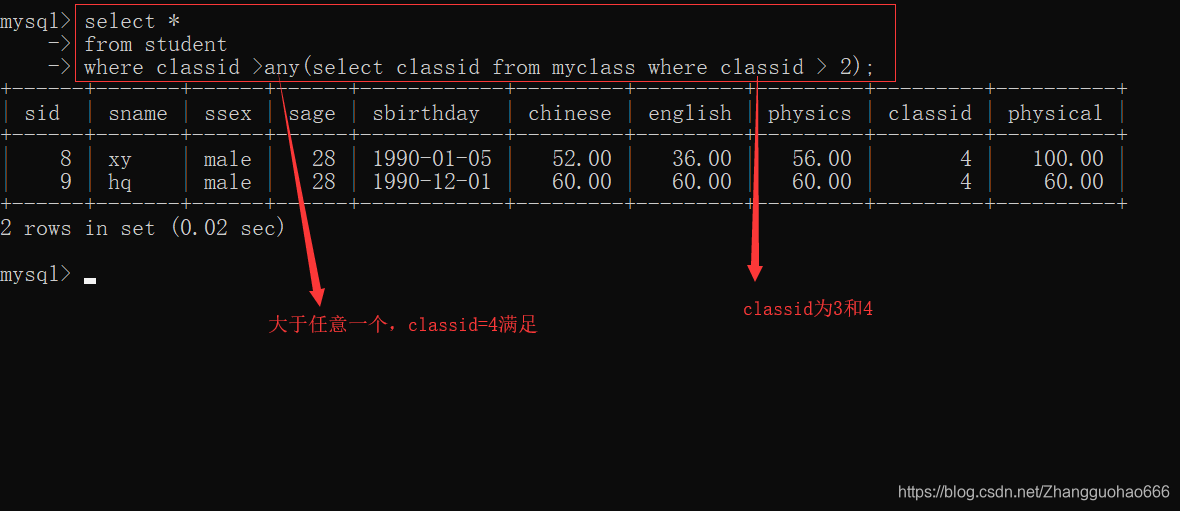
>any
大于最小值
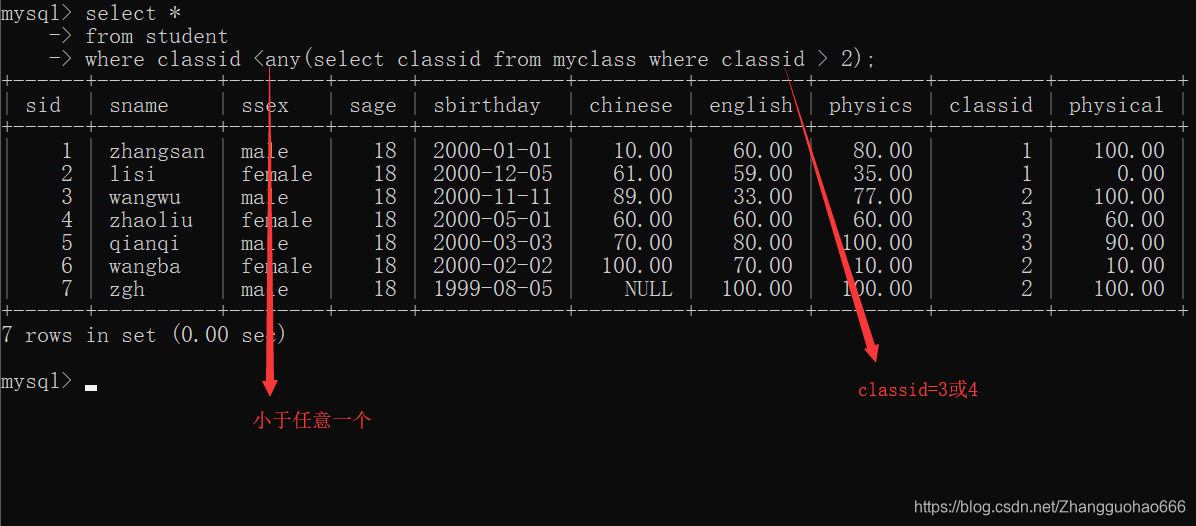
<any
小于最大值
=any
等价于in关键字
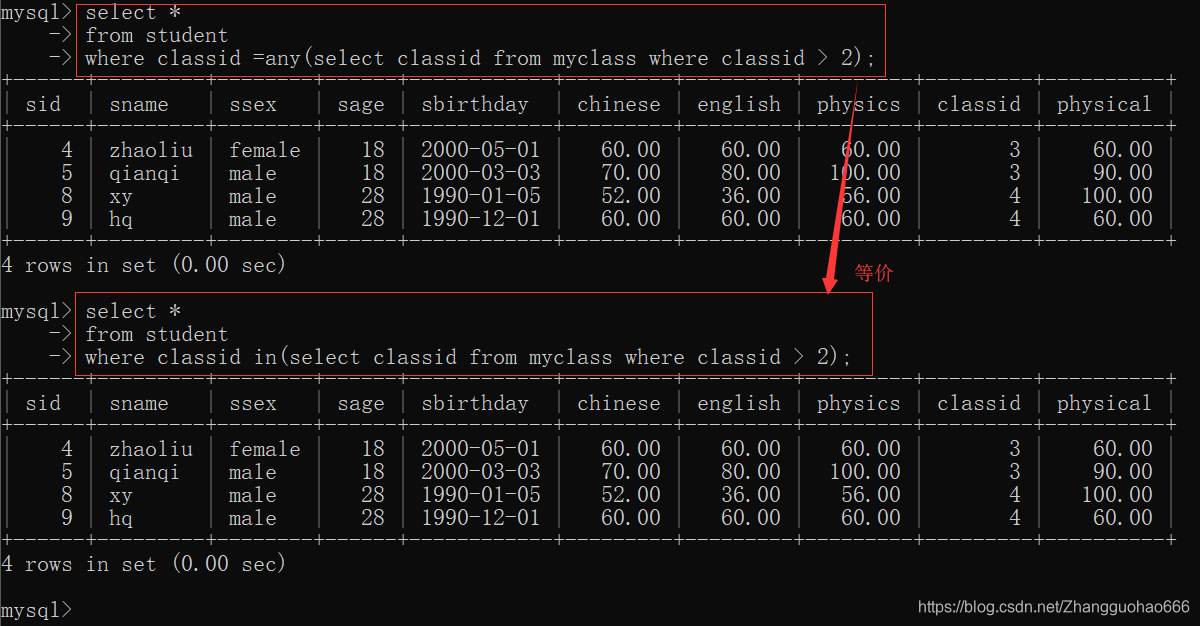
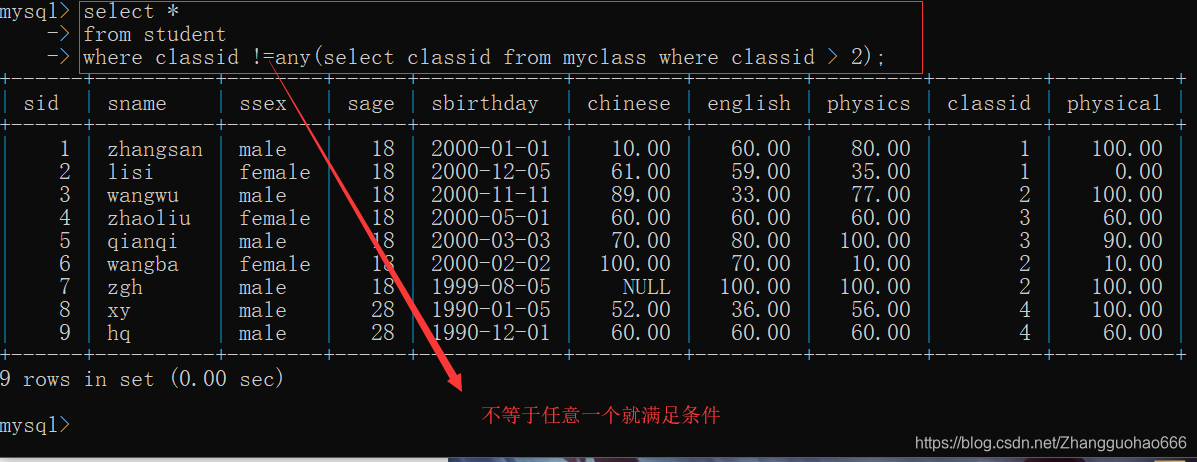
!=any
二:all
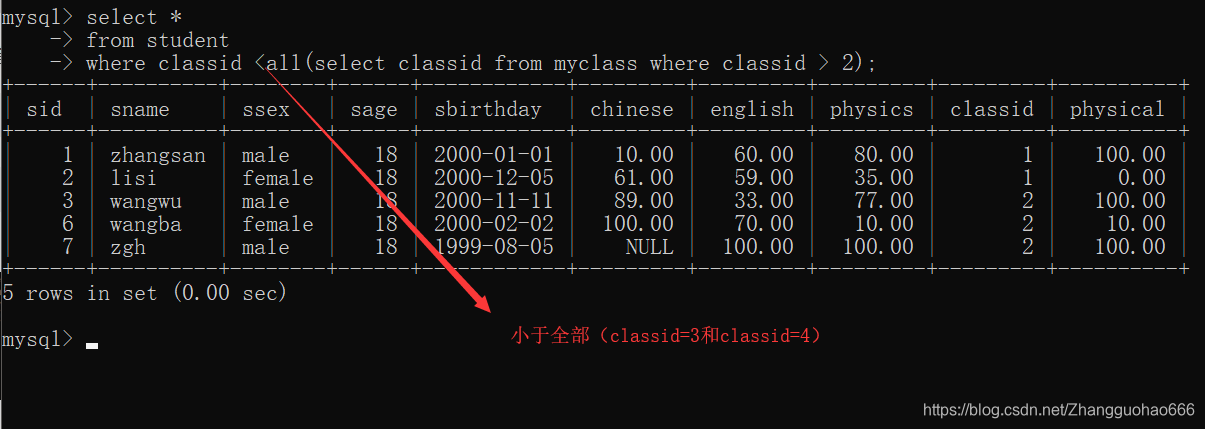
all满足查询子集的全部才可以
<all
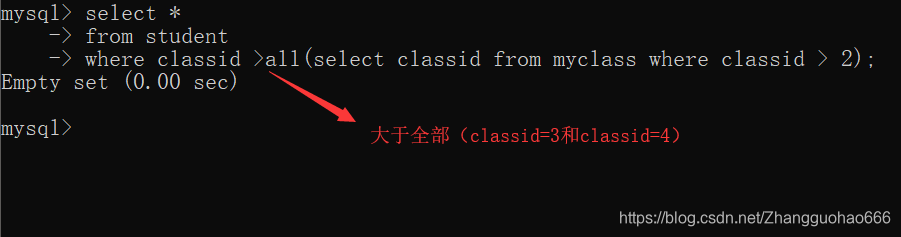
>all
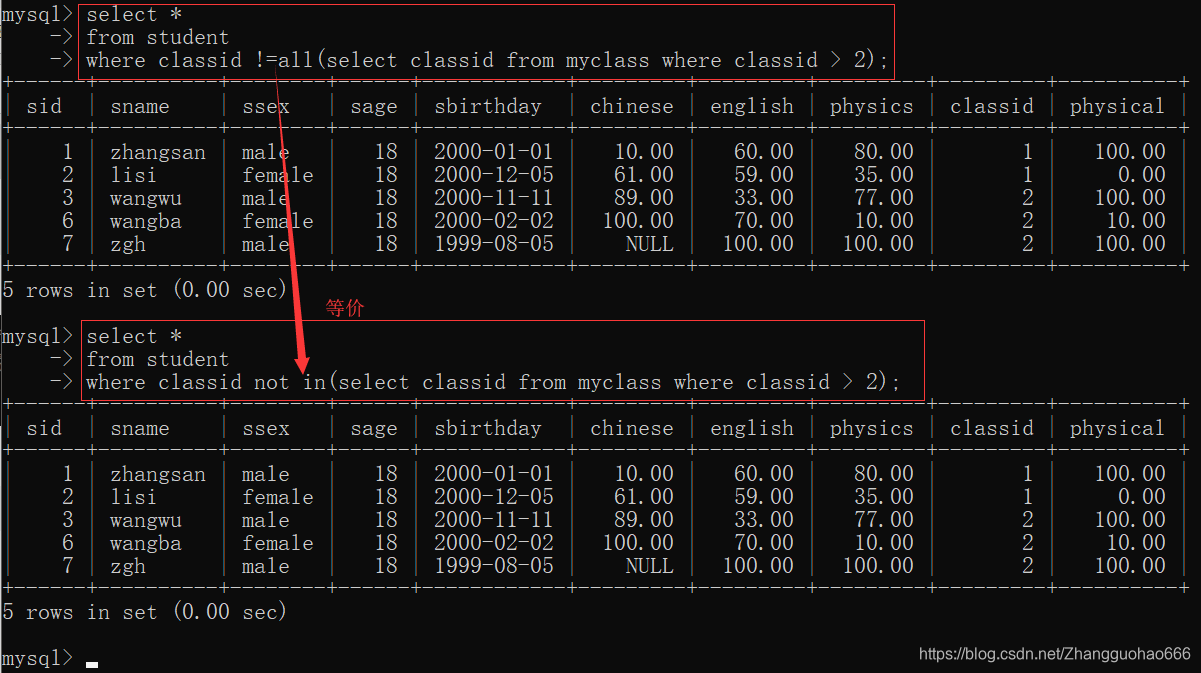
=all
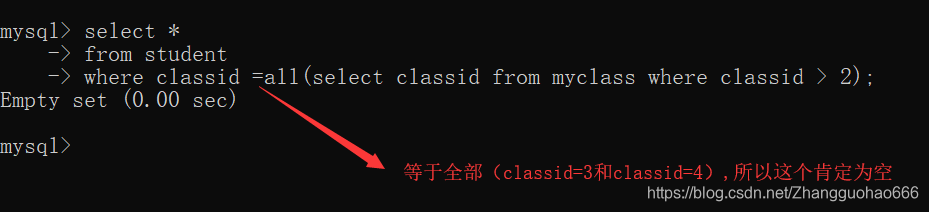
!=all
和not in关键字等价
三:union,union all
对集合的操作有:
- 并集
union - 交集(Oracle数据库有这个语句
intersect) - 差集(Oracle数据库有这个语句
minus)
并集union,将两个表合并在一起
有两个表,
student

teacher
create table teacher(
tid int(4),
tname varchar(20),
tsex varchar(10),
tbirthday date
);
insert into teacher values(1,'zgh1','male','1999-08-05');
insert into teacher values(2,'zgh2','male','1998-08-17');
insert into teacher values(3,'zgh3','male','1998-08-16');
并集的语句是这么写的,举个例子:
select sid,sname,ssex from student union select tid,tname,tsex from teacher;
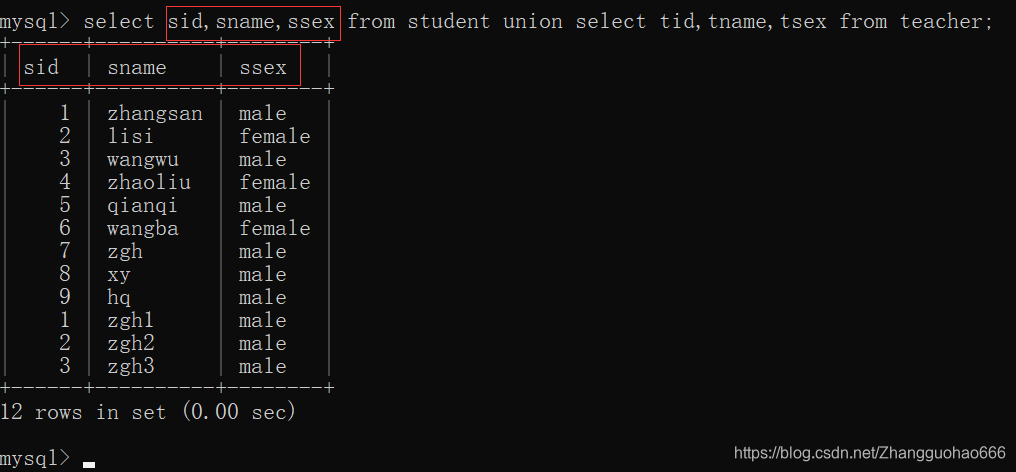
把两张表的写的顺序调换一下:
select tid,tname,tsex from teacher union select sid,sname,ssex from student;
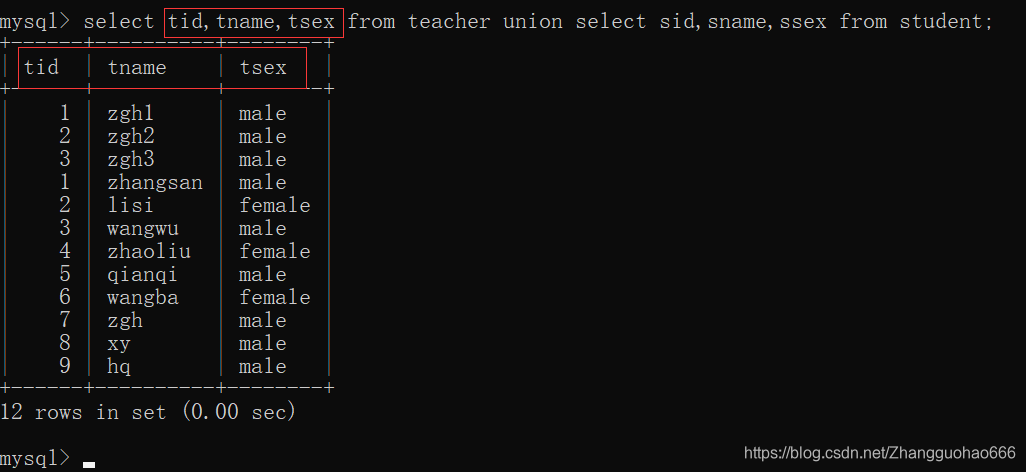
很显然,并集后的表的列名取决于语句中写的前一张表,当然,也可以取别名
合并的要求:
- 要求前后两个查询子集的列数是一致的
- 拼接后显示的列名是前一个子集默认的列名
- 类型和长度是没有要求的,可以不一样
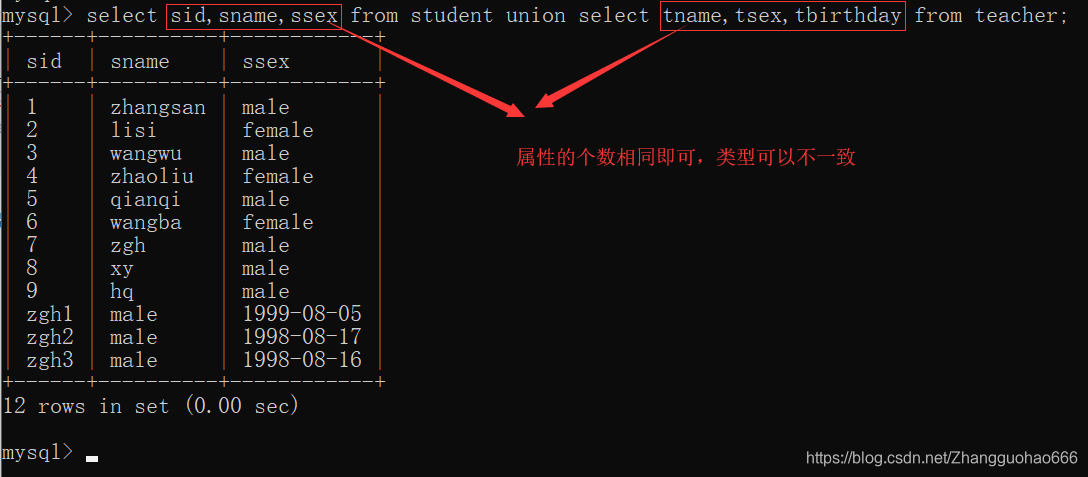
- 注意
union和union all的区别:对于重复元素的处理
我再创建一个新的newteacher表格
create table newteacher as select * from teacher;
//这个语句可以通过后面一张表创建一个完全一样的表格
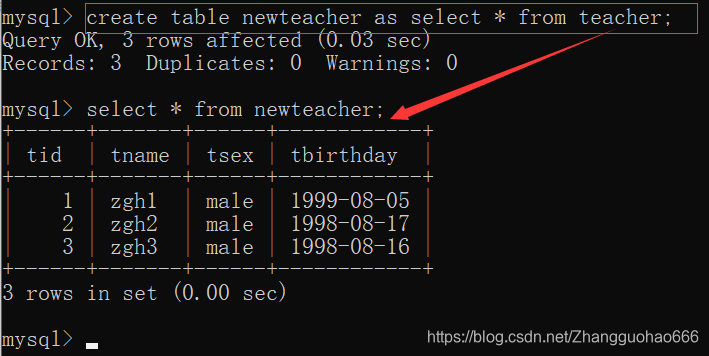
再对newteacher表个中的数据改动两行,保留一行和teacher表中一样的元素
update newteacher set tid = 10 where tname = 'zgh2';
update newteacher set tid = 11 where tname = 'zgh3';
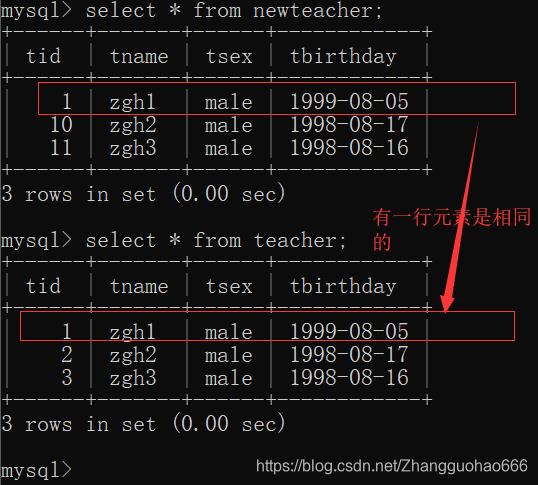
union会在拼接的时候,又做一个处理,看一看有没有重复,有就把重复的元素拒绝加入(所以性能较慢)
而union all将两张查询的子集直接合并,不做任何处理,性能比较快
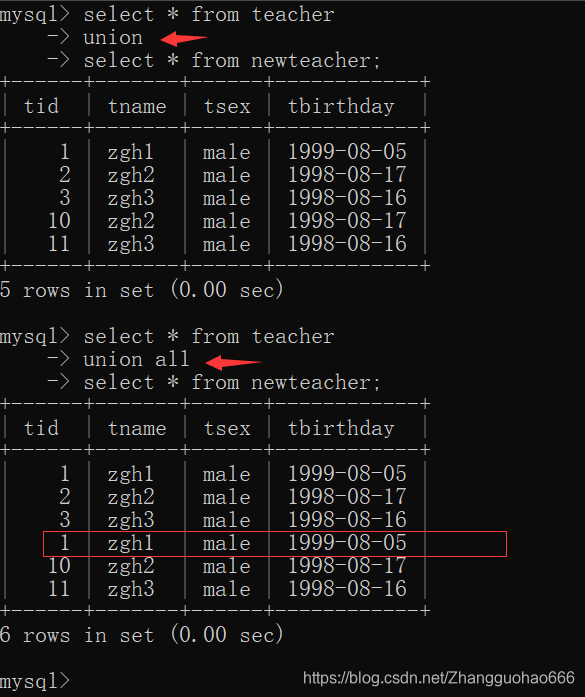
当数据没有重复时,建议用union all来进行合并处理
目录七: 函数的使用
用student表来学习函数的使用
函数直接放置在语句中,
可以放置在:
select 函数(列)
from 表格
where 函数(值) > 值
按照函数功能进行划分
- 比较函数
- 数学函数(数值函数)
abs(值)绝对值
floor(值)向下取整
mod(值,值)取余数
pow(值,值)求次方
round(值)四舍五入 - 日期和时间
now()
year(date)
mouth(date)
day(date)
week(date) - 控制流程函数(转换函数)
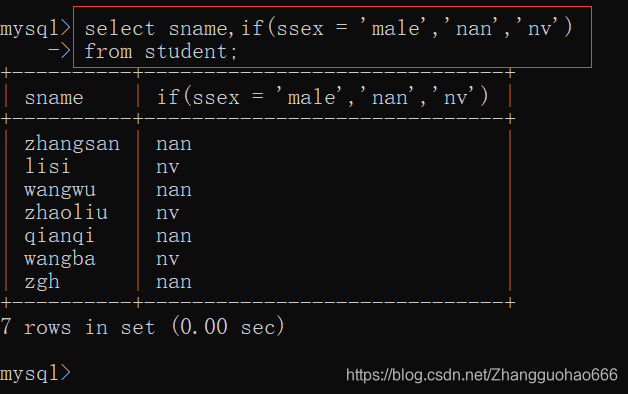
if(expr1,expr2,expr3)三目运算符
ifnull(值,v)是空值显示v,如果非空就正常显示 - 字符串函数
大部分和java中的String类的方法差不多 - 分组函数(聚合函数)
最最最重要的
常用函数:
一:日期和时间函数
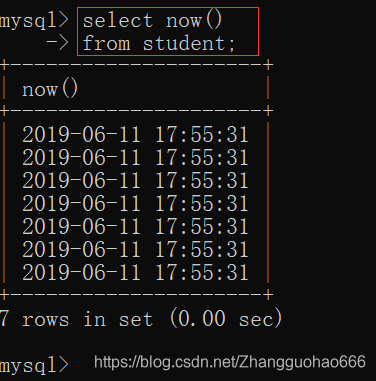
为什么会出现7个记录,因为student表格有七列
SQL有一个关键字distinct可以去重复
(注意,distinct修饰的是每一行记录的全部选择的属性(列))
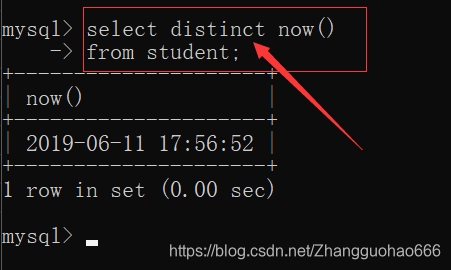
然后MySQL中有一个独有的写法,可以这样写:
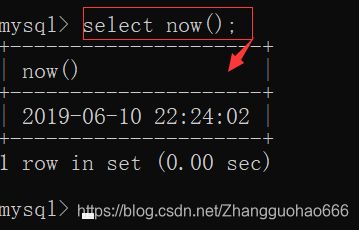
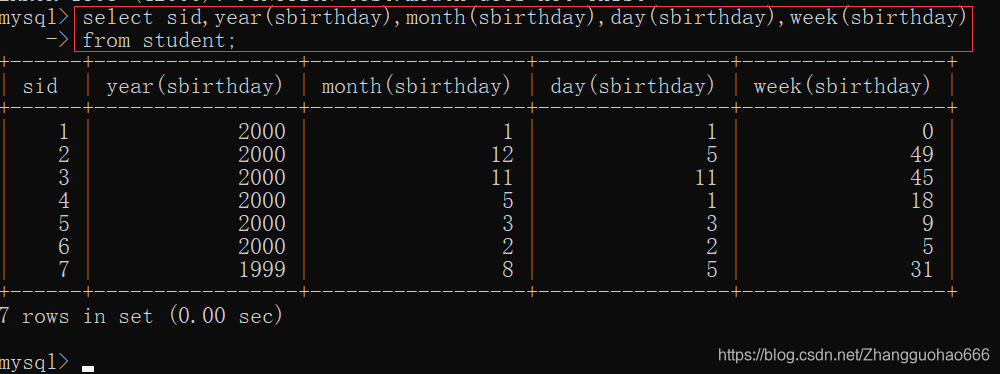
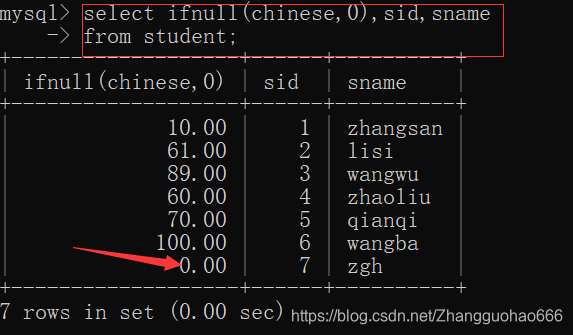
二:流程控制函数
if(expr1,expr2,expr3)三目运算符
ifnull(值,v)是空值显示v,如果非空就正常显示
先把student表中的某行的某个值修改为null
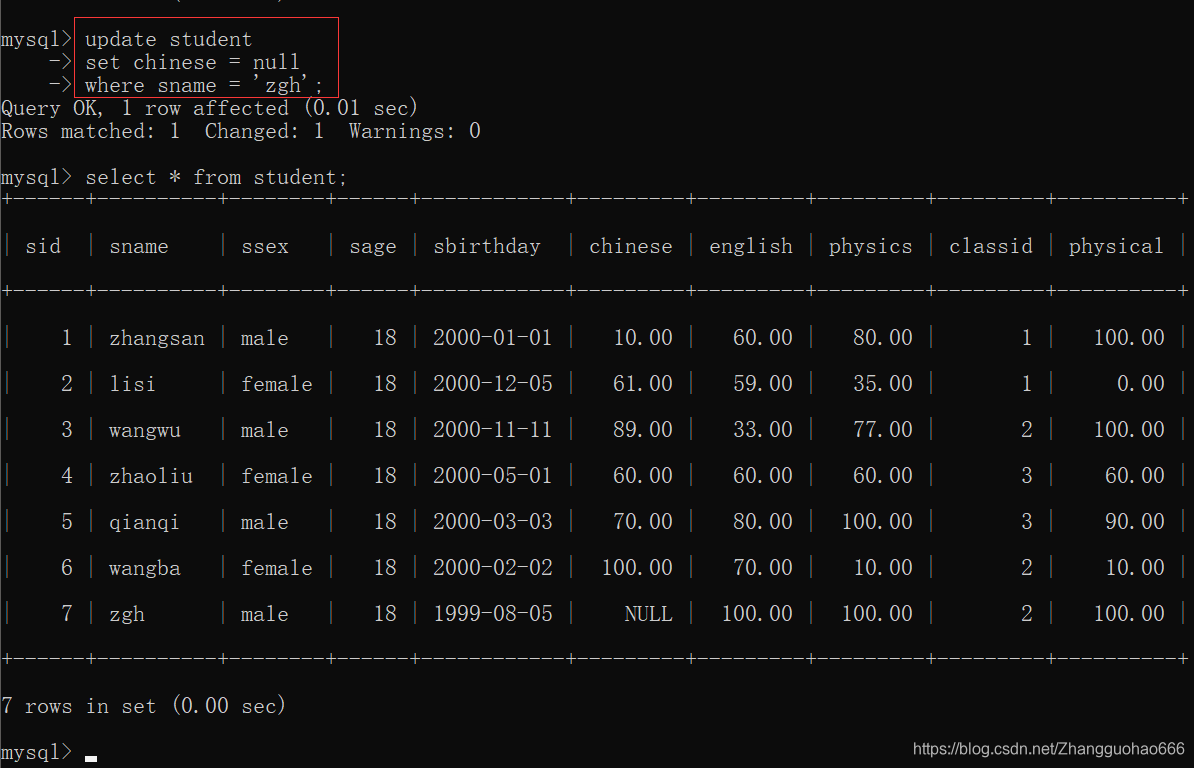
然后:
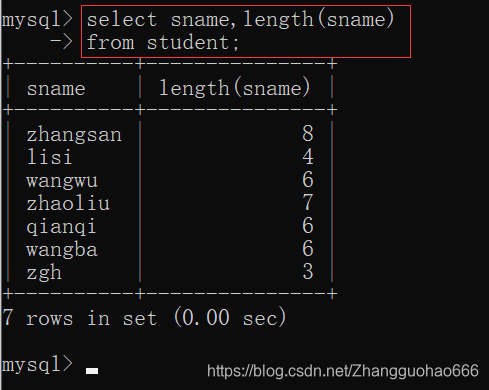
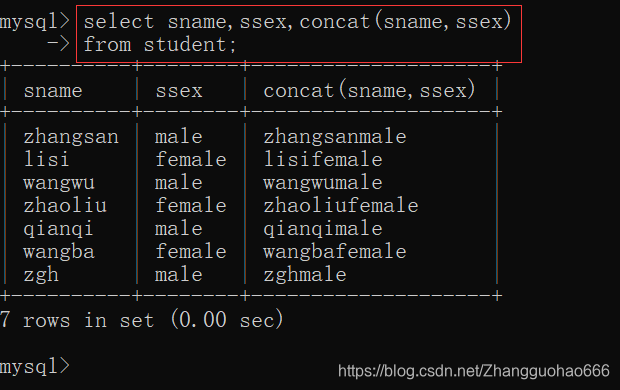
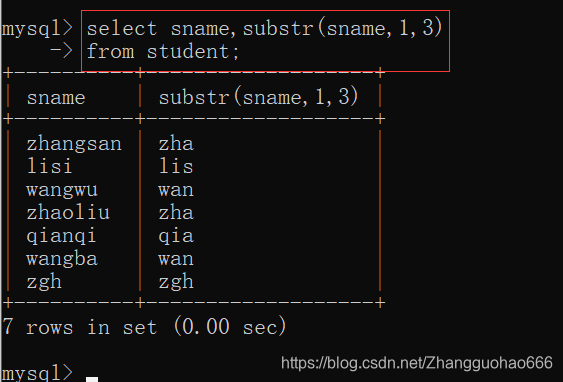
三:字符串函数
字符串函数 String类
length() length()
concat() concat()
substr() substring()
instr() indexOf()
replace() replace()
upper() toUpperCase()
lower() toLowerCase()
ltrim(),rtrim() trim()
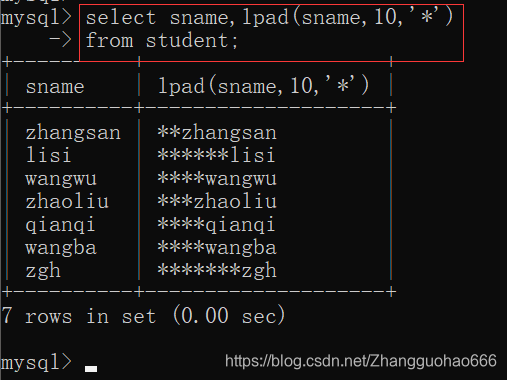
lpad()
rpad()
reverse() StringBuffer,StringBuilder中的reverse()
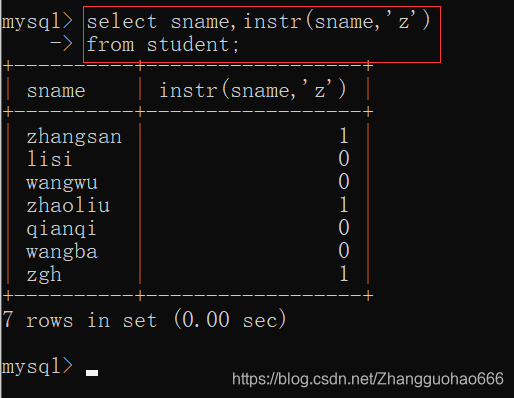
lpad()
sname的长度不够10则在左边补*,补到10个为止
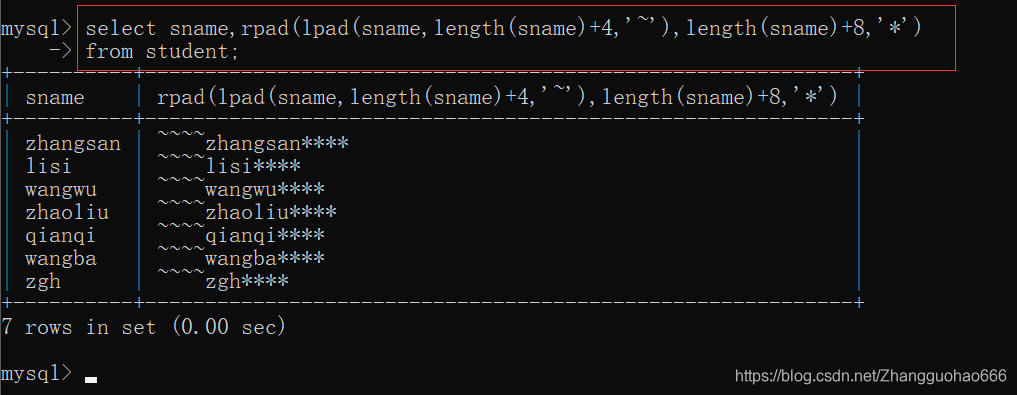
四:聚合函数+分组条件
count()个数max()最大值min()最小值avg()平均数sum()和
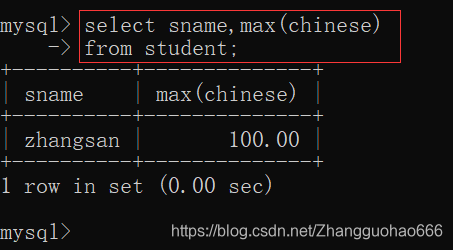
举一个例子:
查询student表中语文成绩最高的
目录八: 条件筛选、排序、分组、嵌套
一:条件筛选
在找寻数据的时候做一个筛选
条件筛选where
- 除了insert语句以外的其它三个语句(update,select,delete)都可以进行筛选
where是一个关键字,拼接在语句的基本结构之后 - 筛选用来筛选符合条件的记录行数
并不是控制显示的列 - 按照某一列或者某一些条件进行筛选
列,满足一定的条件 where后面具体怎么用,连接什么东西
在学习条件筛选之前,先创建一个database,再在里面创建一个table,用来记录学生信息
补充:float(m,n)总共可以存储m位数字,小数点之后有n位;m的取值范围是1-65,n的取值范围是0-30;如果不写参数,默认效果:m是10,n是0
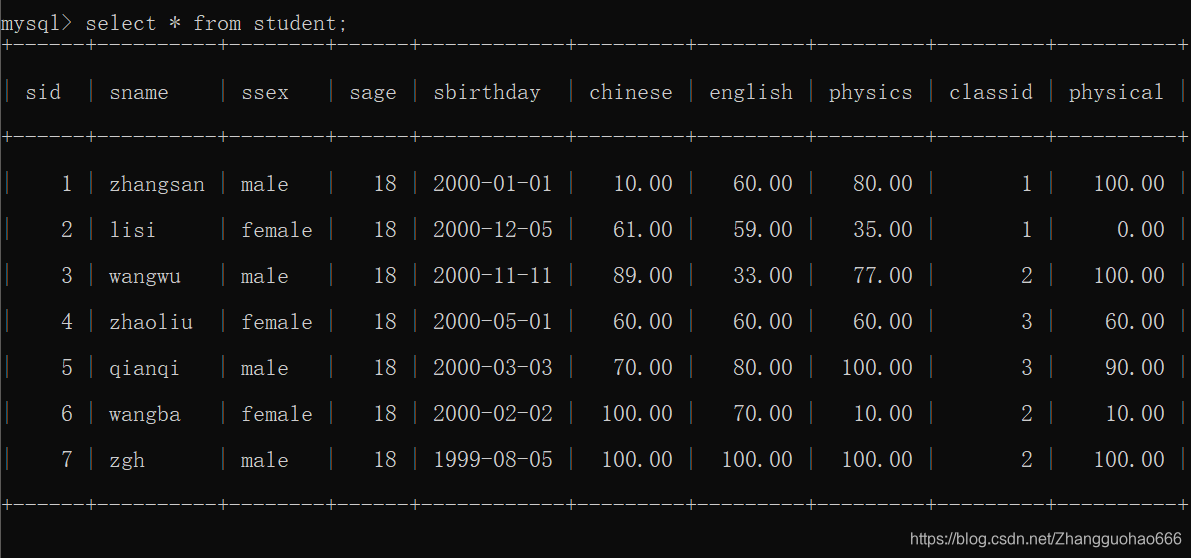
然后在student表中加入这些数据
insert into student values(1,'zhangsan','male',18,'2000-01-01',10,60,80,1,100);
insert into student values(2,'lisi','female',18,'2000-12-5',61,59,35,1,0);
insert into student values(3,'wangwu','male',18,'2000-11-11',89,33,77,2,100);
insert into student values(4,'zhaoliu','female',18,'2000-05-01',60,60,60,3,60);
insert into student values(5,'qianqi','male',18,'2000-03-03',70,80,100,3,90);
insert into student values(6,'wangba','female',18,'2000-02-02',100,70,10,2,10);
insert into student values(7,'zgh','male',18,'1999-08-05',100,100,100,2,100);
student表格:
where后面具体怎么用,连接什么东西
- 比较运算符
> >= < <= != =
select *
选择全部属性(列)
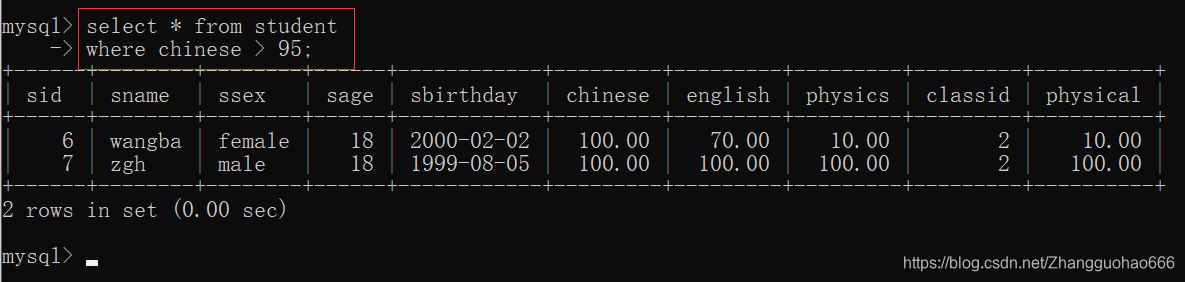
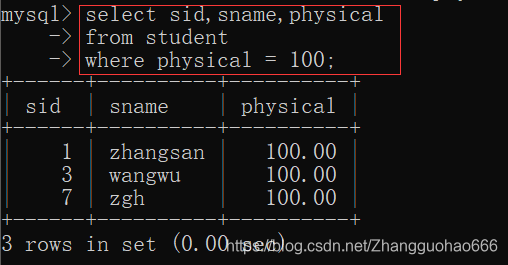
选择部分的属性(列)
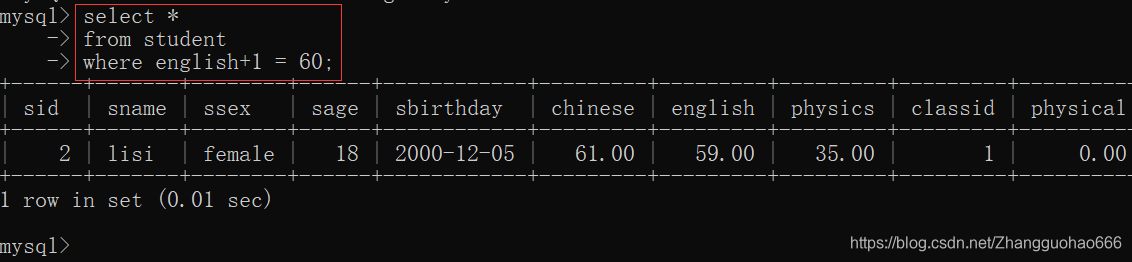
- 算术运算符
+ - * /
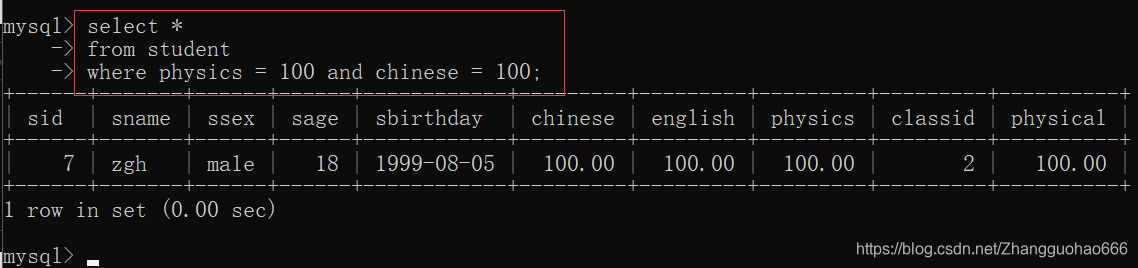
- 逻辑运算符
and or not
优先级,做左往右,优先级降低
数据库底层做的事情
- 解析SQL语句
- 从表格中把全部数据都读取出来,放在数据库中缓存,用集合list
- 将list集合做一个遍历循环,每一次拿到一行记录,然后和where语句做比较
假设我们的表格有7条记录
如果只写一个where条件
执行七次循环就可以出来了
但如果and连接了不止一个where条件
先按照第一个条件筛选(7个循环,假设有6个满足)
然后按照第二个条件筛选(6个循环)
and语句的执行效率很低,and语句尽量少用;但如果在语句中写了and,尽量将条件苛刻的写在前面,提高执行效率,
or也是如此
所以SQL提供了许多可以替代and和or的执行效率更高的语句
如:
between
between 左边界值 and 右边界值
查询的范围:[ 左边界值,右边界值]
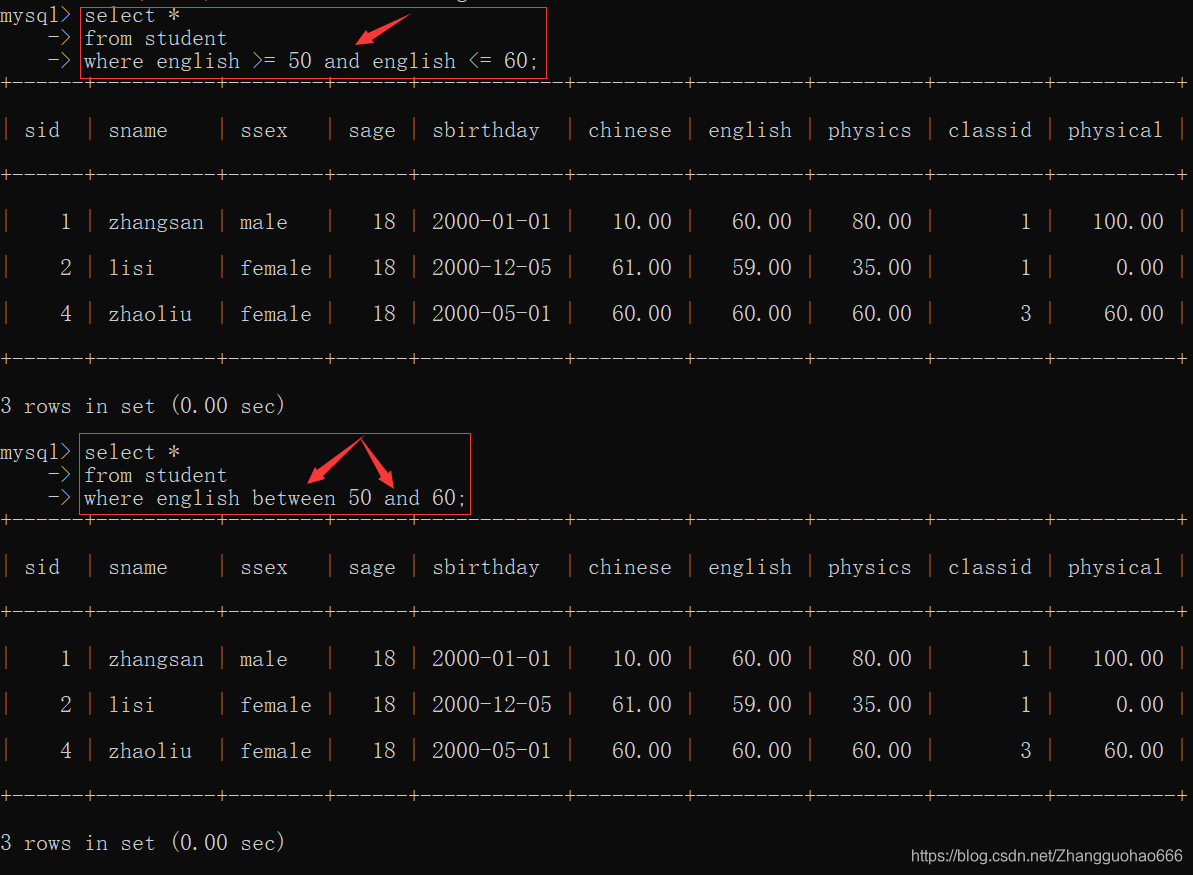
补充一个
not between 左边界值 and 右边界值
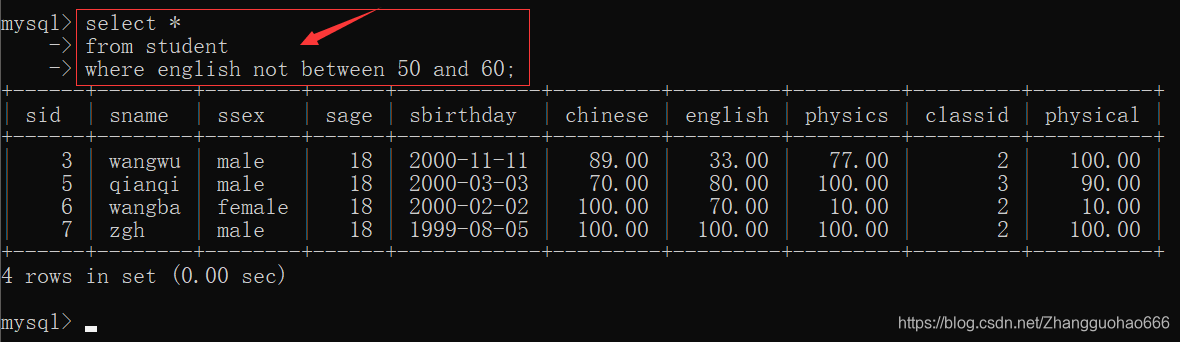
in
in
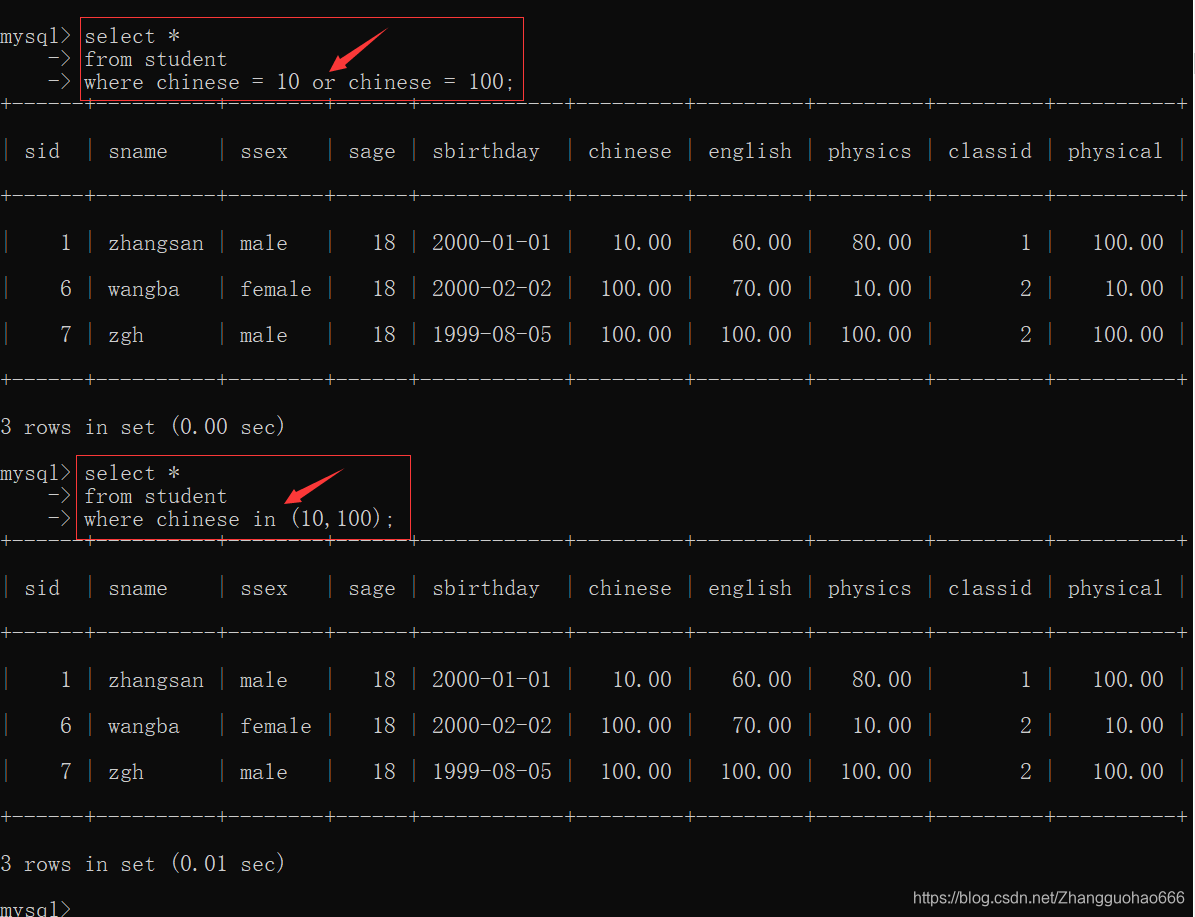
补充一个:
not in
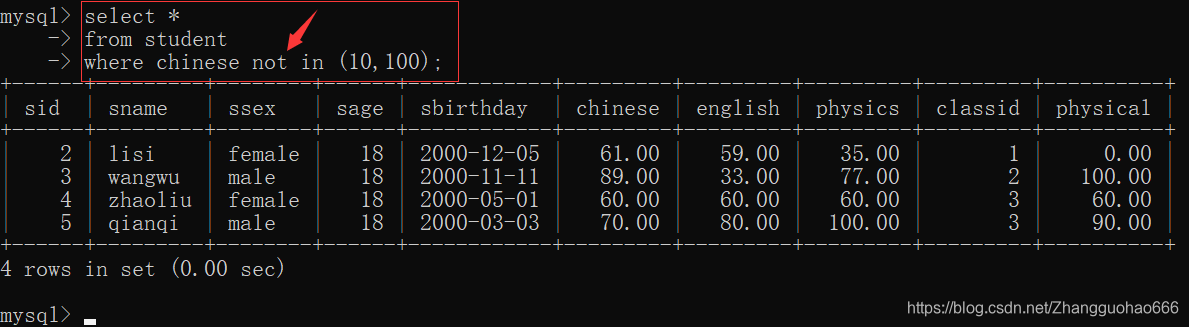
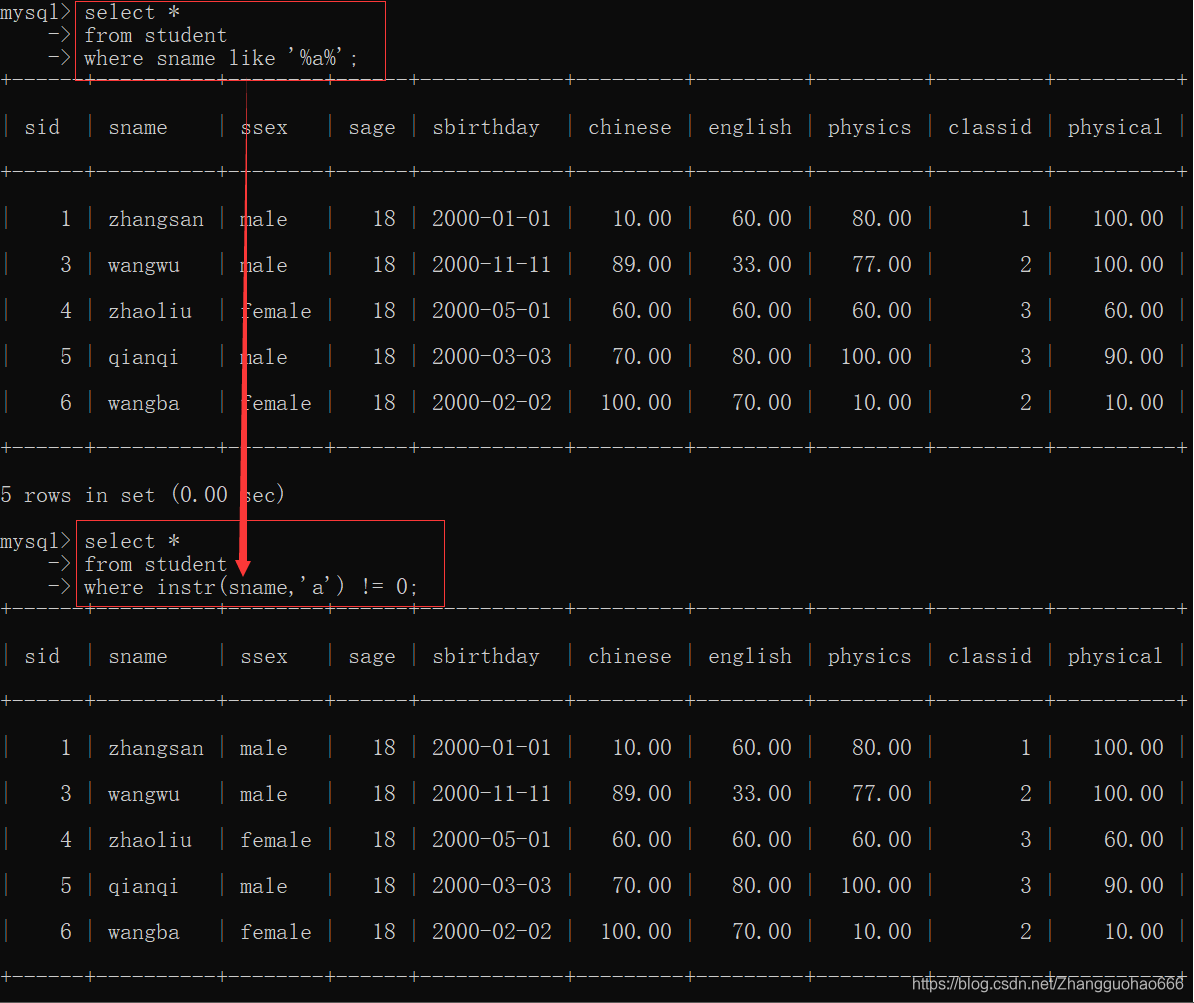
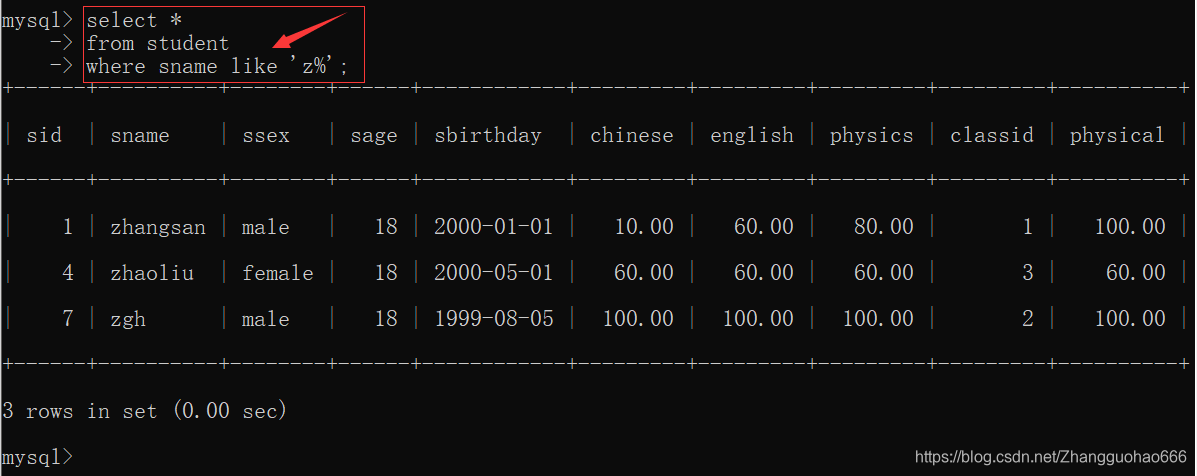
like(模糊查询)
like
%用来代替0-n个字符_用来代替1个字符
先把表的内容看一下:
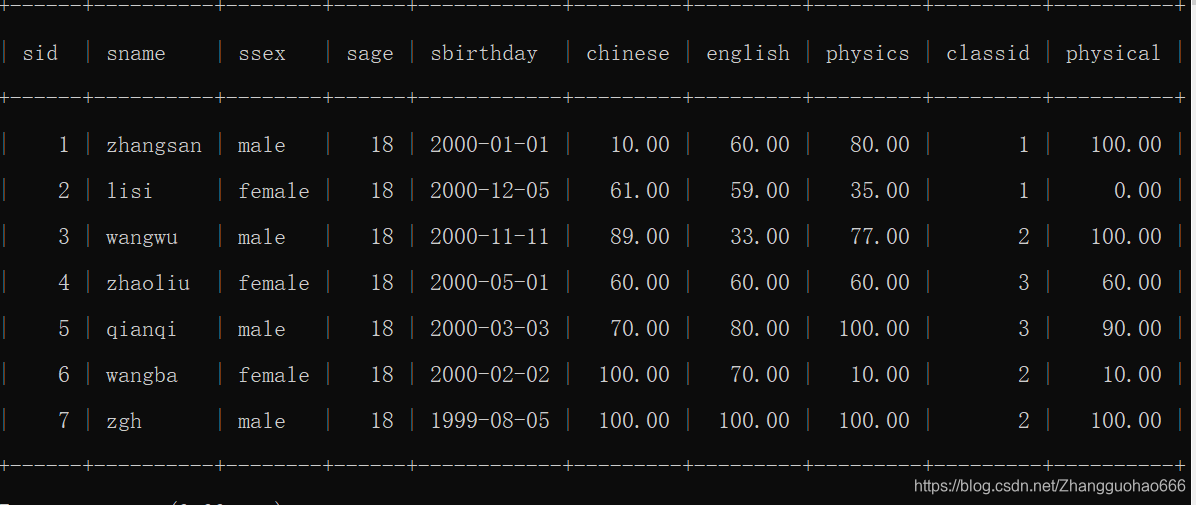
进行模糊查询
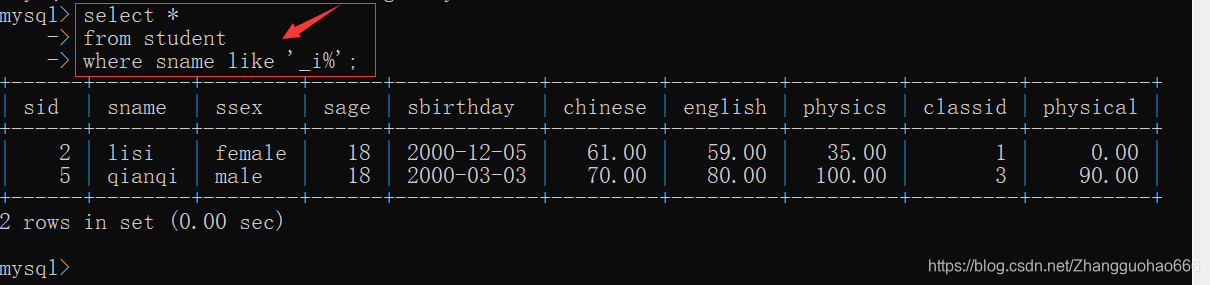
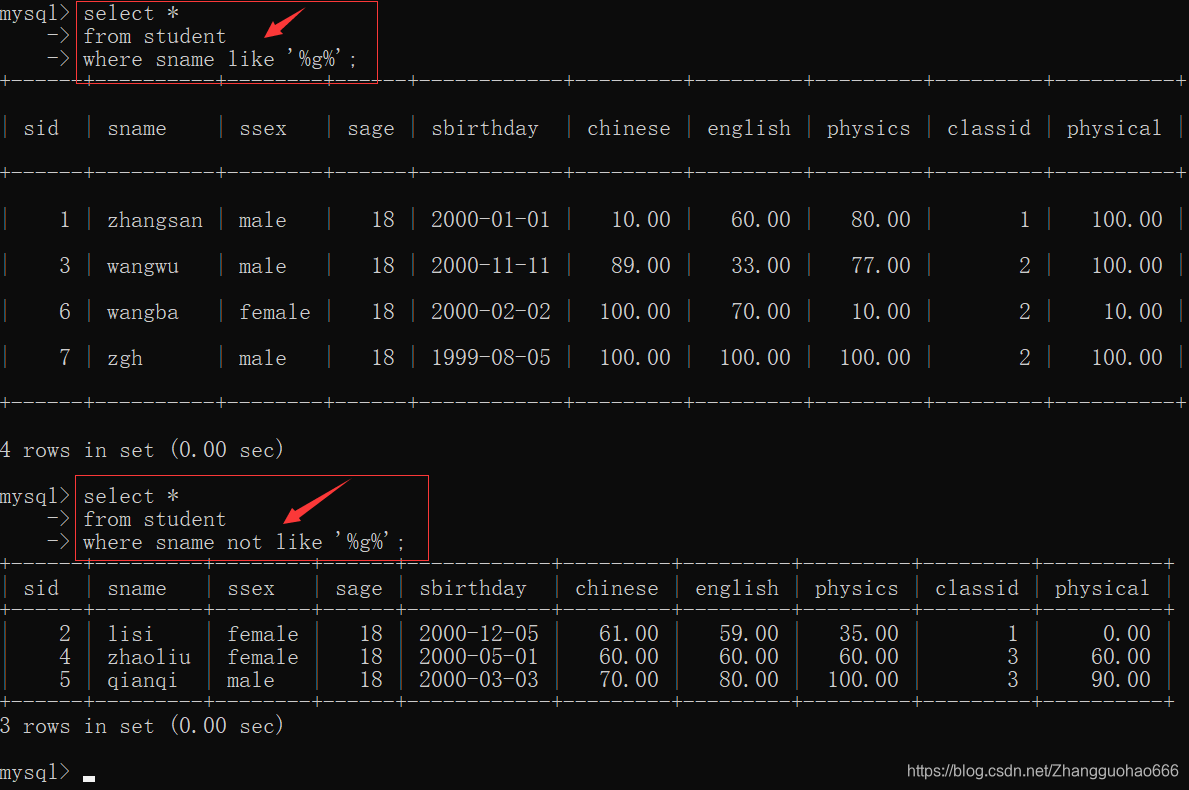
删除delete,修改update语句中的条件筛选的玩法和查询select语句一样,不多说了
二:排序
- 连接在查询的语句之后的
order by 列- 升序排列
asc,默认就是升序的,可以省略不写 - 降序排列
desc
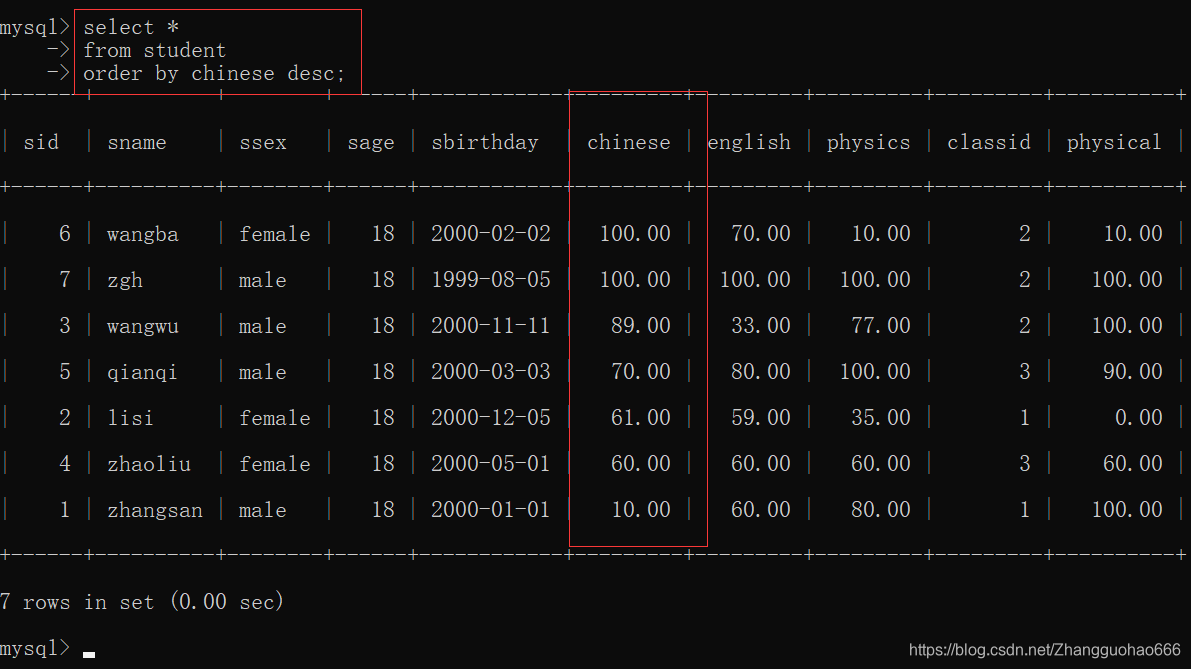
排序语句和条件筛选语句一起写:
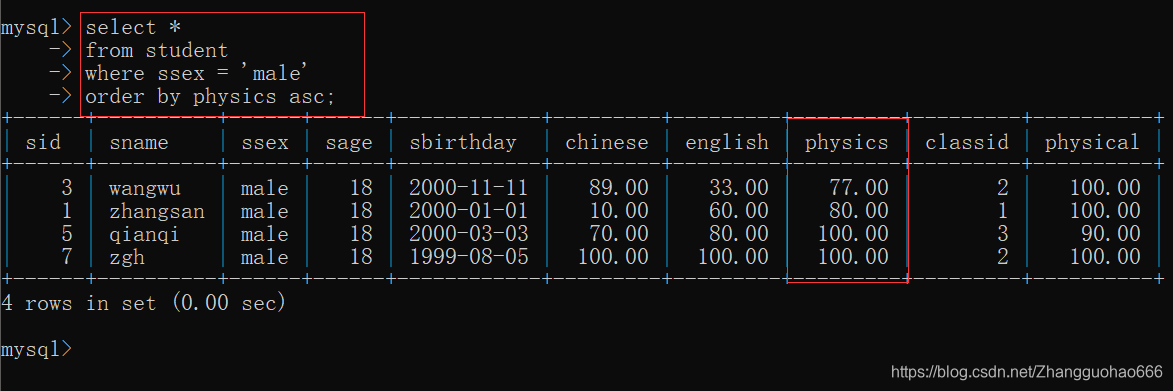
联合查询
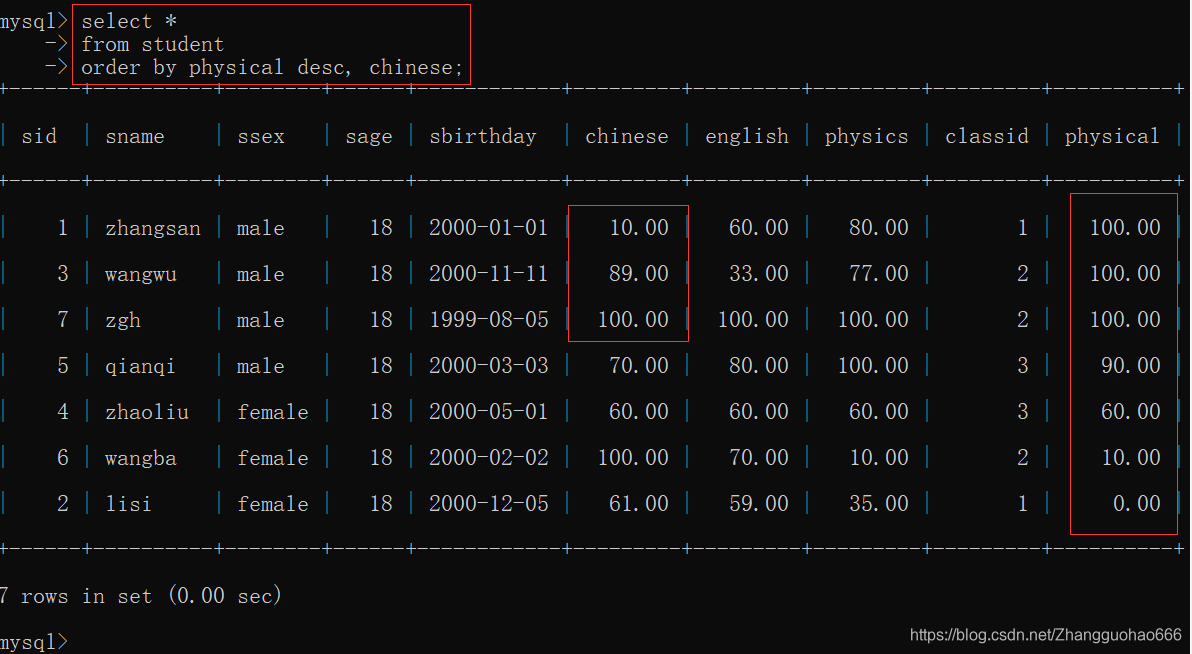
当前面的排序语句相等时,再按照次级排序语句排序
三:分组
group by 列
如果SQL语句中一旦搭配了分组条件,能展示的信息只有两种
- 分组条件
- 分组函数
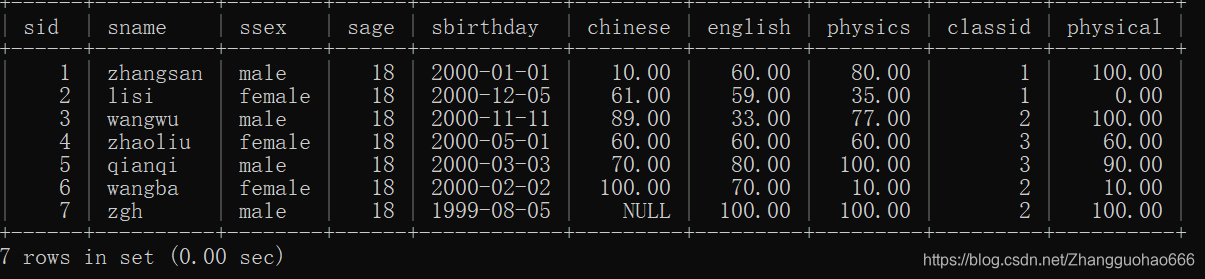
先看一下studnet表:
- 查询student表中每一个班级有多少个同学
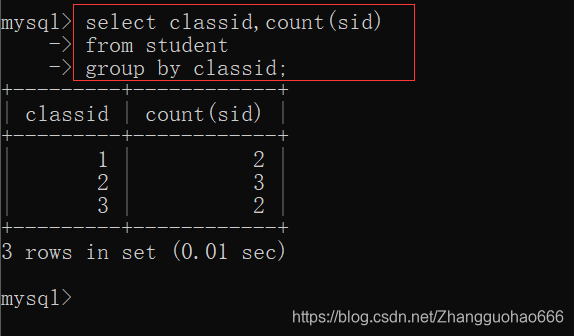
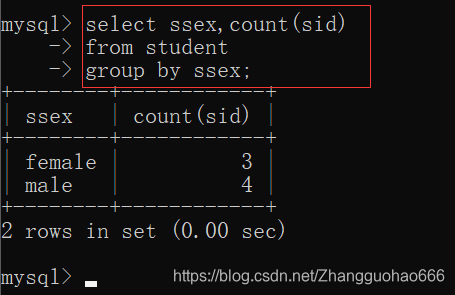
- 查询student表中男,女同学的人数
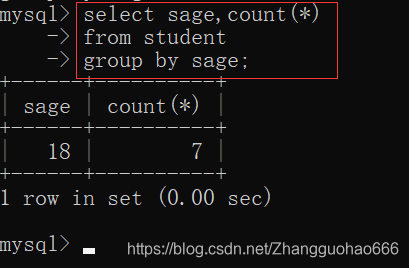
- 查询student表中每个年龄层段有多少人
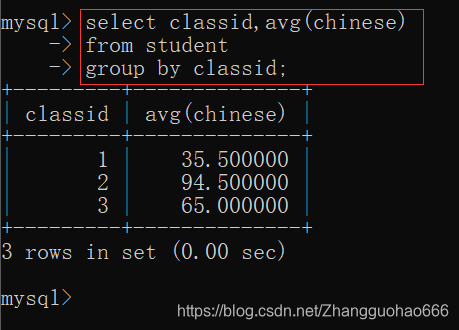
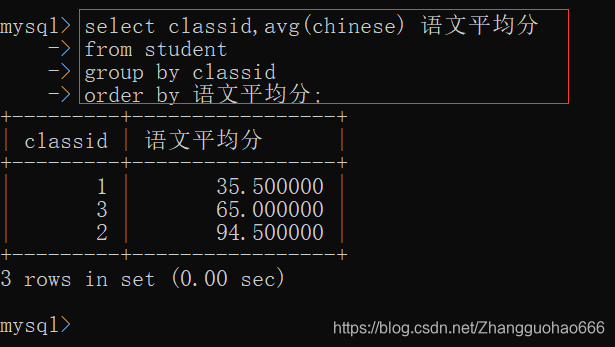
- 查询student表中每一个班级的语文平均分
- 查询student表中每一个班级的语文平均分,并且按照平均分升序排序
四:对于分组条件+分组函数的查询
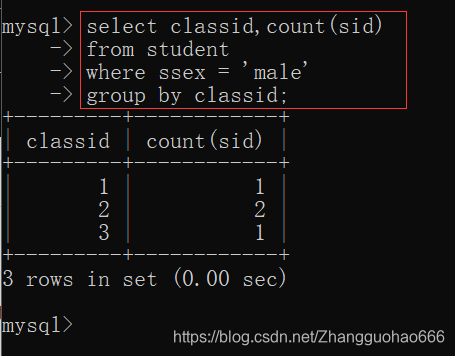
- 查询student表中所有男同学,他们都在哪个班级
先进行where,再进行分组group by
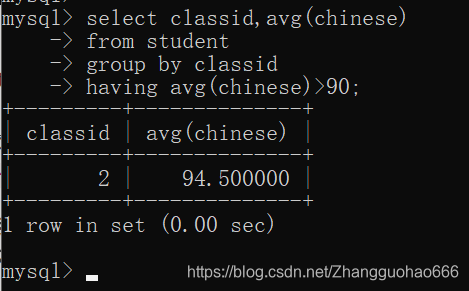
- 查询student表中语文平均成绩高于90分的班级
先分组,再对平均成绩条件筛选
(但是where比group by的优先级别高)
所以SQL给我们提供了一个关键字having,它的用法和where差不多,但是它的优先级比group by低
所以,一般group by和having搭配使用
- 在查询之前需要先考虑,到底是先分组,还是先筛选条件
如果是先筛选,后分组where+group by
如果是先分组,再筛选group by+having - 在查询的时候一旦分组了,行数会减少
想要展示的信息的个数需要与分组条件的个数一致
五:嵌套
在一个完整的SQL语句中,嵌套了另一个完整的SQl语句(当涉及到多个不同的表)
嵌套可以将一个查询的结果当作条件,来再次查询(这种用法很常用)
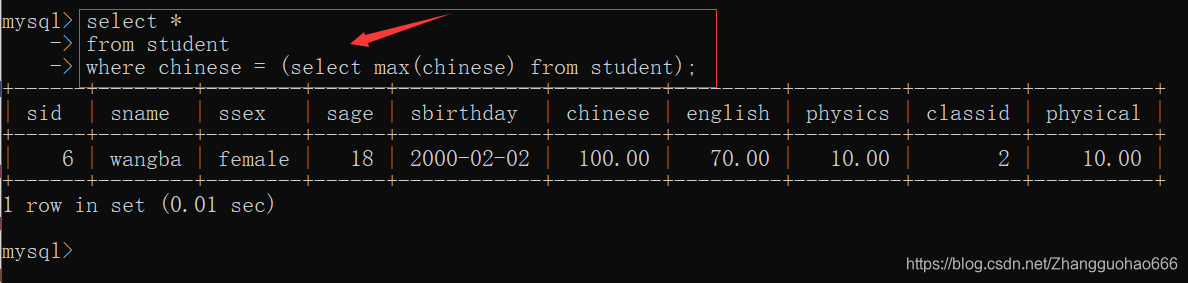
- 查询student表中语文成绩最高分的同学
嵌套可以将一个查询的结果当作一个表格(需要给这张表格取别名),在这张的表格的基础上再次查询
- 查询student表中男同学的sname,ssex,sage,classid
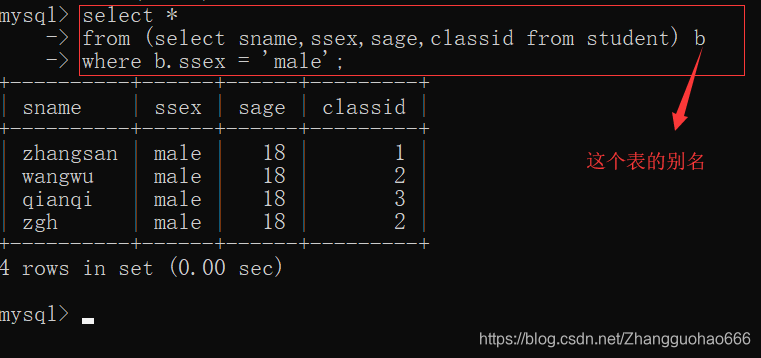
目录九: 表格之间的联合查询
就是将多张表的数据没有任何条件的组合在一起,形成一张完整的大的表格,然后在这张大的表格上进行筛选
- 等值连接(等值连接之前,需要先进行广义笛卡尔积)
- 外连接
- 内连接(自连接)
一:广义笛卡尔积
广义笛卡尔积将两张表格或多张表格,进行无条件的拼接
先看两张表:
emp表(存储雇员信息):
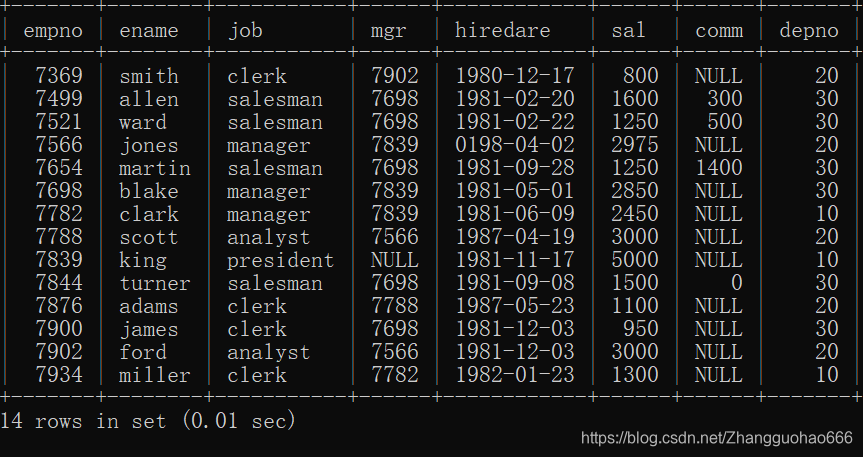
dept表(存储部门信息):
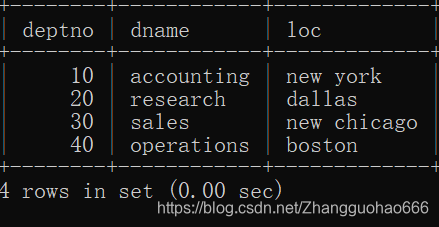
然后,把这两个表的数据没有任何条件的组合在一起,形成一张完整的大的表格(广义笛卡尔积)
列数为两张表的列数相加
行数为两张表的行数相乘
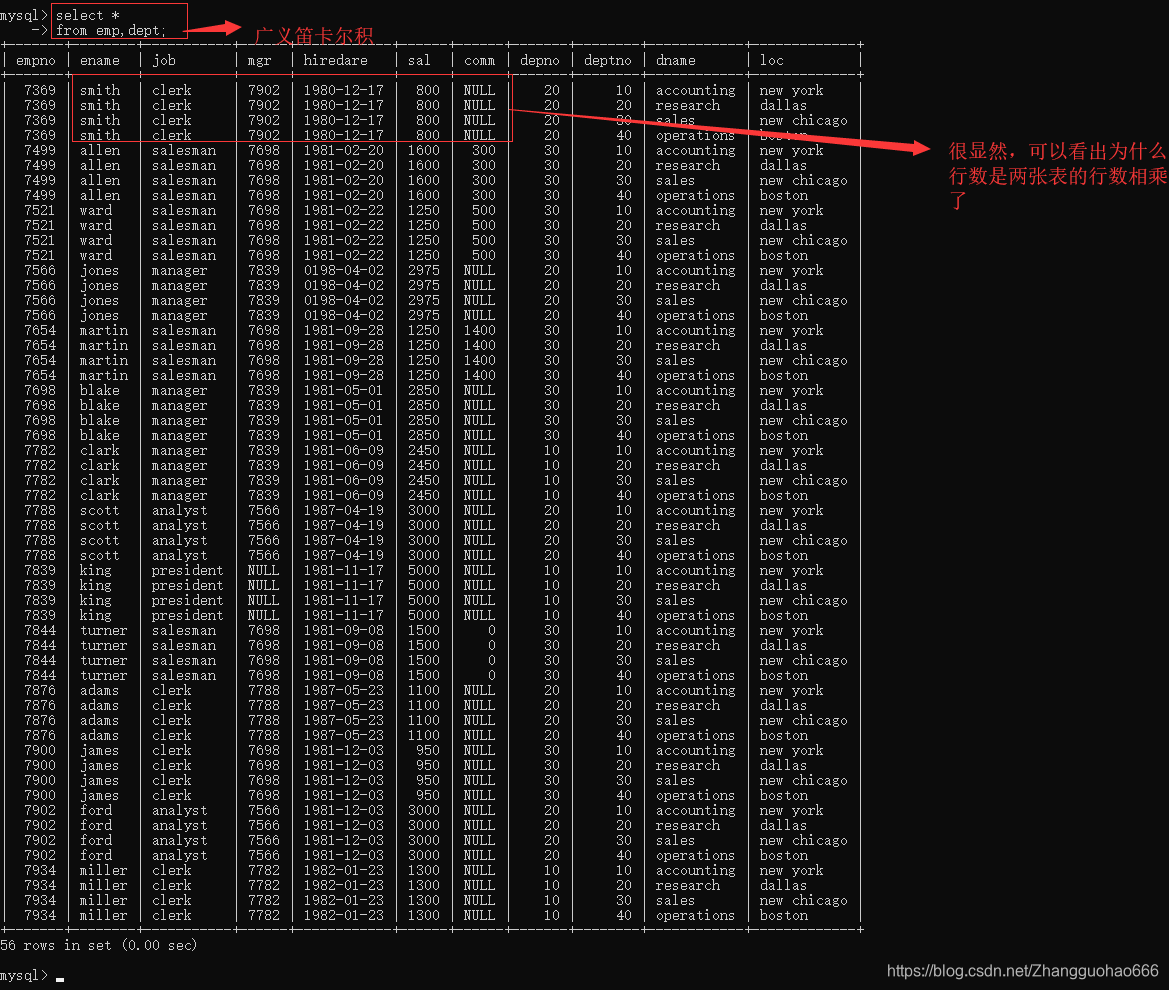
广义笛卡尔积,简单粗暴,两张表的全部数据都组合起来了
但是很多数据是没有意义的,
比如雇员smith和四个部门的组合的数据中,只有部门20的那一行组合的信息才有意义
二:等值连接
在广义笛卡尔积的基础上,进行条件筛选
因为一般筛选都是通过=来进行的,所以才叫等值连接
(注意,不一定必须是=,其它的判断语句也行)
比如:
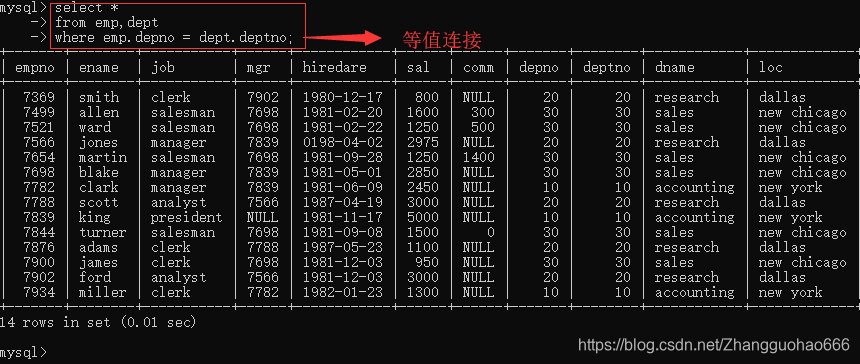
然后:
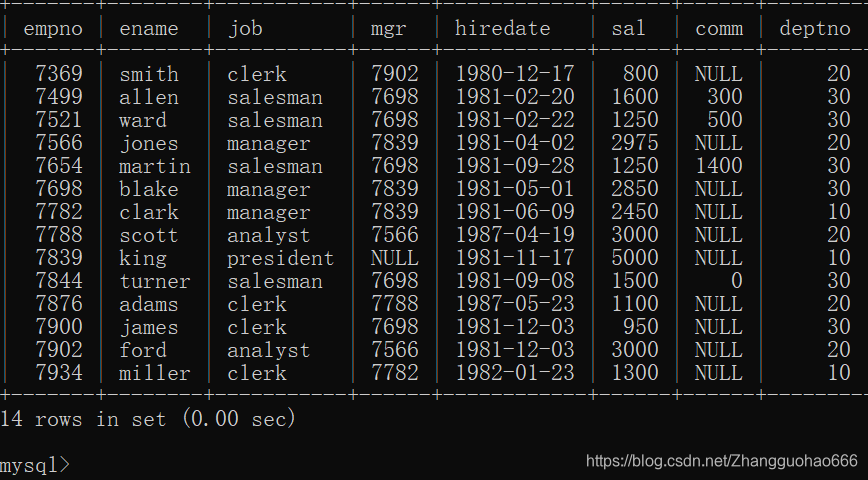
因为emp表格中我在定义和插入数据时有一些错误,我把这些错误更正后的emp表:
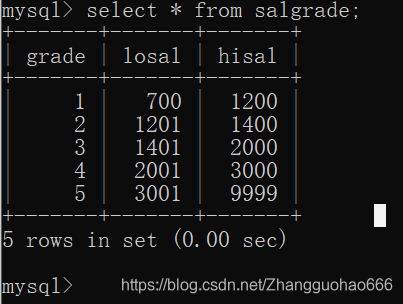
然后,我创建一个表salgrade(记录工资的等级),然后插入一些数据和一些约束:
create table salgrade(
grade int(4),
losal int(6),
hisal int(6)
);
alter table salgrade add primary key(grade);
insert into salgrade values(1,700,1200);
insert into salgrade values(2,1201,1400);
insert into salgrade values(3,1401,2000);
insert into salgrade values(4,2001,3000);
insert into salgrade values(5,3001,9999);
salgrade表:
然后,把emp表个salgrade表进行等值连接:
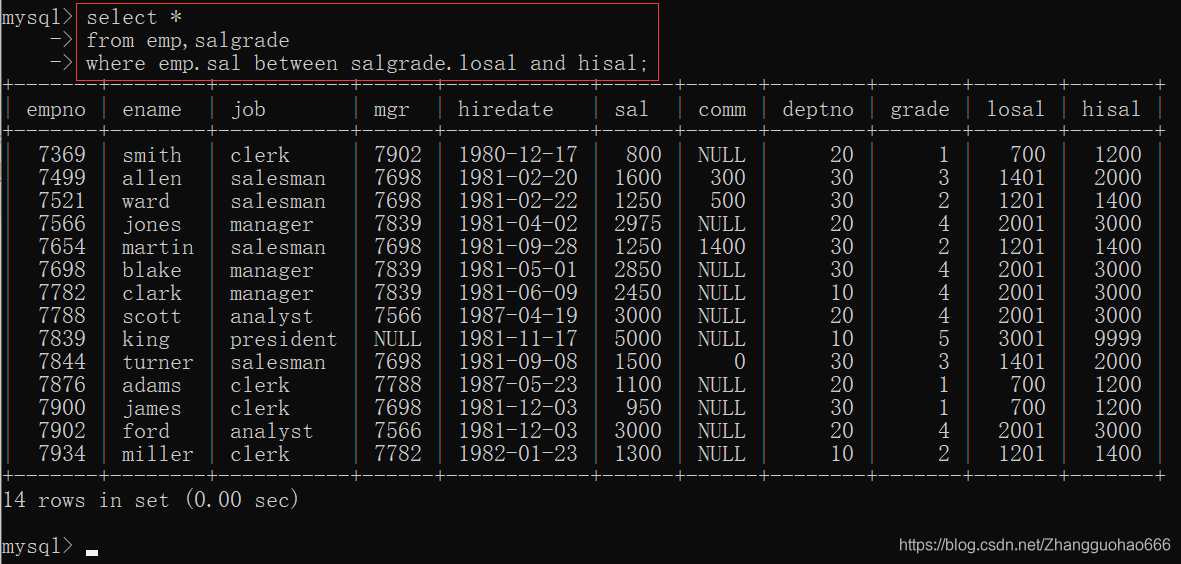
查询一下每个工资等级有多少个雇员
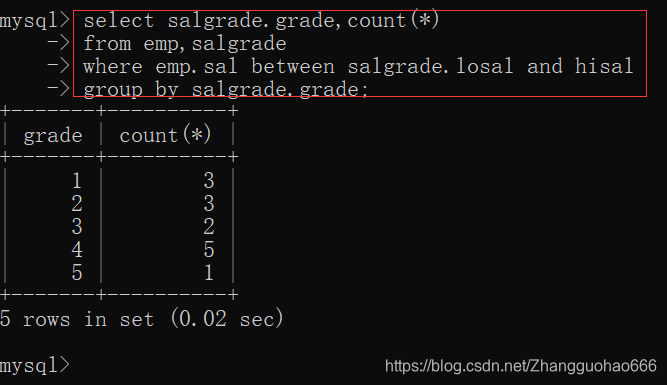
其实,等值连接的性能不太好
因为先要进行笛卡尔积,然后进行条件筛选
为了提高查询的性能,SQL提供了两种查询办法(外连接和内连接,性能更高)
三:外连接
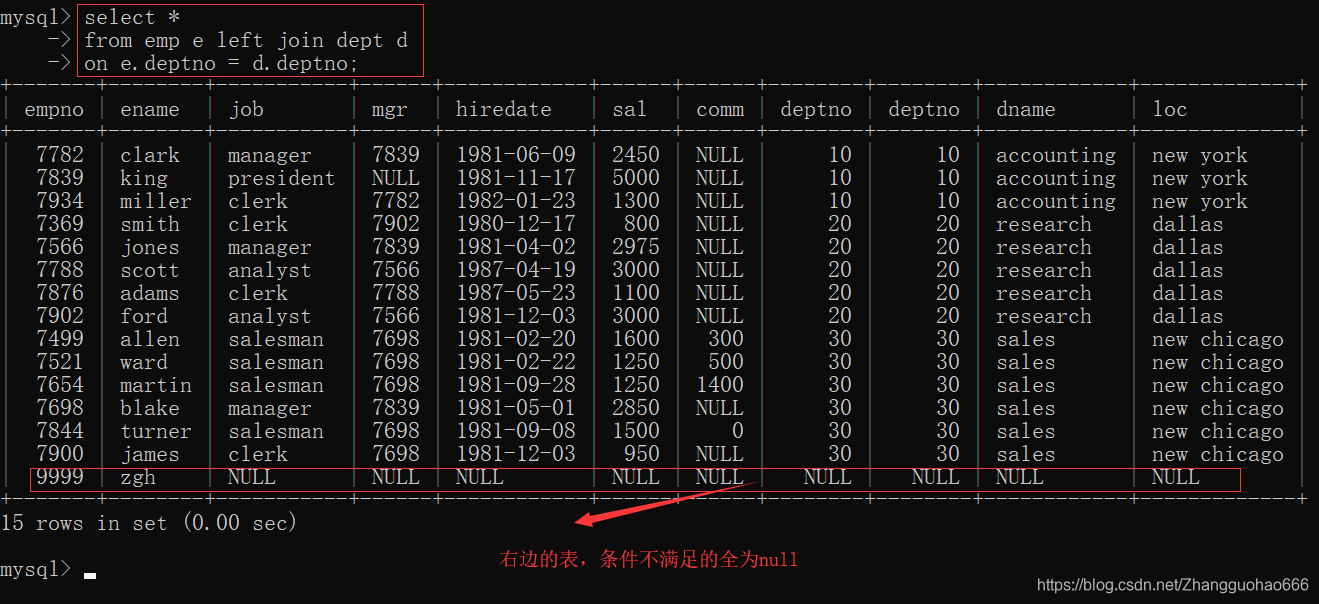
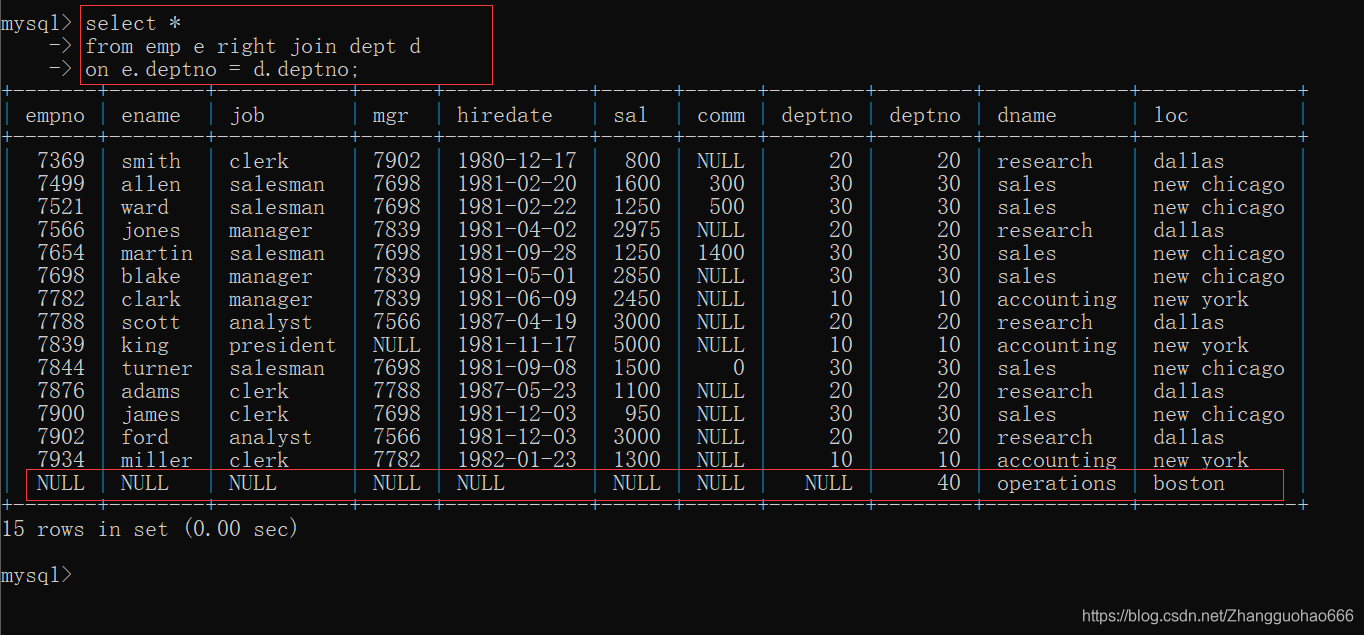
select * from A left/right [outer] join B on 条件;
补充:[]内的语句代表可有可无,/代表或者
看到left就是左外连接,right是右外连接
on关键字和where的作用差不多,但是where的优先级比from的低;而on的优先级比from的优先级高
- 两张表格A和B,取决于谁的数据在左边显示
A表格先出现,A左边显示
B表格先出现,B左边显示 left和right来控制以哪一个表格的数据作为基准
作为基准的表格的数据必须全部显示出来
非基准的表格按照on条件与之拼接,条件满足的正常显示,不满足条件的则为null
拿emp表和dept表做演示
因为两张表的deptno的属性都可以对应上,
我先在emp表中插入一个特殊的数据:
emp表:
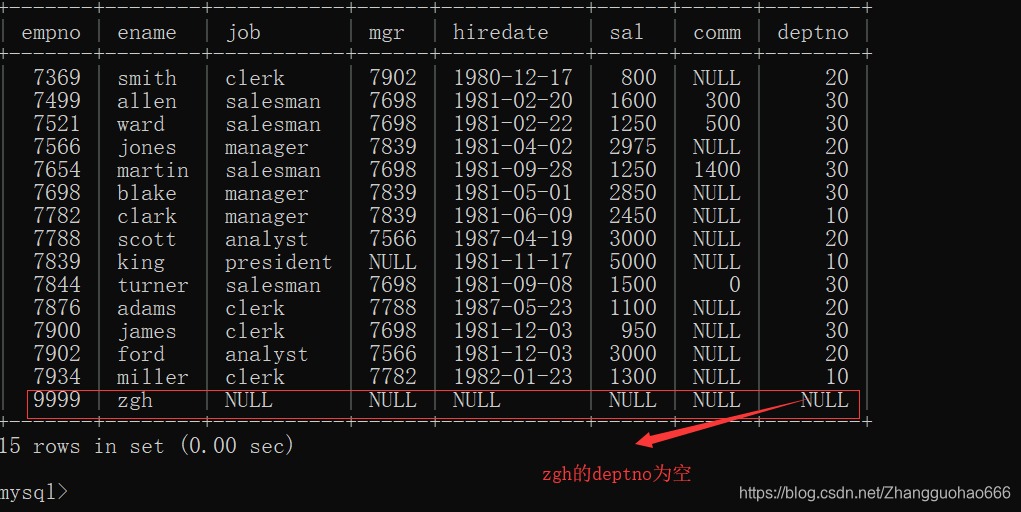
dept表:

左外连接
右外连接
四:内连接
select * from A inner join B on 条件;
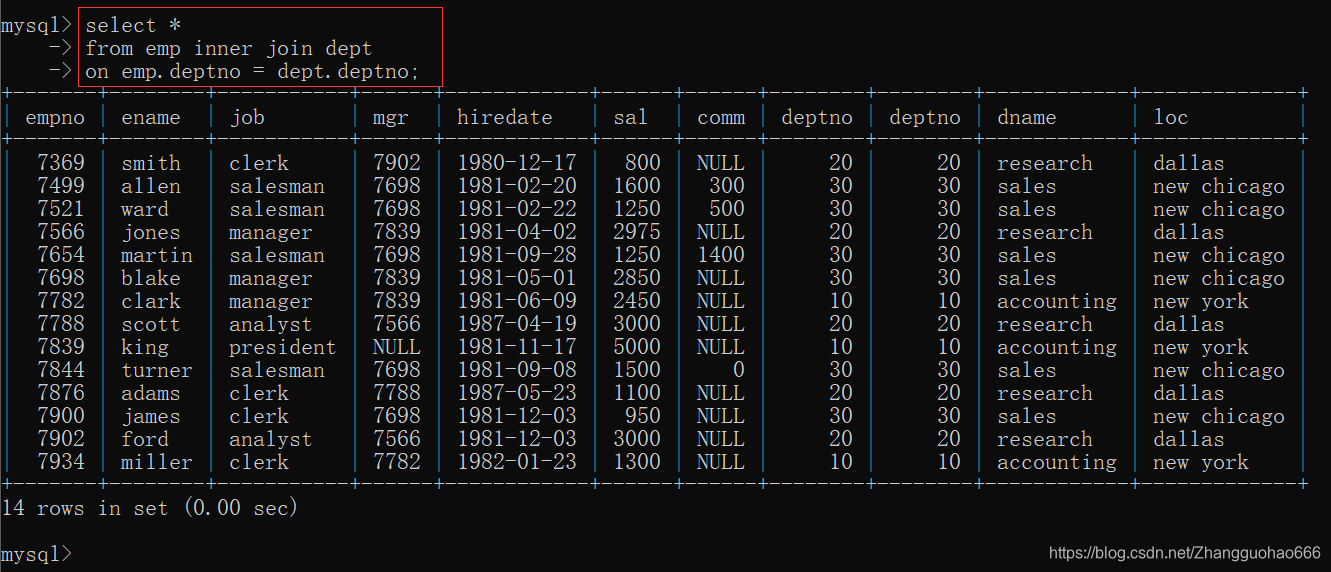
可以看出,内连接的查询结构和等值连接的查询结果是一样的(但是,内连接的性能更加棒)
还有一个比较特殊的玩法(在当前表格中再次查询当前表格的信息):
先看一下emp表:
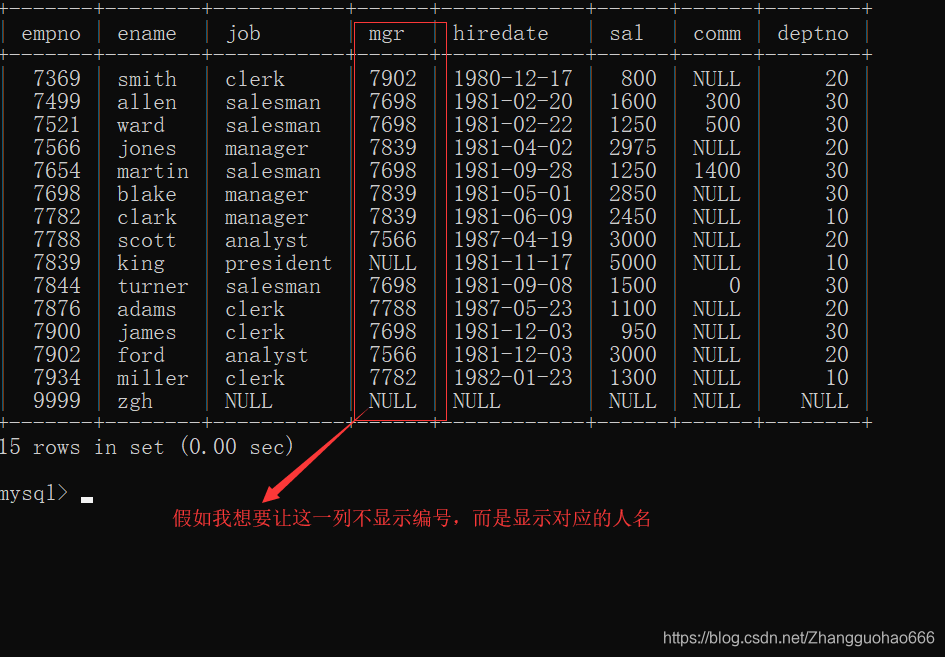
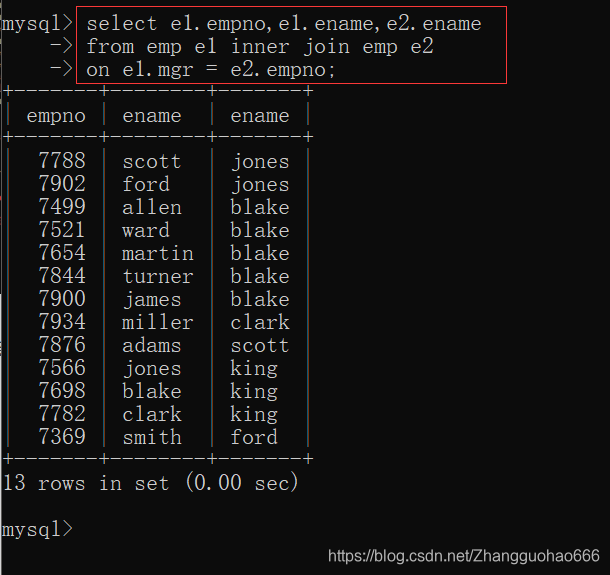
(补充,其实等值连接也可以这玩)
目录十: 行列互换、分页查询、设计范式
一:行列互换
先创建一个表warehouse(存储仓库信息):
create table warehouse(
wname varchar(8),
winventory int(8),
wmonth varchar(8)
)character set utf8;
insert into warehouse values
('A',100,'一月份'),('B',1000,'一月份'),('C',10,'一月份'),
('A',200,'二月份'),('B',2000,'二月份'),('C',20,'二月份'),
('A',300,'三月份'),('B',3000,'三月份'),('C',30,'三月份');
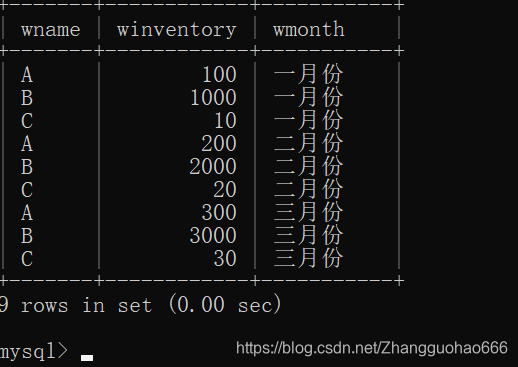
若要使表格像这么显示:
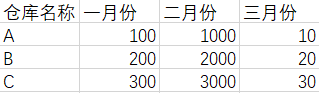
首先,要使用group by关键字进行条件分组
通过仓库名称分组:
- A组 三个值 每一个月份对应一个库存
- B组 三个值 每一个月份对应一个库存
- C组 三个值 每一个月份对应一个库存
分组后,显示的属性的值要分情况讨论,要使用if()三目运算函数
select
wname 仓库名,
max(if(wmonth = '一月份',winventory,0)) 一月份,
max(if(wmonth = '二月份',winventory,0)) 二月份,
max(if(wmonth = '三月份',winventory,0)) 三月份
from warehouse
group by wname;
因为,一旦使用了group by分组条件
select可以显示的列只有两种(分组条件和分组函数)
(注意:select中用到的分组函数可以是max(),也可以是min()…因为反正只有一个嘛)

二:分页查询,limit
emp表格:
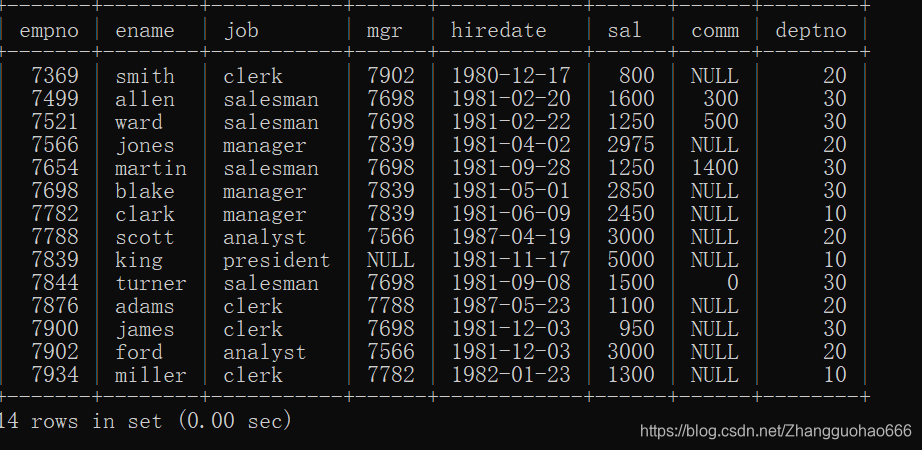
emp表格有14行记录,假如每一页只能显示5行记录,必然会产生分页
怎么做呢?
MySQL中有一个关键字limit a,b(a代表想要显示的起始行索引,索引行是从0开始的;b代表想要显示的行数)
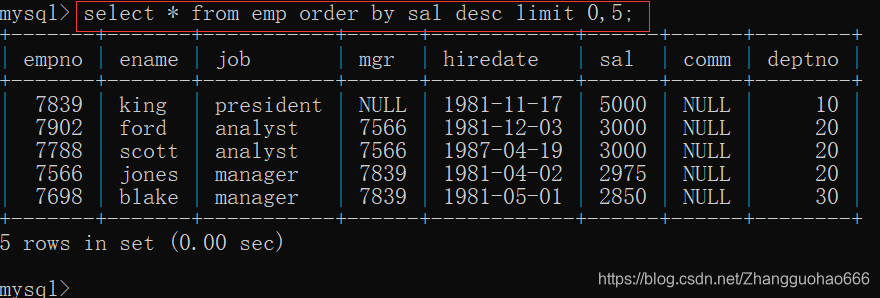
显示前五行:
select *
from emp
order by sal desc
limit 0,5;
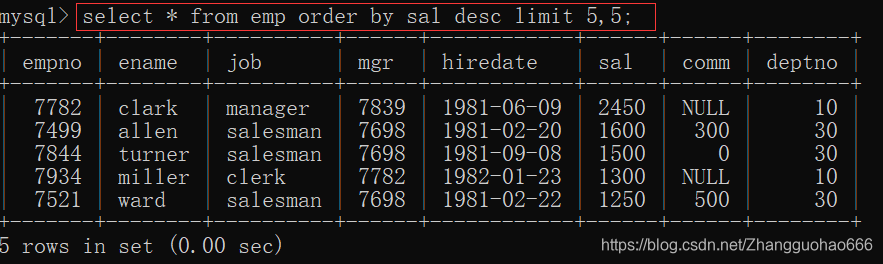
显示中间五行:
select *
from emp
order by sal desc
limit 5,5;
显示最后面的:
select *
from emp
order by sal desc
limit 10,5;
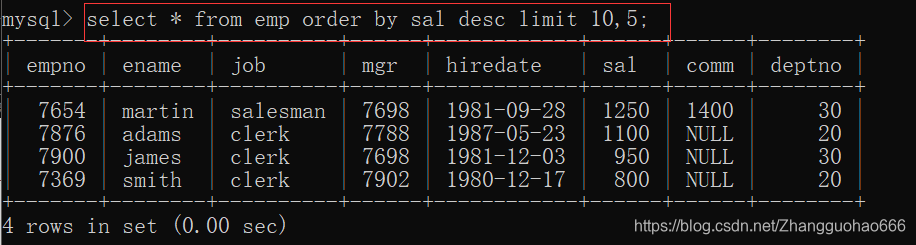
(补充:如果行数不够,就算了)
Oracle数据库的查询就比较麻烦了,它要使用一个伪列rownum还有level,rowid
SQL Server要使用top
三:数据库设计的范式Normal Form
- 设计数据库时,遵循的不同规范,这些规范统称范式
- 范式的目的是为了减少数据库的冗余,管理表格的时候变得容易(修改、删除)
- 但是查询的时候可能涉及到表格联合的问题(性能会降低一点)
有这么一张表格(用来记录学校里面不同楼宇项目的一些信息)
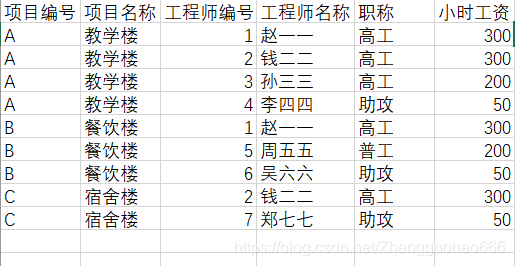
上表存在很多问题
- 数据有大量冗余
- 所以修改起来比较麻烦
1FN
- 数据库中每一张表格的每一个列都是不可分割的(数据的原子性)
通俗的解释:行列交叉点的单元格内只存储一个数据 - 每一个表格中必须有主键约束(快速查询某一行记录)
(上表不遵循1FN,原子性可以保证,
但表格内没有主键----设定联合主键:项目编号+工程师编号)
2FN
- 在满足1FN的前提下,
- 不允许出现部分依赖性(非主键列不能受主键列或主键列的一部分影响)
(如果产生了非主键列受到主键或主键的部分影响----将数据拆开存储在两张表中)
看上表,当设定(联合主键:项目编号+工程师编号)之后,虽然满足了1FN
但是,工程师名称和工程师编号有关系,这个没问题
但是工程师名称和项目编号本应该没有关系的,但是由于联合主键的缘故,工程师名称受到了项目编的影响,不满足2FN
改动:
将上表拆成两个表格
工程表格
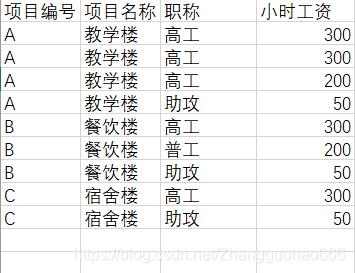
(拆开之后会发现,工程表格没有了主键,这个先放在这里,往后面看)
工程师表格
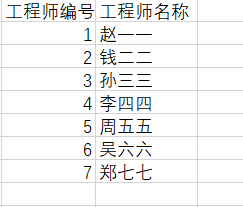
3FN
- 在满足前两个范式的前提下,
- 不允许出现传递依赖性(非主键列不能受到非主键列或非主键的一部分影响)
(如果非主键列受到了非主键列或非主键的一部分影响----将没有关系的数据拆开单独存放在表格中)
在工程表格中,
小时工资受到了职称的影响,不满足第三范式
改动:
将工程表格拆成两个表格
项目表格
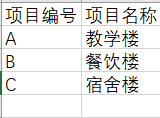
(主键是:项目编号)
职称表格
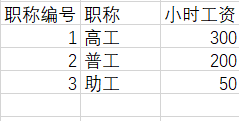
(给职称表格加一个属性:职称编号,来作为主键)
再看一下
工程师表格
(主键是:工程师编号)
虽然满足了3FN
但是,在实际应用中,用户需要对这三张表格做联合查询
所以,三张表格之间的关系也要处理一下:
- 工程师和项目是多对多的关系,所以需要构造另一张表(项目_工程师中间表)
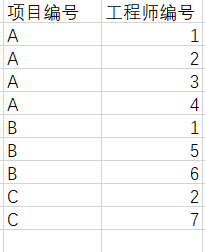
(项目编号和工程师编号是这张表的联合主键;
项目编号是项目表的外键;
工程师编号是工程师表格的外键)
- 工程师和职称是多对一的关系
所以工程师表格需要添加一个职称表格的外键
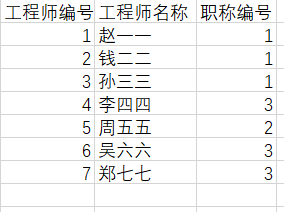
最终成果:
项目表格
职称表格
项目_工程师中间表
工程师表格
