RDD基础概念:
RDD:弹性分布式数据集,逻辑上对数据划分,是不可变的,可分区的,供并行化计算的集合。具有以下特点:
1)RDD由逻辑上的分区组成,分区数据分布在各个节点,每个分区数据可以并行计算。
2)基于“lineage”的高效容错,即编号n的节点故障,可以从编号n-1的节点进行恢复。容错性还要考虑宽/窄依赖。
3)RDD数据在内存与磁盘之间的切换,数据的持久化与内存或者磁盘。checkpoint存储血缘关系
4)数据分片弹性,可以根据需要手动设置分区
RDD分区
1)RDD被划分成很多分区分布在集群中,分区数量决定了并行计算的粒度。
2)原文件是HDFS,RDD的分区数量与Block对应
3)RDD首选位置:考虑数据与计算的关系。如果RDD的分区首选位置是HDFS块所在的位置;当RDD被缓存时,计算会被发送到缓存所在的节点
RDD依赖关系
宽窄依赖是RDD操作的一种依赖关系,判断是否发生Shuffle的标志,划分stage的依据。
宽依赖(Shuffle Dependency):多个子RDD分区依赖一个父RDD分区,例如join操作。
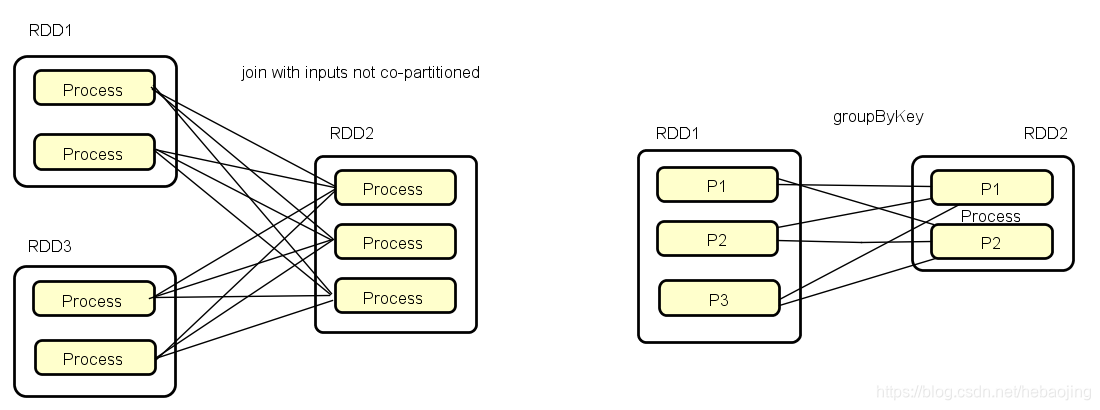
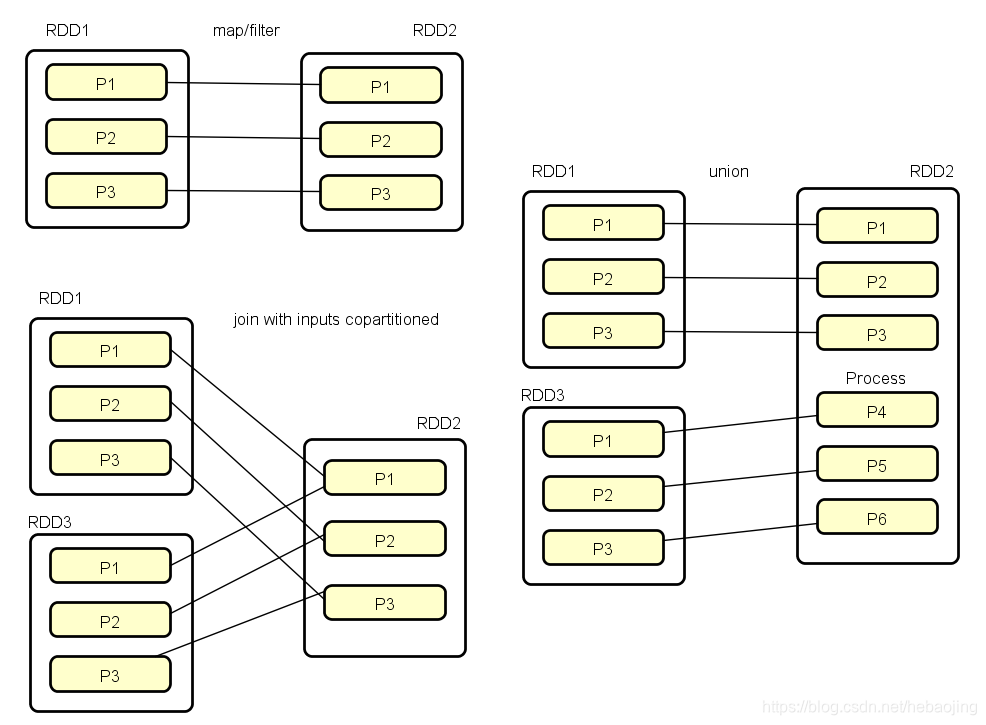
窄依赖(Narrow Dependency):每个父RDD分区最多只被一个子RDD分区依赖,例如map操作,父RDD已被hash策略划分过。
若是协同划分,两个父RDD之间,父RDD与子RDD之间形成的一致性分区安排,即同一个Key会被映射到同一分区,这就形成窄依赖。
| 窄依赖 | 宽依赖 | |
| 一般在同一节点完成 | 涉及Shuffle操作,涉及网络传输 | |
| 节点失败后的恢复更加高效,因为依赖是线性关系。 只需要计算丢失的父RDD,且这个计算过程可以并行 |
节点失败后的恢复更加耗时,依赖是一对多关系。 子RDD失败,可能导致其父RDD重新计算 |
解决的问题:并行迭代计算中进行数据共享。
RDD的操作:
1)创建RDD。来自外部数据或者集合;从其他RDD转换
2)转换操作。转换操作具有惰性,知道执行操作,才会触发真正的操作。从一个RDD转换成另一个RDD
3)行动操作。触发真正的执行操作。包含:foreach操作,将RDD转换成集合或者变量。
4)控制操作。对RDD做持久化,存于内存或者磁盘。
