第三讲:
今天我们来介绍一个新模块,Beautiful Soup!
这个模块有许多神奇的功能,首先,我们不将它怎么神奇,先把它安装好,才能体现出它神奇的功能。
安装如下:
Win10系统下运行cmd(命令提示符)
敲入pip install beautifulsoup4
就可以进行安装了。这里省去安装的一些具体细节,我们把目光集中在它神奇的功能上!
1 '''加入新模块''' 2 3 import requests 4 5 from bs4 import BeautifulSoup 6 7 8 9 def getHTML_Text(url): 10 11 try: 12 13 r = requests.get(url) 14 15 r.raise_for_status() #如果状态不是200,则产生异常 16 17 r.encoding = r.apparent_encoding 18 19 return r.text 20 21 except: 22 23 return '产生异常' 24 25 26 27 if __name__ == '__main__': 28 29 url = 'https://www.hao123.com/' 30 31 print(getHTML_Text(url)[:5000])
这是我们上期的通用代码,经过简单修改之后,运行:

得到一串字符串,前面提到过,这里面包含了我们需要的信息(参考第二讲的实例1),而我们今天要做的就是把他们提取出来。BeautifulSoup模块的神奇功能不言而喻了。
废话不多说,我们先大概了解一些beautifulsoup的基本运用。
1 from bs4 import BeautifulSoup 2 soup = BeautifulSoup(‘<p>data</p>’,’html.parser’)
<p>data</p>是一段字符串,代指…
也就是我们上两讲所提及到的,把网页爬取下来的text内容,
html.parser 是一个解析器,用与解析HTML Document
通过上面的代码,可以建立一棵标签树,对应着HTML文档的全部内容,这样建立之后,更方便我们查找到所需的内容。
BeautifulSoup类的基本元素
| 基本元素 |
说明 |
| Tag |
标签,最基本的信息组织单元,<>和</>标明开头结尾 |
| Name |
标签的名字,格式<tag>.name |
| Attributes |
标签的属性,以字典形式组织,格式:<tag>.attrs |
| Navigable String |
标签内非属性字符串,<>…</>中字符串,格式:<tag>.string |
| Comment |
标签内字符串的注释部分 |
让我们来一一展示一下:
1 '''BeautifulSoup演示''' 2 3 import requests 4 5 from bs4 import BeautifulSoup 6 7 8 9 def getHTML_Text(url): 10 11 try: 12 13 r = requests.get(url) 14 15 r.raise_for_status() #如果状态不是200,则产生异常 16 17 r.encoding = r.apparent_encoding 18 19 return r.text 20 21 except: 22 23 return '产生异常' 24 25 26 27 if __name__ == '__main__': 28 29 url = 'https://www.hao123.com/' 30 31 soup = BeautifulSoup(getHTML_Text(url),'html.parser') 32 33 title = soup.title 34 35 tag = soup.a 36 37 print(title.string) 38 39 print(str(tag.name)) 40 41 print(str(tag.attrs)) 42 43 print(str(tag.string)) 44 45 print(str(tag.comment))
运行结果:

首先打印出整个HTML的title标签的内容
在获取了第一个a标签之后,分别打印出标签名、标签属性、标签内容、标签注释部分。
大体上就是这些用途,还有更多有意思的功能大家自己发掘,这里只是简单提到。
这里还介绍一个prettify()方法,让我们的显示更友好。
例如:
1 '''BeautifulSoup演示''' 2 3 import requests 4 5 from bs4 import BeautifulSoup 6 7 8 9 def getHTML_Text(url): 10 11 try: 12 13 r = requests.get(url) 14 15 r.raise_for_status() #如果状态不是200,则产生异常 16 17 r.encoding = r.apparent_encoding 18 19 return r.text 20 21 except: 22 23 return '产生异常' 24 25 26 27 if __name__ == '__main__': 28 29 url = 'https://www.hao123.com/' 30 31 soup = BeautifulSoup(getHTML_Text(url),'html.parser') 32 33 print(soup.prettify()[:5000])
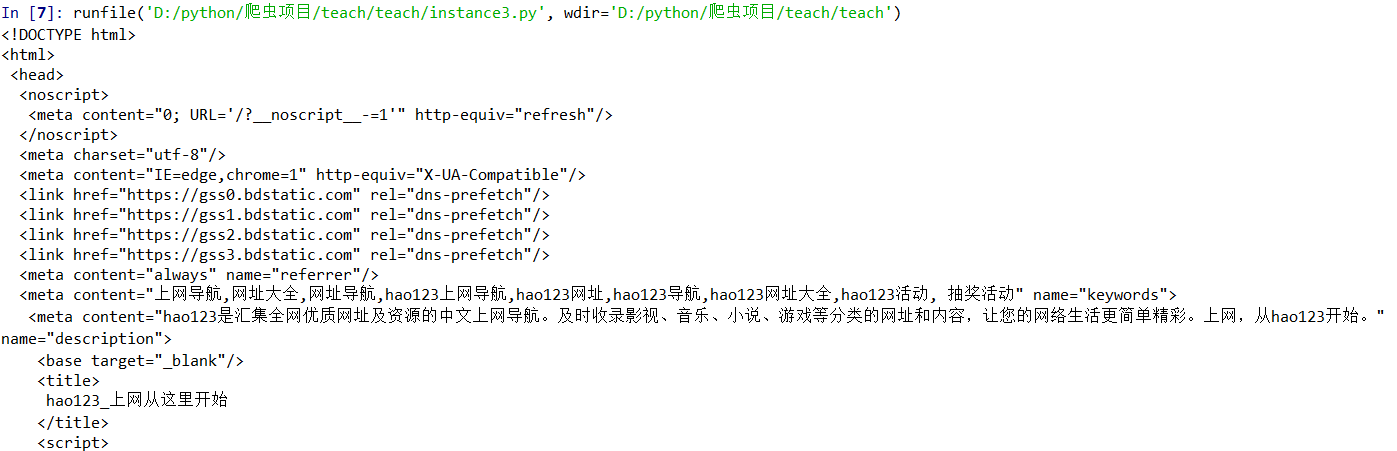
结果如上图,显示出比较友好的文本形式了,否则直接打印的话,密麻麻的字符串,看得确实让人头疼。
最后小小展示一些BeautifulSoup的一个有用的方法,具体的下期再详细讲,看代码!
1 '''BeautifulSoup演示''' 2 3 import requests 4 5 from bs4 import BeautifulSoup 6 7 8 9 def getHTML_Text(url): 10 11 try: 12 13 r = requests.get(url) 14 15 r.raise_for_status() #如果状态不是200,则产生异常 16 17 r.encoding = r.apparent_encoding 18 19 return r.text 20 21 except: 22 23 return '产生异常' 24 25 26 27 if __name__ == '__main__': 28 29 url = 'https://www.hao123.com/' 30 31 soup = BeautifulSoup(getHTML_Text(url),'html.parser') 32 33 for link in soup.find_all('a'): 34 35 print(link.get('href'))

已经获取到所有<a>标签的url连接了,是不是很强大?
你问这个有什么用?啊哈?有什么用呢,下期继续讲。
今天到此结束,谢谢。