1 实现伪分布式配置
1.1 配置HDFS
1 配置core-site.xml:
指定hdfs:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
</configuration>
2 配置hdfs-site.xml:
配置副本数为1:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>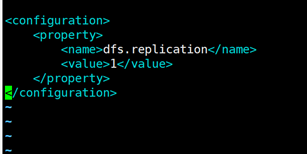
1.2 配置Yarn
配置yarn-site.xml:
1指定shuffle,2 指定resourcemanager,因为是伪分布式,rm的host就是本机
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
</configuration>
1.3 配置MR
配置mapred-site.xml
指定yarn:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>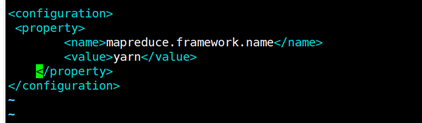
2 启动集群
2.1 格式化NameNode
第一次启动,可以格式化NN
bin/hdfs dfs namenode -format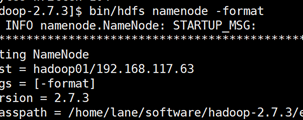
2.2 启动
启动NameNode,DataNode,ResourceManager和NodeManager,jps命令查看是否启动成功
sbin/start-hdfs.sh
sbin/start-yarn.sh
图上是一个个手动启动的:

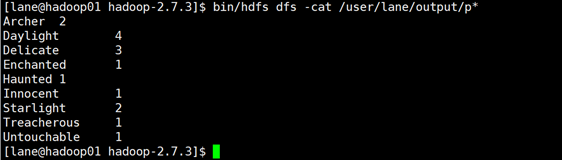
3 执行wordcount
3.1 创建一个要被统计词频的文件
input:

3.2 将它传到HDFS
bin/hdfs dfs -put input /usr/lane/input

3.3 执行wordcount
- 官方案例都在share文件夹下
- output文件事先不能存在
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar word count /user/lane/input /user/lane/output

查看output文件内容,执行成功。